Computer Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -
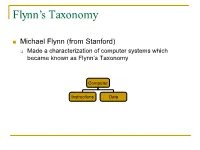
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

Cluster, Grid and Cloud Computing: a Detailed Comparison
The 6th International Conference on Computer Science & Education (ICCSE 2011) August 3-5, 2011. SuperStar Virgo, Singapore ThC 3.33 Cluster, Grid and Cloud Computing: A Detailed Comparison Naidila Sadashiv S. M Dilip Kumar Dept. of Computer Science and Engineering Dept. of Computer Science and Engineering Acharya Institute of Technology University Visvesvaraya College of Engineering (UVCE) Bangalore, India Bangalore, India [email protected] [email protected] Abstract—Cloud computing is rapidly growing as an alterna- with out any prior reservation and hence eliminates over- tive to conventional computing. However, it is based on models provisioning and improves resource utilization. like cluster computing, distributed computing, utility computing To the best of our knowledge, in the literature, only a few and grid computing in general. This paper presents an end-to- end comparison between Cluster Computing, Grid Computing comparisons have been appeared in the field of computing. and Cloud Computing, along with the challenges they face. This In this paper we bring out a complete comparison of the could help in better understanding these models and to know three computing models. Rest of the paper is organized as how they differ from its related concepts, all in one go. It also follows. The cluster computing, grid computing and cloud discusses the ongoing projects and different applications that use computing models are briefly explained in Section II. Issues these computing models as a platform for execution. An insight into some of the tools which can be used in the three computing and challenges related to these computing models are listed models to design and develop applications is given. -

Grid Computing: What Is It, and Why Do I Care?*
Grid Computing: What Is It, and Why Do I Care?* Ken MacInnis <[email protected]> * Or, “Mi caja es su caja!” (c) Ken MacInnis 2004 1 Outline Introduction and Motivation Examples Architecture, Components, Tools Lessons Learned and The Future Questions? (c) Ken MacInnis 2004 2 What is “grid computing”? Many different definitions: Utility computing Cycles for sale Distributed computing distributed.net RC5, SETI@Home High-performance resource sharing Clusters, storage, visualization, networking “We will probably see the spread of ‘computer utilities’, which, like present electric and telephone utilities, will service individual homes and offices across the country.” Len Kleinrock (1969) The word “grid” doesn’t equal Grid Computing: Sun Grid Engine is a mere scheduler! (c) Ken MacInnis 2004 3 Better definitions: Common protocols allowing large problems to be solved in a distributed multi-resource multi-user environment. “A computational grid is a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to high-end computational capabilities.” Kesselman & Foster (1998) “…coordinated resource sharing and problem solving in dynamic, multi- institutional virtual organizations.” Kesselman, Foster, Tuecke (2000) (c) Ken MacInnis 2004 4 New Challenges for Computing Grid computing evolved out of a need to share resources Flexible, ever-changing “virtual organizations” High-energy physics, astronomy, more Differing site policies with common needs Disparate computing needs -

Cloud Computing Over Cluster, Grid Computing: a Comparative Analysis
Journal of Grid and Distributed Computing Volume 1, Issue 1, 2011, pp-01-04 Available online at: http://www.bioinfo.in/contents.php?id=92 Cloud Computing Over Cluster, Grid Computing: a Comparative Analysis 1Indu Gandotra, 2Pawanesh Abrol, 3 Pooja Gupta, 3Rohit Uppal and 3Sandeep Singh 1Department of MCA, MIET, Jammu 2Department of Computer Science & IT, Jammu Univ, Jammu 3Department of MCA, MIET, Jammu e-mail: [email protected], [email protected], [email protected], [email protected], [email protected] Abstract—There are dozens of definitions for cloud Virtualization is a technology that enables sharing of computing and through each definition we can get the cloud resources. Cloud computing platform can become different idea about what a cloud computing exacting is? more flexible, extensible and reusable by adopting the Cloud computing is not a very new concept because it is concept of service oriented architecture [5].We will not connected to grid computing paradigm whose concept came need to unwrap the shrink wrapped software and install. into existence thirteen years ago. Cloud computing is not only related to Grid Computing but also to Utility computing The cloud is really very easier, just to install single as well as Cluster computing. Cloud computing is a software in the centralized facility and cover all the computing platform for sharing resources that include requirements of the company’s users [1]. software’s, business process, infrastructures and applications. Cloud computing also relies on the technology II. CLUSTER COMPUTING of virtualization. In this paper, we will discuss about Grid computing, Cluster computing and Cloud computing i.e. -

