5.1 PARALLEL PROCESSING ARCHITECTURES Parallel Computing Architectures Breaks the Job Into Discrete Parts That Can Be Executed Concurrently
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

2.5 Classification of Parallel Computers
52 // Architectures 2.5 Classification of Parallel Computers 2.5 Classification of Parallel Computers 2.5.1 Granularity In parallel computing, granularity means the amount of computation in relation to communication or synchronisation Periods of computation are typically separated from periods of communication by synchronization events. • fine level (same operations with different data) ◦ vector processors ◦ instruction level parallelism ◦ fine-grain parallelism: – Relatively small amounts of computational work are done between communication events – Low computation to communication ratio – Facilitates load balancing 53 // Architectures 2.5 Classification of Parallel Computers – Implies high communication overhead and less opportunity for per- formance enhancement – If granularity is too fine it is possible that the overhead required for communications and synchronization between tasks takes longer than the computation. • operation level (different operations simultaneously) • problem level (independent subtasks) ◦ coarse-grain parallelism: – Relatively large amounts of computational work are done between communication/synchronization events – High computation to communication ratio – Implies more opportunity for performance increase – Harder to load balance efficiently 54 // Architectures 2.5 Classification of Parallel Computers 2.5.2 Hardware: Pipelining (was used in supercomputers, e.g. Cray-1) In N elements in pipeline and for 8 element L clock cycles =) for calculation it would take L + N cycles; without pipeline L ∗ N cycles Example of good code for pipelineing: §doi =1 ,k ¤ z ( i ) =x ( i ) +y ( i ) end do ¦ 55 // Architectures 2.5 Classification of Parallel Computers Vector processors, fast vector operations (operations on arrays). Previous example good also for vector processor (vector addition) , but, e.g. recursion – hard to optimise for vector processors Example: IntelMMX – simple vector processor. -

Computer Hardware Architecture Lecture 4
Computer Hardware Architecture Lecture 4 Manfred Liebmann Technische Universit¨atM¨unchen Chair of Optimal Control Center for Mathematical Sciences, M17 [email protected] November 10, 2015 Manfred Liebmann November 10, 2015 Reading List • Pacheco - An Introduction to Parallel Programming (Chapter 1 - 2) { Introduction to computer hardware architecture from the parallel programming angle • Hennessy-Patterson - Computer Architecture - A Quantitative Approach { Reference book for computer hardware architecture All books are available on the Moodle platform! Computer Hardware Architecture 1 Manfred Liebmann November 10, 2015 UMA Architecture Figure 1: A uniform memory access (UMA) multicore system Access times to main memory is the same for all cores in the system! Computer Hardware Architecture 2 Manfred Liebmann November 10, 2015 NUMA Architecture Figure 2: A nonuniform memory access (UMA) multicore system Access times to main memory differs form core to core depending on the proximity of the main memory. This architecture is often used in dual and quad socket servers, due to improved memory bandwidth. Computer Hardware Architecture 3 Manfred Liebmann November 10, 2015 Cache Coherence Figure 3: A shared memory system with two cores and two caches What happens if the same data element z1 is manipulated in two different caches? The hardware enforces cache coherence, i.e. consistency between the caches. Expensive! Computer Hardware Architecture 4 Manfred Liebmann November 10, 2015 False Sharing The cache coherence protocol works on the granularity of a cache line. If two threads manipulate different element within a single cache line, the cache coherency protocol is activated to ensure consistency, even if every thread is only manipulating its own data. -

