Vector Microprocessors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mipspro C++ Programmer's Guide
MIPSproTM C++ Programmer’s Guide 007–0704–150 CONTRIBUTORS Rewritten in 2002 by Jean Wilson with engineering support from John Wilkinson and editing support from Susan Wilkening. COPYRIGHT Copyright © 1995, 1999, 2002 - 2003 Silicon Graphics, Inc. All rights reserved; provided portions may be copyright in third parties, as indicated elsewhere herein. No permission is granted to copy, distribute, or create derivative works from the contents of this electronic documentation in any manner, in whole or in part, without the prior written permission of Silicon Graphics, Inc. LIMITED RIGHTS LEGEND The electronic (software) version of this document was developed at private expense; if acquired under an agreement with the USA government or any contractor thereto, it is acquired as "commercial computer software" subject to the provisions of its applicable license agreement, as specified in (a) 48 CFR 12.212 of the FAR; or, if acquired for Department of Defense units, (b) 48 CFR 227-7202 of the DoD FAR Supplement; or sections succeeding thereto. Contractor/manufacturer is Silicon Graphics, Inc., 1600 Amphitheatre Pkwy 2E, Mountain View, CA 94043-1351. TRADEMARKS AND ATTRIBUTIONS Silicon Graphics, SGI, the SGI logo, IRIX, O2, Octane, and Origin are registered trademarks and OpenMP and ProDev are trademarks of Silicon Graphics, Inc. in the United States and/or other countries worldwide. MIPS, MIPS I, MIPS II, MIPS III, MIPS IV, R2000, R3000, R4000, R4400, R4600, R5000, and R8000 are registered or unregistered trademarks and MIPSpro, R10000, R12000, R1400 are trademarks of MIPS Technologies, Inc., used under license by Silicon Graphics, Inc. Portions of this publication may have been derived from the OpenMP Language Application Program Interface Specification. -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

RISC-V Vector Extension Webinar II
RISC-V Vector Extension Webinar II August 3th, 2021 Thang Tran, Ph.D. Principal Engineer Webinar II - Agenda • Andes overview • Vector technology background – SIMD/vector concept – Vector processor basic • RISC-V V extension ISA – Basic – CSR • RISC-V V extension ISA – Memory operations – Compute instructions • Sample codes – Matrix multiplication – Loads with RVV versions 0.8 and 1.0 • AndesCore™ NX27V • Summary Copyright© 2020 Andes Technology Corp. 2 Terminology • ACE: Andes Custom Extension • ISA: Instruction Set Architecture • CSR: Control and Status Register • GOPS: Giga Operations Per Second • SEW: Element Width (8-64) • GFLOPS: Giga Floating-Point OPS • ELEN: Largest Element Width (32 or 64) • XRF: Integer register file • XLEN: Scalar register length in bits (64) • FRF: Floating-point register file • FLEN: FP register length in bits (16-64) • VRF: Vector register file • VLEN: Vector register length in bits (128-512) • SIMD: Single Instruction Multiple Data • LMUL: Register grouping multiple (1/8-8) • MMX: Multi Media Extension • EMUL: Effective LMUL • SSE: Streaming SIMD Extension • VLMAX/MVL: Vector Length Max • AVX: Advanced Vector Extension • AVL/VL: Application Vector Length • Configurable: parameters are fixed at built time, i.e. cache size • Extensible: added instructions to ISA includes custom instructions to be added by customer • Standard extension: the reserved codes in the ISA for special purposes, i.e. FP, DSP, … • Programmable: parameters can be dynamically changed in the program Copyright© 2020 Andes Technology Corp. 3 RISC-V V Extension ISA Basic Copyright© 2020 Andes Technology Corp. 4 Vector Register ISA • Vector-Register ISA Definition: − All vector operations are between vector registers (except for load and store). -