“Grid Computing”
VISHVESHWARAIAH TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY A seminar report on “Grid Computing” Submitted by Nagaraj Baddi (2SD07CS402) 8th semester DEPARTMENT OF COMPUTER SCIENCE ENGINEERING 2009-10 1 VISHVESHWARAIAH TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE ENGINEERING CERTIFICATE Certified that the seminar work entitled “Grid Computing” is a bonafide work presented by Mr. Nagaraj.M.Baddi, bearing USN 2SD07CS402 in a partial fulfillment for the award of degree of Bachelor of Engineering in Computer Science Engineering of the Vishveshwaraiah Technological University Belgaum, during the year 2009-10. The seminar report has been approved as it satisfies the academic requirements with respect to seminar work presented for the Bachelor of Engineering Degree. Staff in charge H.O.D CSE (S. L. DESHPANDE) (S. M. JOSHI) Name: Nagaraj M. Baddi USN: 2SD07CS402 2 INDEX 1. Introduction 4 2. History 5 3. How Grid Computing Works 6 4. Related technologies 8 4.1 Cluster computing 8 4.2 Peer-to-peer computing 9 4.3 Internet computing 9 5. Grid Computing Logical Levels 10 5.1 Cluster Grid 10 5.2 Campus Grid 10 5.3 Global Grid 10 6. Grid Architecture 11 6.1 Grid fabric 11 6.2 Core Grid middleware 12 6.3 User-level Grid middleware 12 6.4 Grid applications and portals. 13 7. Grid Applications 13 7.1 Distributed supercomputing 13 7.2 High-throughput computing 14 7.3 On-demand computing 14 7.4 Data-intensive computing 14 7.5 Collaborative computing 15 8. Difference: Grid Computing vs Cloud Computing 15 9. -

ECE 590: Digital Systems Design Using Hardware Description Language (VHDL) Systolic Implementation of Faddeev's Algorithm in V
Project Report ECE 590: Digital Systems Design using Hardware Description Language (VHDL) Systolic Implementation of Faddeev’s Algorithm in VHDL. Final Project Tejas Tapsale. PSU ID: 973524088. Project Report Introduction: = In this project we are implementing Nash’s systolic implementation and Chuang an He,s systolic implementation for Faddeev’s algorithm. These two implementations have their own advantages and drawbacks. Here in this project report we first see detail of Nash implementation and then we will go for Chaung and He’s implementation. The organization of this report is like this:- 1. First we take detail idea about what is systolic architecture and how it can be used for matrix multiplication and its advantages and disadvantages. 2. Then we discuss about Gaussian Elimination for matrix computation and its properties. 3. Then we will see Faddeev’s algorithm and how it is used. 4. Systolic arrays for MATRIX TRIANGULARIZATION 5. We will discuss Nash implementation in detail and its VHDL coding. 6. Advantages and disadvantage of Nash systolic implementation. 7. Chaung and He’s implementation in detail and its VHDL coding. 8. Difficulties chased in this project. 9. Conclusion. 10. VHDL code for Nash Implementation. 11. VHDL code for Chaung and He’s Implementation. 12. Simulation Results. 13. References. 14. PowerPoint Presentation Project Report 1: Systolic Architecture: = A systolic array is composed of matrix-like rows of data processing units called cells. Data processing units (DPU) are similar to central processing units (CPU)s, (except for the usual lack of a program counter, since operation is transport-triggered, i.e., by the arrival of a data object). -