Massively Parallel Computing with CUDA
Massively Parallel Computing with CUDA Antonino Tumeo Politecnico di Milano 1 GPUs have evolved to the point where many real world applications are easily implemented on them and run significantly faster than on multi-core systems. Future computing architectures will be hybrid systems with parallel-core GPUs working in tandem with multi-core CPUs. Jack Dongarra Professor, University of Tennessee; Author of “Linpack” Why Use the GPU? • The GPU has evolved into a very flexible and powerful processor: • It’s programmable using high-level languages • It supports 32-bit and 64-bit floating point IEEE-754 precision • It offers lots of GFLOPS: • GPU in every PC and workstation What is behind such an Evolution? • The GPU is specialized for compute-intensive, highly parallel computation (exactly what graphics rendering is about) • So, more transistors can be devoted to data processing rather than data caching and flow control ALU ALU Control ALU ALU Cache DRAM DRAM CPU GPU • The fast-growing video game industry exerts strong economic pressure that forces constant innovation GPUs • Each NVIDIA GPU has 240 parallel cores NVIDIA GPU • Within each core 1.4 Billion Transistors • Floating point unit • Logic unit (add, sub, mul, madd) • Move, compare unit • Branch unit • Cores managed by thread manager • Thread manager can spawn and manage 12,000+ threads per core 1 Teraflop of processing power • Zero overhead thread switching Heterogeneous Computing Domains Graphics Massive Data GPU Parallelism (Parallel Computing) Instruction CPU Level (Sequential -
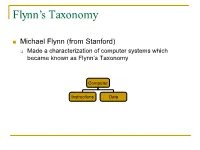
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Parallel Computer Architecture
Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2 Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3 Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … … P … P P P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

A Review of Multicore Processors with Parallel Programming
International Journal of Engineering Technology, Management and Applied Sciences www.ijetmas.com September 2015, Volume 3, Issue 9, ISSN 2349-4476 A Review of Multicore Processors with Parallel Programming Anchal Thakur Ravinder Thakur Research Scholar, CSE Department Assistant Professor, CSE L.R Institute of Engineering and Department Technology, Solan , India. L.R Institute of Engineering and Technology, Solan, India ABSTRACT When the computers first introduced in the market, they came with single processors which limited the performance and efficiency of the computers. The classic way of overcoming the performance issue was to use bigger processors for executing the data with higher speed. Big processor did improve the performance to certain extent but these processors consumed a lot of power which started over heating the internal circuits. To achieve the efficiency and the speed simultaneously the CPU architectures developed multicore processors units in which two or more processors were used to execute the task. The multicore technology offered better response-time while running big applications, better power management and faster execution time. Multicore processors also gave developer an opportunity to parallel programming to execute the task in parallel. These days parallel programming is used to execute a task by distributing it in smaller instructions and executing them on different cores. By using parallel programming the complex tasks that are carried out in a multicore environment can be executed with higher efficiency and performance. Keywords: Multicore Processing, Multicore Utilization, Parallel Processing. INTRODUCTION From the day computers have been invented a great importance has been given to its efficiency for executing the task. -

Vector Vs. Scalar Processors: a Performance Comparison Using a Set of Computational Science Benchmarks
Vector vs. Scalar Processors: A Performance Comparison Using a Set of Computational Science Benchmarks Mike Ashworth, Ian J. Bush and Martyn F. Guest, Computational Science & Engineering Department, CCLRC Daresbury Laboratory ABSTRACT: Despite a significant decline in their popularity in the last decade vector processors are still with us, and manufacturers such as Cray and NEC are bringing new products to market. We have carried out a performance comparison of three full-scale applications, the first, SBLI, a Direct Numerical Simulation code from Computational Fluid Dynamics, the second, DL_POLY, a molecular dynamics code and the third, POLCOMS, a coastal-ocean model. Comparing the performance of the Cray X1 vector system with two massively parallel (MPP) micro-processor-based systems we find three rather different results. The SBLI PCHAN benchmark performs excellently on the Cray X1 with no code modification, showing 100% vectorisation and significantly outperforming the MPP systems. The performance of DL_POLY was initially poor, but we were able to make significant improvements through a few simple optimisations. The POLCOMS code has been substantially restructured for cache-based MPP systems and now does not vectorise at all well on the Cray X1 leading to poor performance. We conclude that both vector and MPP systems can deliver high performance levels but that, depending on the algorithm, careful software design may be necessary if the same code is to achieve high performance on different architectures. KEYWORDS: vector processor, scalar processor, benchmarking, parallel computing, CFD, molecular dynamics, coastal ocean modelling All of the key computational science groups in the 1. Introduction UK made use of vector supercomputers during their halcyon days of the 1970s, 1980s and into the early 1990s Vector computers entered the scene at a very early [1]-[3]. -