Data-Flow Prescheduling for Large Instruction Windows in Out-Of-Order Processors
Data-Flow Prescheduling for Large Instruction Windows in Out-of-Order Processors Pierre Michaud, Andr´e Seznec IRISA/INRIA Campus de Beaulieu, 35042 Rennes Cedex, France {pmichaud, seznec}@irisa.fr Abstract We introduce data-flow prescheduling. Instructions are sent to the issue buffer in a predicted data-flow order instead The performance of out-of-order processors increases of the sequential order, allowing a smaller issue buffer. The with the instruction window size. In conventional proces- rationale of this proposal is to avoid using entries in the is- sors, the effective instruction window cannot be larger than sue buffer for instructions which operands are known to be the issue buffer. Determining which instructions from the yet unavailable. issue buffer can be launched to the execution units is a time- In our proposal, this reordering of instructions is accom- critical operation which complexity increases with the issue plished through an array of schedule lines. Each schedule buffer size. We propose to relieve the issue stage by reorder- line corresponds to a different depth in the data-flow graph. ing instructions before they enter the issue buffer. This study The depth of each instruction in the data-flow graph is de- introduces the general principle of data-flow prescheduling. termined, and the instruction is inserted in the correspond- Then we describe a possible implementation. Our prelim- ing schedule line. Lines are consumed by the issue buffer inary results show that data-flow prescheduling makes it sequentially. possible to enlarge the effective instruction window while Section 2 briefly describes issue buffers and discusses re- keeping the issue buffer small. -

MIPS® Architecture for Programmers Volume I-B: Introduction to the Micromips32™ Architecture, Revision 5.03
MIPS® Architecture For Programmers Volume I-B: Introduction to the microMIPS32™ Architecture Document Number: MD00741 Revision 5.03 Sept. 9, 2013 Unpublished rights (if any) reserved under the copyright laws of the United States of America and other countries. This document contains information that is proprietary to MIPS Tech, LLC, a Wave Computing company (“MIPS”) and MIPS’ affiliates as applicable. Any copying, reproducing, modifying or use of this information (in whole or in part) that is not expressly permitted in writing by MIPS or MIPS’ affiliates as applicable or an authorized third party is strictly prohibited. At a minimum, this information is protected under unfair competition and copyright laws. Violations thereof may result in criminal penalties and fines. Any document provided in source format (i.e., in a modifiable form such as in FrameMaker or Microsoft Word format) is subject to use and distribution restrictions that are independent of and supplemental to any and all confidentiality restrictions. UNDER NO CIRCUMSTANCES MAY A DOCUMENT PROVIDED IN SOURCE FORMAT BE DISTRIBUTED TO A THIRD PARTY IN SOURCE FORMAT WITHOUT THE EXPRESS WRITTEN PERMISSION OF MIPS (AND MIPS’ AFFILIATES AS APPLICABLE) reserve the right to change the information contained in this document to improve function, design or otherwise. MIPS and MIPS’ affiliates do not assume any liability arising out of the application or use of this information, or of any error or omission in such information. Any warranties, whether express, statutory, implied or otherwise, including but not limited to the implied warranties of merchantability or fitness for a particular purpose, are excluded. Except as expressly provided in any written license agreement from MIPS or an authorized third party, the furnishing of this document does not give recipient any license to any intellectual property rights, including any patent rights, that cover the information in this document. -

Jetson TX2 • NVIDIA Jetson Xavier • GPU Programming • Algorithm Mapping: • Convolutions Parallel Algorithm Execution
GPU and multicore CPU architectures. Algorithm mapping Contributors: N. Tsapanos, I. Karakostas, I. Pitas Aristotle University of Thessaloniki, Greece Presenter: Prof. Ioannis Pitas Aristotle University of Thessaloniki [email protected] www.multidrone.eu Presentation version 1.3 GPU and multicore CPU architectures. Algorithm mapping • GPU and multicore CPU processing boards • Graphics cards • NVIDIA Jetson TX2 • NVIDIA Jetson Xavier • GPU programming • Algorithm mapping: • Convolutions Parallel algorithm execution • Graphics computing: • Highly parallelizable • Linear algebra parallelization: • Vector inner products: 푐 = 풙푇풚. • Matrix-vector multiplications 풚 = 푨풙. • Matrix multiplications: 푪 = 푨푩. Parallel algorithm execution • Convolution: 풚 = 푨풙 • CNN architectures, linear systems, signal filtering. • Correlation: 풚 = 푨풙 • template matching, tracking. • Signal transforms (DFT, DCT, Haar, etc): • Matrix vector product form: 푿 = 푾풙 • 2D transforms (matrix product form): 푿’ = 푾푿. Processing Units • Multicore (CPU): • MIMD. • Focused on latency. • Best single thread performance. • Manycore (GPU): • SIMD. • Focused on throughput. • Best for embarrassingly parallel tasks. Pascal microarchitecture https://devblogs.nvidia.com/inside-pascal/gp100_block_diagram-2/ Pascal microarchitecture https://devblogs.nvidia.com/inside-pascal/gp100_sm_diagram/ GeForce GTX 1080 • Microarchitecture: Pascal. • DRAM: 8 GB GDDR5X at 10000 MHz. • SMs: 20. • Memory bandwidth: 320 GB/s. • CUDA cores: 2560. • L2 Cache: 2048 KB. • Clock (base/boost): 1607/1733 MHz. • L1 Cache: 48 KB per SM. • GFLOPs: 8873. • Shared memory: 96 KB per SM. GPU and multicore CPU architectures. Algorithm mapping • GPU and multicore CPU processing boards • Graphics cards • NVIDIA Jetson TX2 • NVIDIA Jetson Xavier • GPU programming • Algorithm mapping: • Convolutions ARM Cortex-A57: High-End ARMv8 CPU • ARMv8 architecture • Architecture evolution that extends ARM’s applicability to all markets. • Full ARM 32-bit compatibility, streamlined 64-bit capability. -

