Memory and CPU
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lab 7: Floating-Point Addition 0.0
Lab 7: Floating-Point Addition 0.0 Introduction In this lab, you will write a MIPS assembly language function that performs floating-point addition. You will then run your program using PCSpim (just as you did in Lab 6). For testing, you are provided a program that calls your function to compute the value of the mathematical constant e. For those with no assembly language experience, this will be a long lab, so plan your time accordingly. Background You should be familiar with the IEEE 754 Floating-Point Standard, which is described in Section 3.6 of your book. (Hopefully you have read that section carefully!) Here we will be dealing only with single precision floating- point values, which are formatted as follows (this is also described in the “Floating-Point Representation” subsec- tion of Section 3.6 in your book): Sign Exponent (8 bits) Significand (23 bits) 31 30 29 ... 24 23 22 21 ... 0 Remember that the exponent is biased by 127, which means that an exponent of zero is represented by 127 (01111111). The exponent is not encoded using 2s-complement. The significand is always positive, and the sign bit is kept separately. Note that the actual significand is 24 bits long; the first bit is always a 1 and thus does not need to be stored explicitly. This will be important to remember when you write your function! There are several details of IEEE 754 that you will not have to worry about in this lab. For example, the expo- nents 00000000 and 11111111 are reserved for special purposes that are described in your book (representing zero, denormalized numbers and NaNs). -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

The Hexadecimal Number System and Memory Addressing
C5537_App C_1107_03/16/2005 APPENDIX C The Hexadecimal Number System and Memory Addressing nderstanding the number system and the coding system that computers use to U store data and communicate with each other is fundamental to understanding how computers work. Early attempts to invent an electronic computing device met with disappointing results as long as inventors tried to use the decimal number sys- tem, with the digits 0–9. Then John Atanasoff proposed using a coding system that expressed everything in terms of different sequences of only two numerals: one repre- sented by the presence of a charge and one represented by the absence of a charge. The numbering system that can be supported by the expression of only two numerals is called base 2, or binary; it was invented by Ada Lovelace many years before, using the numerals 0 and 1. Under Atanasoff’s design, all numbers and other characters would be converted to this binary number system, and all storage, comparisons, and arithmetic would be done using it. Even today, this is one of the basic principles of computers. Every character or number entered into a computer is first converted into a series of 0s and 1s. Many coding schemes and techniques have been invented to manipulate these 0s and 1s, called bits for binary digits. The most widespread binary coding scheme for microcomputers, which is recog- nized as the microcomputer standard, is called ASCII (American Standard Code for Information Interchange). (Appendix B lists the binary code for the basic 127- character set.) In ASCII, each character is assigned an 8-bit code called a byte. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

POINTER (IN C/C++) What Is a Pointer?
POINTER (IN C/C++) What is a pointer? Variable in a program is something with a name, the value of which can vary. The way the compiler and linker handles this is that it assigns a specific block of memory within the computer to hold the value of that variable. • The left side is the value in memory. • The right side is the address of that memory Dereferencing: • int bar = *foo_ptr; • *foo_ptr = 42; // set foo to 42 which is also effect bar = 42 • To dereference ted, go to memory address of 1776, the value contain in that is 25 which is what we need. Differences between & and * & is the reference operator and can be read as "address of“ * is the dereference operator and can be read as "value pointed by" A variable referenced with & can be dereferenced with *. • Andy = 25; • Ted = &andy; All expressions below are true: • andy == 25 // true • &andy == 1776 // true • ted == 1776 // true • *ted == 25 // true How to declare pointer? • Type + “*” + name of variable. • Example: int * number; • char * c; • • number or c is a variable is called a pointer variable How to use pointer? • int foo; • int *foo_ptr = &foo; • foo_ptr is declared as a pointer to int. We have initialized it to point to foo. • foo occupies some memory. Its location in memory is called its address. &foo is the address of foo Assignment and pointer: • int *foo_pr = 5; // wrong • int foo = 5; • int *foo_pr = &foo; // correct way Change the pointer to the next memory block: • int foo = 5; • int *foo_pr = &foo; • foo_pr ++; Pointer arithmetics • char *mychar; // sizeof 1 byte • short *myshort; // sizeof 2 bytes • long *mylong; // sizeof 4 byts • mychar++; // increase by 1 byte • myshort++; // increase by 2 bytes • mylong++; // increase by 4 bytes Increase pointer is different from increase the dereference • *P++; // unary operation: go to the address of the pointer then increase its address and return a value • (*P)++; // get the value from the address of p then increase the value by 1 Arrays: • int array[] = {45,46,47}; • we can call the first element in the array by saying: *array or array[0]. -
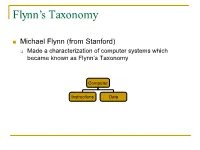
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -
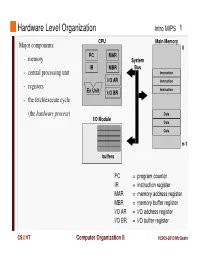
Instruction Register MAR = Memory Address Register MBR = Memory Buffer Register I/O AR = I/O Address Register I/O BR = I/O Buffer Register
Hardware Level Organization Intro MIPS 1 CPU Main Memory Major components: 0 PC MAR - memory System IR MBR Bus - central processing unit Instruction I/O AR Instruction - registers Instruction Ex Unit I/O BR - the fetch/execute cycle (the hardware process ) Data I/O Module Data Data n-1 buffers PC = program counter IR = instruction register MAR = memory address register MBR = memory buffer register I/O AR = I/O address register I/O BR = I/O buffer register CS @VT Computer Organization II ©2005-2013 McQuain Central Processing Unit Intro MIPS 2 Control - decodes instructions and manages CPU’s internal resources Registers - general-purpose registers available to user processes - special-purpose registers directly managed in fetch/execute cycle - other registers may be reserved for use of operating system - very fast and expensive (relative to memory) - hold all operands and results of arithmetic instructions (on RISC systems) - save bits in instruction representation Data path or arithmetic/logic unit (ALU) - operates on data CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 3 Instructions are collections of bits Programs are stored in memory, to be read or written just like data Main Memory CPU 0 memory for data, programs, PC MAR compilers, editors, etc. Instruction IR MBR Instruction I/O AR Instruction Ex Unit I/O BR Data Data Data n-1 Fetch & Execute Cycle Instructions are fetched and put into a special register Bits in the register "control" the subsequent actions Fetch the “next” instruction and continue CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 4 Of course, on most systems several programs will be stored in memory at any given time. -