Threading SIMD and MIMD in the Multicore Context the Ultrasparc T2
Overview SIMD and MIMD in the Multicore Context Single Instruction Multiple Instruction ● (note: Tute 02 this Weds - handouts) ● Flynn’s Taxonomy Single Data SISD MISD ● multicore architecture concepts Multiple Data SIMD MIMD ● for SIMD, the control unit and processor state (registers) can be shared ■ hardware threading ■ SIMD vs MIMD in the multicore context ● however, SIMD is limited to data parallelism (through multiple ALUs) ■ ● T2: design features for multicore algorithms need a regular structure, e.g. dense linear algebra, graphics ■ SSE2, Altivec, Cell SPE (128-bit registers); e.g. 4×32-bit add ■ system on a chip Rx: x x x x ■ 3 2 1 0 execution: (in-order) pipeline, instruction latency + ■ thread scheduling Ry: y3 y2 y1 y0 ■ caches: associativity, coherence, prefetch = ■ memory system: crossbar, memory controller Rz: z3 z2 z1 z0 (zi = xi + yi) ■ intermission ■ design requires massive effort; requires support from a commodity environment ■ speculation; power savings ■ massive parallelism (e.g. nVidia GPGPU) but memory is still a bottleneck ■ OpenSPARC ● multicore (CMT) is MIMD; hardware threading can be regarded as MIMD ● T2 performance (why the T2 is designed as it is) ■ higher hardware costs also includes larger shared resources (caches, TLBs) ● the Rock processor (slides by Andrew Over; ref: Tremblay, IEEE Micro 2009 ) needed ⇒ less parallelism than for SIMD COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 1 COMP8320 Lecture 2: Multicore Architecture and the T2 2011 ◭◭◭ • ◮◮◮ × 3 Hardware (Multi)threading The UltraSPARC T2: System on a Chip ● recall concurrent execution on a single CPU: switch between threads (or ● OpenSparc Slide Cast Ch 5: p79–81,89 processes) requires the saving (in memory) of thread state (register values) ● aggressively multicore: 8 cores, each with 8-way hardware threading (64 virtual ■ motivation: utilize CPU better when thread stalled for I/O (6300 Lect O1, p9–10) CPUs) ■ what are the costs? do the same for smaller stalls? (e.g. -

Computer Architecture: Parallel Processing Basics
Computer Architecture: Parallel Processing Basics Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/9/13 Today What is Parallel Processing? Why? Kinds of Parallel Processing Multiprocessing and Multithreading Measuring success Speedup Amdhal’s Law Bottlenecks to parallelism 2 Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Cloud Computing EC2 Tashi PDL'09 © 2007-9 Goldstein5 Concurrent Systems Embedded-Physical Distributed Sensor Claytronics Networks Geographically Distributed Power Internet Grid Cloud Computing EC2 Tashi Parallel PDL'09 © 2007-9 Goldstein6 Concurrent Systems Physical Geographical Cloud Parallel Geophysical +++ ++ --- --- location Relative +++ +++ + - location Faults ++++ +++ ++++ -- Number of +++ +++ + - Processors + Network varies varies fixed fixed structure Network --- --- + + connectivity 7 Concurrent System Challenge: Programming The old joke: How long does it take to write a parallel program? One Graduate Student Year 8 Parallel Programming Again?? Increased demand (multicore) Increased scale (cloud) Improved compute/communicate Change in Application focus Irregular Recursive data structures PDL'09 © 2007-9 Goldstein9 Why Parallel Computers? Parallelism: Doing multiple things at a time Things: instructions,