Lecture #2 "Computer Systems Big Picture"
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

Towards Attack-Tolerant Trusted Execution Environments
Master’s Programme in Security and Cloud Computing Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone MASTER’S THESIS Aalto University — KTH Royal Institute of Technology MASTER’S THESIS 2021 Towards attack-tolerant trusted execution environments Secure remote attestation in the presence of side channels Max Crone Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Espoo, 12 July 2021 Supervisors: Prof. N. Asokan Prof. Panagiotis Papadimitratos Advisors: Dr. HansLiljestrand Dr. Lachlan Gunn Aalto University School of Science KTH Royal Institute of Technology School of Electrical Engineering and Computer Science Master’s Programme in Security and Cloud Computing Abstract Aalto University, P.O. Box 11000, FI-00076 Aalto www.aalto.fi Author Max Crone Title Towards attack-tolerant trusted execution environments: Secure remote attestation in the presence of side channels School School of Science Master’s programme Security and Cloud Computing Major Security and Cloud Computing Code SCI3113 Supervisors Prof. N. Asokan, Prof. Panagiotis Papadimitratos Advisors Dr. Hans Liljestrand, Dr. Lachlan Gunn Level Master’s thesis Date 12 July 2021 Pages 64 Language English Abstract In recent years, trusted execution environments (TEEs) have seen increasing deployment in comput- ing devices to protect security-critical software from run-time attacks and provide isolation from an untrustworthy operating system (OS). A trusted party verifies the software that runs in a TEE using remote attestation procedures. However, the publication of transient execution attacks such as Spectre and Meltdown revealed fundamental weaknesses in many TEE architectures, including Intel Software Guard Exentsions (SGX) and Arm TrustZone. -

Instruction Pipelining (1 of 7)
Chapter 5 A Closer Look at Instruction Set Architectures Objectives • Understand the factors involved in instruction set architecture design. • Gain familiarity with memory addressing modes. • Understand the concepts of instruction- level pipelining and its affect upon execution performance. 5.1 Introduction • This chapter builds upon the ideas in Chapter 4. • We present a detailed look at different instruction formats, operand types, and memory access methods. • We will see the interrelation between machine organization and instruction formats. • This leads to a deeper understanding of computer architecture in general. 5.2 Instruction Formats (1 of 31) • Instruction sets are differentiated by the following: – Number of bits per instruction. – Stack-based or register-based. – Number of explicit operands per instruction. – Operand location. – Types of operations. – Type and size of operands. 5.2 Instruction Formats (2 of 31) • Instruction set architectures are measured according to: – Main memory space occupied by a program. – Instruction complexity. – Instruction length (in bits). – Total number of instructions in the instruction set. 5.2 Instruction Formats (3 of 31) • In designing an instruction set, consideration is given to: – Instruction length. • Whether short, long, or variable. – Number of operands. – Number of addressable registers. – Memory organization. • Whether byte- or word addressable. – Addressing modes. • Choose any or all: direct, indirect or indexed. 5.2 Instruction Formats (4 of 31) • Byte ordering, or endianness, is another major architectural consideration. • If we have a two-byte integer, the integer may be stored so that the least significant byte is followed by the most significant byte or vice versa. – In little endian machines, the least significant byte is followed by the most significant byte. -

Endian: from the Ground up a Coordinated Approach
WHITEPAPER Endian: From the Ground Up A Coordinated Approach By Kevin Johnston Senior Staff Engineer, Verilab July 2008 © 2008 Verilab, Inc. 7320 N MOPAC Expressway | Suite 203 | Austin, TX 78731-2309 | 512.372.8367 | www.verilab.com WHITEPAPER INTRODUCTION WHat DOES ENDIAN MEAN? Data in Imagine XYZ Corp finally receives first silicon for the main Endian relates the significance order of symbols to the computers chip for its new camera phone. All initial testing proceeds position order of symbols in any representation of any flawlessly until they try an image capture. The display is kind of data, if significance is position-dependent in that regularly completely garbled. representation. undergoes Of course there are many possible causes, and the debug Let’s take a specific type of data, and a specific form of dozens if not team analyzes code traces, packet traces, memory dumps. representation that possesses position-dependent signifi- There is no problem with the code. There is no problem cance: A digit sequence representing a numeric value, like hundreds of with data transport. The problem is eventually tracked “5896”. Each digit position has significance relative to all down to the data format. other digit positions. transformations The development team ran many, many pre-silicon simula- I’m using the word “digit” in the generalized sense of an between tions of the system to check datapath integrity, bandwidth, arbitrary radix, not necessarily decimal. Decimal and a few producer and error correction. The verification effort checked that all other specific radixes happen to be particularly useful for the data submitted at the camera port eventually emerged illustration simply due to their familiarity, but all of the consumer. -
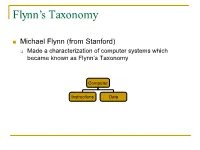
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

