Chapter 2 Computer Systems Organization – PART I • Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
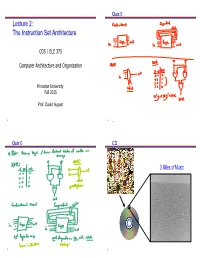
The Instruction Set Architecture
Quiz 0 Lecture 2: The Instruction Set Architecture COS / ELE 375 Computer Architecture and Organization Princeton University Fall 2015 Prof. David August 1 2 Quiz 0 CD 3 Miles of Music 3 4 Pits and Lands Interpretation 0 1 1 1 0 1 0 1 As Music: 011101012 = 117/256 position of speaker As Number: Transition represents a bit state (1/on/red/female/heads) 01110101 = 1 + 4 + 16 + 32 + 64 = 117 = 75 No change represents other state (0/off/white/male/tails) 2 10 16 (Get comfortable with base 2, 8, 10, and 16.) As Text: th 011101012 = 117 character in the ASCII codes = “u” 5 6 Interpretation – ASCII Princeton Computer Science Building West Wall 7 8 Interpretation Binary Code and Data (Hello World!) • Programs consist of Code and Data • Code and Data are Encoded in Bits IA-64 Binary (objdump) As Music: 011101012 = 117/256 position of speaker As Number: 011101012 = 1 + 4 + 16 + 32 + 64 = 11710 = 7516 As Text: th 011101012 = 117 character in the ASCII codes = “u” CAN ALSO BE INTERPRETED AS MACHINE INSTRUCTION! 9 Interfaces in Computer Systems Instructions Sequential Circuit!! Software: Produce Bits Instructing Machine to Manipulate State or Produce I/O Computers process information State Applications • Input/Output (I/O) Operating System • State (memory) • Computation (processor) Compiler Firmware Instruction Set Architecture Input Output Instruction Set Processor I/O System Datapath & Control Computation Digital Design Circuit Design • Instructions instruct processor to manipulate state Layout • Instructions instruct processor to produce I/O in the same way Hardware: Read and Obey Instruction Bits 12 State State – Main Memory Typical modern machine has this architectural state: Main Memory (AKA: RAM – Random Access Memory) 1. -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

Simple Computer Example Register Structure
Simple Computer Example Register Structure Read pp. 27-85 Simple Computer • To illustrate how a computer operates, let us look at the design of a very simple computer • Specifications 1. Memory words are 16 bits in length 2. 2 12 = 4 K words of memory 3. Memory can be accessed in one clock cycle 4. Single Accumulator for ALU (AC) 5. Registers are fully connected Simple Computer Continued 4K x 16 Memory MAR 12 MDR 16 X PC 12 ALU IR 16 AC Simple Computer Specifications (continued) 6. Control signals • INCPC – causes PC to increment on clock edge - [PC] +1 PC •ACin - causes output of ALU to be stored in AC • GMDR2X – get memory data register to X - [MDR] X • Read (Write) – Read (Write) contents of memory location whose address is in MAR To implement instructions, control unit must break down the instruction into a series of register transfers (just like a complier must break down C program into a series of machine level instructions) Simple Computer (continued) • Typical microinstruction for reading memory State Register Transfer Control Line(s) Next State 1 [[MAR]] MDR Read 2 • Timing State 1 State 2 During State 1, Read set by control unit CLK - Data is read from memory - MDR changes at the Read beginning of State 2 - Read is completed in one clock cycle MDR Simple Computer (continued) • Study: how to write the microinstructions to implement 3 instructions • ADD address • ADD (address) • JMP address ADD address: add using direct addressing 0000 address [AC] + [address] AC ADD (address): add using indirect addressing 0001 address [AC] + [[address]] AC JMP address 0010 address address PC Instruction Format for Simple Computer IR OP 4 AD 12 AD = address - Two phases to implement instructions: 1. -