VAX MACRO and Instruction Set Reference Manual
VAX MACRO and Instruction Set Reference Manual Order Number: AA-LA89A-TE April 1988 This document describes the features of the VAX MACRO instruction set and assembler. It includes a detailed description of MACRO directives and instructions, as well as information about MACRO source program syntax. Revision/Update Information: This manual supersedes the VAX MACRO and Instruction Set Reference Manual, Version 4.0. Software Version: VMS Version 5.0 digital equipment corporation maynard, massachusetts April 1988 The information in this document is subject to change without notice and should not be construed as a commitment by Digital Equipment Corporation. Digital Equipment Corporation assumes no responsibility for any errors that may appear in this document. The software described in this document is furnished under a license and may be used or copied only in accordance with the terms of such license. No responsibility is assumed for the use or reliability of software on equipment that is not supplied by Digital Equipment Corporation or its affiliated companies. Copyright © 1988 by Digital Equipment Corporation All Rights Reserved. Printed in U.S.A. The postpaid READER'S COMMENTS form on the last page of this document requests the user's critical evaluation to assist in preparing future documentation. The following are trademarks of Digital Equipment Corporation: DEC DIBOL UNIBUS DEC/CMS EduSystem VAX DEC/MMS IAS VAXcluster DECnet MASSBUS VMS DECsystem-10 PDP VT DECSYSTEM-20 PDT DECUS RSTS DECwriter RSX t:JD~DD5lD TM ZK4515 HOW TO ORDER ADDITIONAL DOCUMENTATION DIRECT MAIL ORDERS USA 8t PUERTO Rico* CANADA INTERNATIONAL Digital Equipment Corporation Digital Equipment Digital Equipment Corporation P.O. -

Optimizing Packed String Matching on AVX2 Platform
Optimizing Packed String Matching on AVX2 Platform M. Akif Aydo˘gmu¸s1,2 and M.O˘guzhan Külekci1 1 Informatics Institute, Istanbul Technical University, Istanbul, Turkey [email protected], [email protected] 2 TUBITAK UME, Gebze-Kocaeli, Turkey Abstract. Exact string matching, searching for all occurrences of given pattern P on a text T , is a fundamental issue in computer science with many applica- tions in natural language processing, speech processing, computational biology, information retrieval, intrusion detection systems, data compression, and etc. Speeding up the pattern matching operations benefiting from the SIMD par- allelism has received attention in the recent literature, where the empirical results on previous studies revealed that SIMD parallelism significantly helps, while the performance may even be expected to get automatically enhanced with the ever increasing size of the SIMD registers. In this paper, we provide variants of the previously proposed EPSM and SSEF algorithms, which are orig- inally implemented on Intel SSE4.2 (Streaming SIMD Extensions 4.2 version with 128-bit registers). We tune the new algorithms according to Intel AVX2 platform (Advanced Vector Extensions 2 with 256-bit registers) and analyze the gain in performance with respect to the increasing length of the SIMD registers. Profiling the new algorithms by using the Intel Vtune Amplifier for detecting performance bottlenecks led us to consider the cache friendliness and shared-memory access issues in the AVX2 platform. We applied cache op- timization techniques to overcome the problems particularly addressing the search algorithms based on filtering. Experimental comparison of the new solutions with the previously known-to- be-fast algorithms on small, medium, and large alphabet text files with diverse pattern lengths showed that the algorithms on AVX2 platform optimized cache obliviously outperforms the previous solutions. -