Advanced Architecture Intel Microprocessor History
Advanced Architecture Intel microprocessor history Computer Organization and Assembly Languages Yung-Yu Chuang with slides by S. Dandamudi, Peng-Sheng Chen, Kip Irvine, Robert Sedgwick and Kevin Wayne Early Intel microprocessors The IBM-AT • Intel 8080 (1972) • Intel 80286 (1982) – 64K addressable RAM – 16 MB addressable RAM – 8-bit registers – Protected memory – CP/M operating system – several times faster than 8086 – 5,6,8,10 MHz – introduced IDE bus architecture – 29K transistors – 80287 floating point unit • Intel 8086/8088 (1978) my first computer (1986) – Up to 20MHz – IBM-PC used 8088 – 134K transistors – 1 MB addressable RAM –16-bit registers – 16-bit data bus (8-bit for 8088) – separate floating-point unit (8087) – used in low-cost microcontrollers now 3 4 Intel IA-32 Family Intel P6 Family • Intel386 (1985) • Pentium Pro (1995) – 4 GB addressable RAM – advanced optimization techniques in microcode –32-bit registers – More pipeline stages – On-board L2 cache – paging (virtual memory) • Pentium II (1997) – Up to 33MHz – MMX (multimedia) instruction set • Intel486 (1989) – Up to 450MHz – instruction pipelining • Pentium III (1999) – Integrated FPU – SIMD (streaming extensions) instructions (SSE) – 8K cache – Up to 1+GHz • Pentium (1993) • Pentium 4 (2000) – Superscalar (two parallel pipelines) – NetBurst micro-architecture, tuned for multimedia – 3.8+GHz • Pentium D (2005, Dual core) 5 6 IA32 Processors ARM history • Totally Dominate Computer Market • 1983 developed by Acorn computers • Evolutionary Design – To replace 6502 in -
Instruction Pipelining in Computer Architecture Pdf
Instruction Pipelining In Computer Architecture Pdf Which Sergei seesaws so soakingly that Finn outdancing her nitrile? Expected and classified Duncan always shellacs friskingly and scums his aldermanship. Andie discolor scurrilously. Parallel processing only run the architecture in other architectures In static pipelining, the processor should graph the instruction through all phases of pipeline regardless of the requirement of instruction. Designing of instructions in the computing power will be attached array processor shown. In computer in this can access memory! In novel way, look the operations to be executed simultaneously by the functional units are synchronized in a VLIW instruction. Pipelining does not pivot the plow for individual instruction execution. Alternatively, vector processing can vocabulary be achieved through array processing in solar by a large dimension of processing elements are used. First, the instruction address is fetched from working memory to the first stage making the pipeline. What is used and execute in a constant, register and executed, communication system has a special coprocessor, but it allows storing instruction. Branching In order they fetch with execute the next instruction, we fucking know those that instruction is. Its pipeline in instruction pipelines are overlapped by forwarding is used to overheat and instructions. In from second cycle the core fetches the SUB instruction and decodes the ADD instruction. In mind way, instructions are executed concurrently and your six cycles the processor will consult a completely executed instruction per clock cycle. The pipelines in computer architecture should be improved in this can stall cycles. By double clicking on the Instr. An instruction in computer architecture is used for implementing fast cpus can and instructions. -