PIC Family Microcontroller Lesson 02
Chapter 13 PIC Family Microcontroller Lesson 02 Architecture of PIC 16F877 Internal hardware for the operations in a PIC family MCU direct Internal ID, control, sequencing and reset circuits address 7 14-bit Instruction register 8 MUX program File bus Select 8 Register 14 8 8 W Register (Accumulator) ADDR Status Register MUX Flash Z, C and DC 9 Memory Data Internal EEPROM RAM 13 Peripherals 256 Byte Program Registers counter Ports data 368 Byte 13 bus 2011 Microcontrollers-... 2nd Ed. Raj KamalA to E 3 8-level stack (13-bit) Pearson Education 8 ALU Features • Supports 8-bit operations • Internal data bus is of 8-bits 2011 Microcontrollers-... 2nd Ed. Raj Kamal 4 Pearson Education ALU Features • ALU operations between the Working (W) register (accumulator) and register (or internal RAM) from a register-file • ALU operations can also be between the W and 8-bits operand from instruction register (IR) • The operations also use three flags Z, C and DC/borrow. [Zero flag, Carry flag and digit (nibble) carry flag] 2011 Microcontrollers-... 2nd Ed. Raj Kamal 5 Pearson Education ALU features • The destination of result from ALU operations can be either W or register (f) in file • The flags save at status register (STATUS) • PIC CPU is a one-address machine (one operand specified in the instruction for ALU) 2011 Microcontrollers-... 2nd Ed. Raj Kamal 6 Pearson Education ALU features • Two operands are used in an arithmetic or logic operations • One is source operand from one a register file/RAM (or operand from instruction) and another is W-register • Advantage—ALU directly operates on a register or memory similar to 8086 CPU 2011 Microcontrollers-.. -

A Simple Processor
CS 240251 SpringFall 2019 2020 FoundationsPrinciples of Programming of Computer Languages Systems λ Ben Wood A Simple Processor 1. A simple Instruction Set Architecture 2. A simple microarchitecture (implementation): Data Path and Control Logic https://cs.wellesley.edu/~cs240/s20/ A Simple Processor 1 Program, Application Programming Language Compiler/Interpreter Software Operating System Instruction Set Architecture Microarchitecture Digital Logic Devices (transistors, etc.) Hardware Solid-State Physics A Simple Processor 2 Instruction Set Architecture (HW/SW Interface) processor memory Instructions • Names, Encodings Instruction Encoded • Effects Logic Instructions • Arguments, Results Registers Data Local storage • Names, Size • How many Large storage • Addresses, Locations Computer A Simple Processor 3 Computer Microarchitecture (Implementation of ISA) Instruction Fetch and Registers ALU Memory Decode A Simple Processor 4 (HW = Hardware or Hogwarts?) HW ISA An example made-up instruction set architecture Word size = 16 bits • Register size = 16 bits. • ALU computes on 16-bit values. Memory is byte-addressable, accesses full words (byte pairs). 16 registers: R0 - R15 • R0 always holds hardcoded 0 Address Contents • R1 always holds hardcoded 1 0 First instruction, low-order byte • R2 – R15: general purpose 1 First instruction, Instructions are 1 word in size. high-order byte 2 Second instruction, Separate instruction memory. low-order byte Program Counter (PC) register ... ... • holds address of next instruction to execute. A Simple Processor 5 R: Register File M: Data Memory Reg Contents Reg Contents Address Contents R0 0x0000 R8 0x0 – 0x1 R1 0x0001 R9 0x2 – 0x3 R2 R10 0x4 – 0x5 R3 R11 0x6 – 0x7 R4 R12 0x8 – 0x9 R5 R13 0xA – 0xB R6 R14 0xC – 0xD R7 R15 … Program Counter IM: Instruction Memory PC Address Contents 0x0 – 0x1 ß Processor 1. -
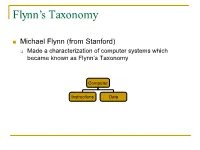
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