MIPS IV Instruction Set
MIPS IV Instruction Set Revision 3.2 September, 1995 Charles Price MIPS Technologies, Inc. All Right Reserved RESTRICTED RIGHTS LEGEND Use, duplication, or disclosure of the technical data contained in this document by the Government is subject to restrictions as set forth in subdivision (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013 and / or in similar or successor clauses in the FAR, or in the DOD or NASA FAR Supplement. Unpublished rights reserved under the Copyright Laws of the United States. Contractor / manufacturer is MIPS Technologies, Inc., 2011 N. Shoreline Blvd., Mountain View, CA 94039-7311. R2000, R3000, R6000, R4000, R4400, R4200, R8000, R4300 and R10000 are trademarks of MIPS Technologies, Inc. MIPS and R3000 are registered trademarks of MIPS Technologies, Inc. The information in this document is preliminary and subject to change without notice. MIPS Technologies, Inc. (MTI) reserves the right to change any portion of the product described herein to improve function or design. MTI does not assume liability arising out of the application or use of any product or circuit described herein. Information on MIPS products is available electronically: (a) Through the World Wide Web. Point your WWW client to: http://www.mips.com (b) Through ftp from the internet site “sgigate.sgi.com”. Login as “ftp” or “anonymous” and then cd to the directory “pub/doc”. (c) Through an automated FAX service: Inside the USA toll free: (800) 446-6477 (800-IGO-MIPS) Outside the USA: (415) 688-4321 (call from a FAX machine) MIPS Technologies, Inc. -

Freescale E200z6 Powerpc Core Reference Manual
e200z6RM 6/2004 Rev. 0 e200z6 PowerPC™ Core Reference Manual Contents SectionParagraph Page Number Title Number ChapterContents 1 e200z6 Overview 1.1 Overview of the e200z6....................................................................................... 1-1 1.1.1 Features............................................................................................................ 1-3 1.2 Programming Model ............................................................................................ 1-4 1.2.1 Register Set...................................................................................................... 1-4 1.3 Instruction Set ...................................................................................................... 1-6 1.4 Interrupts and Exception Handling ...................................................................... 1-7 1.4.1 Exception Handling ......................................................................................... 1-8 1.4.2 Interrupt Classes .............................................................................................. 1-8 1.4.3 Interrupt Types................................................................................................. 1-9 1.4.4 Interrupt Registers............................................................................................ 1-9 1.5 Microarchitecture Summary .............................................................................. 1-12 1.5.1 Instruction Unit Features .............................................................................. -
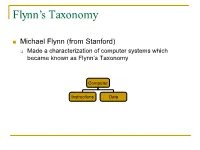
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

CS3210: Booting and X86
1 CS3210: Booting and x86 Taesoo Kim 2 What is an operating system? • e.g. OSX, Windows, Linux, FreeBSD, etc. • What does an OS do for you? • Abstract the hardware for convenience and portability • Multiplex the hardware among multiple applications • Isolate applications to contain bugs • Allow sharing among applications 3 Example: Intel i386 4 Example: IBM T42 5 Abstract model (Wikipedia) 6 Abstract model: CPU, Memory, and I/O • CPU: execute instruction, IP → next IP • Memory: read/write, address → data • I/O: talk to external world, memory-mapped I/O or port I/O I/O: input and output, IP: instruction pointer 7 Today: Bootstrapping • CPU → what's first instruction? • Memory → what's initial code/data? • I/O → whom to talk to? 8 What happens after power on? • High-level: Firmware → Bootloader → OS kernel • e.g., jos: BIOS → boot/* → kern/* • e.g., xv6: BIOS → bootblock → kernel • e.g., Linux: BIOS/UEFI → LILO/GRUB/syslinux → vmlinuz • Why three steps? • What are the handover protocols? 9 BIOS: Basic Input/Output System • QEMU uses an opensource BIOS, called SeaBIOS • e.g., try to run, qemu (with no arguments) 10 From power-on to BIOS in x86 (miniboot) • Set IP → 4GB - 16B (0xfffffff0) • e.g., 80286: 1MB - 16B (0xffff0) • e.g., SPARCS v8: 0x00 (reset vector) DEMO : x86 initial state on QEMU 11 The first instruction • To understand, we first need to understand: 1. x86 state (e.g., registers) 2. Memory referencing model (e.g,. segmentation) 3. BIOS features (e.g., memory aliasing) (gdb) x/1i 0xfffffff0 0xfffffff0: ljmp $0xf000,$0xe05b 12 x86