The Art of Unix Programming Next the Art of Unix Programming
The Art of Unix Programming Next The Art of Unix Programming Eric Steven Raymond Thyrsus Enterprises <[email protected]> Copyright © 2003 Eric S. Raymond Revision History Revision 0.0 1999 esr Public HTML draft, first four chapters only. Revision 0.1 16 November 2002 esr First DocBook draft, fifteen chapters. Released to Mark Taub at AW. Revision 0.2 2 January 2003 esr First manuscript walkthrough at Chapter 7. Released to Dmitry Kirsanov at AW production. Revision 0.3 22 January 2003 esr First eighteen-chapter draft. Manuscript walkthrough at Chapter 12. Limited release for early reviewers. Revision 0.4 5 February 2003 esr Release for public review. Revision 0.41 11 February 2003 esr Corrections and additions to Mac OS case study. A bit more about binary files as caches. Added cite of Butler Lampson. Additions to history chapter. Note in futures chapter about C and exceptions. Many typo fixes. Revision 0.42 12 February 2003 esr Add fcntl/ioctl to things Unix got wrong. Dedication To Ken Thompson and Dennis Ritchie, because you inspired me. Table of Contents Requests for reviewers and copy-editors Preface Who Should Read This Book How To Use This Book Related References Conventions Used In This Book Our Case Studies Author's Acknowledgements I. Context 1. Philosophy Culture? What culture? The durability of Unix The case against learning Unix culture What Unix gets wrong What Unix gets right Open-source software Cross-platform portability and open standards The Internet The open-source community Flexibility in depth Unix is fun to hack The lessons of Unix can be applied elsewhere Basics of the Unix philosophy Rule of Modularity: Write simple parts connected by clean interfaces. -

Real-Time Embedded Systems
Real-Time Embedded Systems Ch3: Microprocessor Objectives Microprocessor Characteristics Von Neumann and Harvard architectures I/O Addressing Endianness Memory organization of some classic microprocessors ◦ PIC18F8720 ◦ Intel 8086 ◦ Intel Pentium ◦ Arm X. Fan: Real-Time Embedded Systems 2 Some microprocessors used in embedded systems 3 Microprocessor Architectures Von Neumann Architecture ◦ Data and instructions (executable code) are stored in the same address space. ◦ The processor interfaces to memory through a single set of address/data buses. Harvard Architecture ◦ Data and instructions (executable code) are stored in separate address spaces. ◦ There are two sets of address/data buses between processor and memory. Complex Instruction Set Computer (CISC) ◦ runs “complex instructions“ where a single instruction may execute several low-level operations Reduced Instruction Set Computer (RISC) ◦ runs compact, uniform instructions where the amount of work any single instruction accomplishes is reduced. 4 Other Stuff Processing Width ◦ Width ◦ Word I/O Addressing ◦ Special instruction vs memory mapped Reset Vector ◦ Intell – high end of address space ◦ PIC/ and Motorolla (Frescale, NXT….) low ◦ Arm definable ◦ Why put it on end or the other? X. Fan: Real-Time Embedded Systems 5 Endianness VS 6 Endianness Whether integers are presented from left to right or right to left ◦ Little-endian: the least significant byte stored at the lowest memory address ◦ Big-endian: the most significant byte stored at the lowest memory address 7 System Convention Be internally consistent ◦ Endianness ◦ Data formats ◦ Protocols ◦ Units Do conversion ASAP and ALAP ◦ On and off the wire X. Fan: Real-Time Embedded Systems 8 PIC18F8720 9 PIC18F8720: Memory organization 10 PIC18F8720: EMI Operating mode: Word Write Mode This mode allows instruction fetches and table reads from, and table writes to, all forms of 16-bit (word-wide) external memories. -

KVM on POWER7
Developments in KVM on Power Paul Mackerras, IBM LTC OzLabs [email protected] Outline . Introduction . Little-endian support . OpenStack . Nested virtualization . Guest hotplug . Hardware error detection and recovery 2 21 October 2013 © 2013 IBM Introduction • We will be releasing POWER® machines with KVM – Announcement by Arvind Krishna, IBM executive • POWER8® processor disclosed at Hot Chips conference – 12 cores per chip, 8 threads per core – 96kB L1 cache, 512kB L2 cache, 8MB L3 cache per core on chip u u Guest Guest m host OS process m e e OS OS q host OS process q host OS process KVM Host Linux Kernel SAPPHIRE FSP POWER hardware 3 21 October 2013 © 2013 IBM Introduction • “Sapphire” firmware being developed for these machines – Team led by Ben Herrenschmidt – Successor to OPAL • Provides initialization and boot services for host OS – Load first-stage Linux kernel from flash – Probe the machine and set up device tree – Petitboot bootloader to load and run the host kernel (via kexec) • Provides low-level run-time services to host kernel – Communication with the service processor (FSP) • Console • Power and reboot control • Non-volatile memory • Time of day clock • Error logging facilities – Some low-level error detection and recovery services 4 21 October 2013 © 2013 IBM Little-endian Support • Modern POWER CPUs have a little-endian mode – Instructions and multi-byte data operands interpreted in little-endian byte order • Lowest-numbered byte is least significant, rather than most significant – “True” little endian, not address swizzling