Please Replace the Following Pages in the Book. 26 Microcontroller Theory and Applications with the PIC18F
Please replace the following pages in the book. 26 Microcontroller Theory and Applications with the PIC18F Before Push After Push Stack Stack 16-bit Register 0120 143E 20C2 16-bit Register 0120 SP 20CA SP 20C8 143E 20C2 0703 20C4 0703 20C4 F601 20C6 F601 20C6 0706 20C8 0706 20C8 0120 20CA 20CA 20CC 20CC 20CE 20CE Bottom of Stack FIGURE 2.12 PUSH operation when accessing a stack from the bottom Before POP After POP Stack 16-bit Register A286 16-bit Register 0360 Stack 143E 20C2 SP 20C8 SP 20CA 143E 20C2 0705 20C4 0705 20C4 F208 20C6 F208 20C6 0107 20C8 0107 20C8 A286 20CA A286 20CA 20CC 20CC Bottom of Stack FIGURE 2.13 POP operation when accessing a stack from the bottom Note that the stack is a LIFO (last in, first out) memory. As mentioned earlier, a stack is typically used during subroutine CALLs. The CPU automatically PUSHes the return address onto a stack after executing a subroutine CALL instruction in the main program. After executing a RETURN from a subroutine instruction (placed by the programmer as the last instruction of the subroutine), the CPU automatically POPs the return address from the stack (previously PUSHed) and then returns control to the main program. Note that the PIC18F accesses the stack from the top. This means that the stack pointer in the PIC18F holds the address of the bottom of the stack. Hence, in the PIC18F, the stack pointer is incremented after a PUSH, and decremented after a POP. 2.3.2 Control Unit The main purpose of the control unit is to read and decode instructions from the program memory. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

Intel® 4 Series Chipset Family Datasheet
Intel® 4 Series Chipset Family Datasheet For the Intel® 82Q45, 82Q43, 82B43, 82G45, 82G43, 82G41 Graphics and Memory Controller Hub (GMCH) and the Intel® 82P45, 82P43 Memory Controller Hub (MCH) March 2010 Document Number: 319970-007 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® 4 Series Chipset family may contain design defects or errors known as errata, which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. I2C is a two-wire communications bus/protocol developed by Philips. -

Subtyping Recursive Types
ACM Transactions on Programming Languages and Systems, 15(4), pp. 575-631, 1993. Subtyping Recursive Types Roberto M. Amadio1 Luca Cardelli CNRS-CRIN, Nancy DEC, Systems Research Center Abstract We investigate the interactions of subtyping and recursive types, in a simply typed λ-calculus. The two fundamental questions here are whether two (recursive) types are in the subtype relation, and whether a term has a type. To address the first question, we relate various definitions of type equivalence and subtyping that are induced by a model, an ordering on infinite trees, an algorithm, and a set of type rules. We show soundness and completeness between the rules, the algorithm, and the tree semantics. We also prove soundness and a restricted form of completeness for the model. To address the second question, we show that to every pair of types in the subtype relation we can associate a term whose denotation is the uniquely determined coercion map between the two types. Moreover, we derive an algorithm that, when given a term with implicit coercions, can infer its least type whenever possible. 1This author's work has been supported in part by Digital Equipment Corporation and in part by the Stanford-CNR Collaboration Project. Page 1 Contents 1. Introduction 1.1 Types 1.2 Subtypes 1.3 Equality of Recursive Types 1.4 Subtyping of Recursive Types 1.5 Algorithm outline 1.6 Formal development 2. A Simply Typed λ-calculus with Recursive Types 2.1 Types 2.2 Terms 2.3 Equations 3. Tree Ordering 3.1 Subtyping Non-recursive Types 3.2 Folding and Unfolding 3.3 Tree Expansion 3.4 Finite Approximations 4.