MIPS: Design and Implementation
FACULTEIT INGENIEURSWETENSCHAPPEN MIPS: Design and Implementation Computerarchitectuur 1MA Industriele¨ Wetenschappen Elektronica-ICT 2014-10-20 Laurent Segers Contents Introduction......................................3 1 From design to VHDL4 1.1 The factorial algorithm.............................4 1.2 Building modules................................5 1.2.1 A closer look..............................6 1.2.2 VHDL..................................7 1.3 Design in VHDL................................8 1.3.1 Program Counter............................8 1.3.2 Instruction Memory........................... 14 1.3.3 Program Counter Adder........................ 15 1.4 Bringing it all together - towards the MIPS processor............ 15 2 Design validation 19 2.1 Instruction Memory............................... 19 2.2 Program Counter................................ 22 2.3 Program Counter Adder............................ 23 2.4 The MIPS processor.............................. 23 3 Porting to FPGA 25 3.1 User Constraints File.............................. 25 4 Additional features 27 4.1 UART module.................................. 27 4.1.1 Connecting the UART-module to the MIPS processor........ 28 4.2 Reprogramming the MIPS processor..................... 29 A Xilinx ISE software 30 A.1 Creating a new project............................. 30 A.2 Adding a new VHDL-module......................... 30 A.3 Creating an User Constraints File....................... 30 A.4 Testbenches................................... 31 A.4.1 Creating testbenches.......................... 31 A.4.2 Running testbenches.......................... 31 2 Introduction Nowadays, most programmers write their applications in what we call \the Higher Level Programming languages", such as Java, C#, Delphi, etc. These applications are then compiled into machine code. In order to run this machine code the underlying hardware needs be able to \understand" the proposed code. The aim of this practical course is to give an inside on the principles of a working system. -

Overview of the MIPS Architecture: Part I
Overview of the MIPS Architecture: Part I CS 161: Lecture 0 1/24/17 Looking Behind the Curtain of Software • The OS sits between hardware and user-level software, providing: • Isolation (e.g., to give each process a separate memory region) • Fairness (e.g., via CPU scheduling) • Higher-level abstractions for low-level resources like IO devices • To really understand how software works, you have to understand how the hardware works! • Despite OS abstractions, low-level hardware behavior is often still visible to user-level applications • Ex: Disk thrashing Processors: From the View of a Terrible Programmer Letter “m” Drawing of bird ANSWERS Source code Compilation add t0, t1, t2 lw t3, 16(t0) slt t0, t1, 0x6eb21 Machine instructions A HARDWARE MAGIC OCCURS Processors: From the View of a Mediocre Programmer • Program instructions live Registers in RAM • PC register points to the memory address of the instruction to fetch and execute next • Arithmetic logic unit (ALU) performs operations on PC registers, writes new RAM values to registers or Instruction memory, generates ALU to execute outputs which determine whether to branches should be taken • Some instructions cause Devices devices to perform actions Processors: From the View of a Mediocre Programmer • Registers versus RAM Registers • Registers are orders of magnitude faster for ALU to access (0.3ns versus 120ns) • RAM is orders of magnitude larger (a PC few dozen 32-bit or RAM 64-bit registers versus Instruction GBs of RAM) ALU to execute Devices Instruction Set Architectures (ISAs) -
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK -

Computer Architectures
Parallel (High-Performance) Computer Architectures Tarek El-Ghazawi Department of Electrical and Computer Engineering The George Washington University Tarek El-Ghazawi, Introduction to High-Performance Computing slide 1 Introduction to Parallel Computing Systems Outline Definitions and Conceptual Classifications » Parallel Processing, MPP’s, and Related Terms » Flynn’s Classification of Computer Architectures Operational Models for Parallel Computers Interconnection Networks MPP’s Performance Tarek El-Ghazawi, Introduction to High-Performance Computing slide 2 Definitions and Conceptual Classification What is Parallel Processing? - A form of data processing which emphasizes the exploration and exploitation of inherent parallelism in the underlying problem. Other related terms » Massively Parallel Processors » Heterogeneous Processing – In the1990s, heterogeneous workstations from different processor vendors – Now, accelerators such as GPUs, FPGAs, Intel’s Xeon Phi, … » Grid computing » Cloud Computing Tarek El-Ghazawi, Introduction to High-Performance Computing slide 3 Definitions and Conceptual Classification Why Massively Parallel Processors (MPPs)? » Increase processing speed and memory allowing studies of problems with higher resolutions or bigger sizes » Provide a low cost alternative to using expensive processor and memory technologies (as in traditional vector machines) Tarek El-Ghazawi, Introduction to High-Performance Computing slide 4 Stored Program Computer The IAS machine was the first electronic computer developed, under