On the Efficiency of Register File Versus Broadcast Interconnect For
On the Efficiency of Register File versus Broadcast Interconnect for Collective Communications in Data-Parallel Hardware Accelerators Ardavan Pedram, Andreas Gerstlauer Robert A. van de Geijn Department of Electrical and Computer Engineering Department of Computer Science The University of Texas at Austin The University of Texas at Austin fardavan,[email protected] [email protected] Abstract—Reducing power consumption and increasing effi- on broadcast communication among a 2D array of PEs. In ciency is a key concern for many applications. How to design this paper, we focus on the LAC’s data-parallel broadcast highly efficient computing elements while maintaining enough interconnect and on showing how representative collective flexibility within a domain of applications is a fundamental question. In this paper, we present how broadcast buses can communication operations can be efficiently mapped onto eliminate the use of power hungry multi-ported register files this architecture. Such collective communications are a core in the context of data-parallel hardware accelerators for linear component of many matrix or other data-intensive operations algebra operations. We demonstrate an algorithm/architecture that often demand matrix manipulations. co-design for the mapping of different collective communication We compare our design with typical SIMD cores with operations, which are crucial for achieving performance and efficiency in most linear algebra routines, such as GEMM, equivalent data parallelism and with L1 and L2 caches that SYRK and matrix transposition. We compare a broadcast bus amount to an equivalent aggregate storage space. To do so, based architecture with conventional SIMD, 2D-SIMD and flat we examine efficiency and performance of the cores for data register file for these operations in terms of area and energy movement and data manipulation in both GEneral matrix- efficiency. -

Computer Systems Architecture
CS 352H: Computer Systems Architecture Topic 14: Multicores, Multiprocessors, and Clusters University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level) parallelism High throughput for independent jobs Parallel processing program Single program run on multiple processors Multicore microprocessors Chips with multiple processors (cores) University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell 2 Hardware and Software Hardware Serial: e.g., Pentium 4 Parallel: e.g., quad-core Xeon e5345 Software Sequential: e.g., matrix multiplication Concurrent: e.g., operating system Sequential/concurrent software can run on serial/parallel hardware Challenge: making effective use of parallel hardware University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell 3 What We’ve Already Covered §2.11: Parallelism and Instructions Synchronization §3.6: Parallelism and Computer Arithmetic Associativity §4.10: Parallelism and Advanced Instruction-Level Parallelism §5.8: Parallelism and Memory Hierarchies Cache Coherence §6.9: Parallelism and I/O: Redundant Arrays of Inexpensive Disks University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell 4 Parallel Programming Parallel software is the problem Need to get significant performance improvement Otherwise, just use a faster uniprocessor, -

Strategies for Managing Business Disruption Due to Grid Computing
Strategies for managing business disruption due to Grid Computing by Vidyadhar Phalke Ph.D. Computer Science, Rutgers University, New Jersey, 1995 M.S. Computer Science, Rutgers University, New Jersey, 1992 B.Tech. Computer Science, Indian Institute of Technology, Delhi, 1989 Submitted to the MIT Sloan School of Management in Partial Fulfillment of the Requirements for the Degree of Master of Science in the Management of Technology at the Massachusetts Institute of Technology June 2003 © 2003 Vidyadhar Phalke All Rights Reserved The author hereby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part Signature of Author: MIT Sloan School of Management 9 May 2003 Certified By: Starling D. Hunter III Theodore T. Miller Career Development Assistant Professor Thesis Supervisor Accepted By: David A. Weber Director, Management of Technology Program 2 Strategies for managing business disruption due to Grid Computing by Vidyadhar Phalke Submitted to the MIT Sloan School of Management on May 9 2003 in partial fulfillment of the requirements for the degree of Master of Science in the Management of Technology ABSTRACT In the technology centric businesses disruptive technologies displace incumbents time and again, sometimes to the extent that incumbents go bankrupt. In this thesis we would address the issue of what strategies are essential to prepare for and to manage disruptions for the affected businesses and industries. Specifically we will look at grid computing that is poised to disrupt (1) certain Enterprise IT departments, and (2) the software industry in the high-performance and web services space.