Processors - Barry Wilkinson
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Review Memory Disambiguation Review Explicit Register Renaming
5HYLHZ5HRUGHU%XIIHU 52% &6 *UDGXDWH&RPSXWHU$UFKLWHFWXUH 8VHRIUHRUGHUEXIIHU /HFWXUH ² ,QRUGHULVVXH2XWRIRUGHUH[HFXWLRQ,QRUGHUFRPPLW ² +ROGVUHVXOWVXQWLOWKH\FDQEHFRPPLWWHGLQRUGHU ,QVWUXFWLRQ/HYHO3DUDOOHOLVP ª 6HUYHVDVVRXUFHRIYDOXHVXQWLOLQVWUXFWLRQVFRPPLWWHG ² 3URYLGHVVXSSRUWIRUSUHFLVHH[FHSWLRQV6SHFXODWLRQVLPSO\WKURZRXW *HWWLQJWKH&3, LQVWUXFWLRQVODWHUWKDQH[FHSWHGLQVWUXFWLRQ ² &RPPLWVXVHUYLVLEOHVWDWHLQLQVWUXFWLRQRUGHU ² 6WRUHVVHQWWRPHPRU\V\VWHPRQO\ZKHQWKH\UHDFKKHDGRIEXIIHU 6HSWHPEHU ,Q2UGHU&RPPLW LVLPSRUWDQWEHFDXVH 3URI-RKQ.XELDWRZLF] ² $OORZVWKHJHQHUDWLRQRISUHFLVHH[FHSWLRQV ² $OORZVVSHFXODWLRQDFURVVEUDQFKHV &6.XELDWRZLF] &6.XELDWRZLF] /HF /HF 5HYLHZ0HPRU\'LVDPELJXDWLRQ 5HYLHZ([SOLFLW5HJLVWHU5HQDPLQJ 4XHVWLRQ*LYHQDORDGWKDWIROORZVDVWRUHLQSURJUDP 0DNHXVHRIDSK\VLFDO UHJLVWHUILOHWKDWLVODUJHUWKDQ RUGHUDUHWKHWZRUHODWHG" QXPEHURIUHJLVWHUVVSHFLILHGE\,6$ ² 7U\LQJWRGHWHFW5$:KD]DUGVWKURXJKPHPRU\ .H\LQVLJKW$OORFDWHDQHZSK\VLFDOGHVWLQDWLRQUHJLVWHU ² 6WRUHVFRPPLWLQRUGHU 52% VRQR:$5:$:PHPRU\KD]DUGV IRUHYHU\LQVWUXFWLRQWKDWZULWHV ,PSOHPHQWDWLRQ ² 5HPRYHVDOOFKDQFHRI:$5RU:$:KD]DUGV ² .HHSTXHXHRIVWRUHVLQSURJRUGHU ² 6LPLODUWRFRPSLOHUWUDQVIRUPDWLRQFDOOHG6WDWLF6LQJOH$VVLJQPHQW ² :DWFKIRUSRVLWLRQRIQHZORDGVUHODWLYHWRH[LVWLQJVWRUHV ª /LNHKDUGZDUHEDVHGG\QDPLFFRPSLODWLRQ" :KHQKDYHDGGUHVVIRUORDGFKHFNVWRUHTXHXH 0HFKDQLVP".HHSDWUDQVODWLRQWDEOH ² ,IDQ\ VWRUHSULRUWRORDGLVZDLWLQJIRULWVDGGUHVVVWDOOORDG ² ,6$UHJLVWHU⇒ SK\VLFDOUHJLVWHUPDSSLQJ ² ,IORDGDGGUHVVPDWFKHVHDUOLHUVWRUHDGGUHVV DVVRFLDWLYHORRNXS ² :KHQUHJLVWHUZULWWHQUHSODFHHQWU\ZLWKQHZUHJLVWHUIURPIUHHOLVW WKHQZHKDYHDPHPRU\LQGXFHG -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills
ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills The ARM CortexA product line has changed significantly since the introduction of the CortexA8 in 2005. ARM’s next major leap came with the CortexA9 which was the first design to incorporate multiple cores. The next advance was the development of the big.LITTLE architecture, which incorporates both high performance (A15) and high efficiency(A7) cores. Most recently the A57 and A53 have added 64bit support to the product line. The ARM Cortex series cores are all made up of the main processing unit, a L1 instruction cache, a L1 data cache, an advanced SIMD core and a floating point core. Each processor then has an additional L2 cache shared between all cores (if there are multiple), debug support and an interface bus for communicating with the rest of the system. Multicore processors (such as the A53 and A57) also include additional hardware to facilitate coherency between cores. The ARM CortexA57 is a 64bit processor that supports 1 to 4 cores. The instruction pipeline in each core supports fetching up to three instructions per cycle to send down the pipeline. The instruction pipeline is made up of a 12 stage in order pipeline and a collection of parallel pipelines that range in size from 3 to 15 stages as seen below. The ARM CortexA53 is similar to the A57, but is designed to be more power efficient at the cost of processing power. The A57 in order pipeline is made up of 5 stages of instruction fetch and 7 stages of instruction decode and register renaming. -
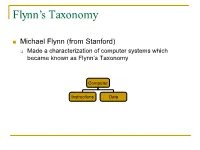
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

Out-Of-Order Execution & Register Renaming
Asanovic/Devadas Spring 2002 6.823 Out-of-Order Execution & Register Renaming Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Asanovic/Devadas Spring 2002 6.823 Scoreboard for In-order Issue Busy[unit#] : a bit-vector to indicate unit’s availability. (unit = Int, Add, Mult, Div) These bits are hardwired to FU's. WP[reg#] : a bit-vector to record the registers for which writes are pending Issue checks the instruction (opcode dest src1 src2) against the scoreboard (Busy & WP) to dispatch FU available? not Busy[FU#] RAW? WP[src1] or WP[src2] WAR? cannot arise WAW? WP[dest] Asanovic/Devadas Spring 2002 Out-of-Order Dispatch 6.823 ALU Mem IF ID Issue WB Fadd Fmul • Issue stage buffer holds multiple instructions waiting to issue. • Decode adds next instruction to buffer if there is space and the instruction does not cause a WAR or WAW hazard. • Any instruction in buffer whose RAW hazards are satisfied can be dispatched (for now, at most one dispatch per cycle). On a write back (WB), new instructions may get enabled. Asanovic/Devadas Spring 2002 6.823 Out-of-Order Issue: an example latency 1 LD F2, 34(R2) 1 1 2 2 LD F4, 45(R3) long 3 MULTD F6, F4, F2 3 4 3 4 SUBD F8, F2, F2 1 5 5 DIVD F4, F2, F8 4 6 ADDD F10, F6, F4 1 6 In-order: 1 (2,1) . 2 3 4 4 3 5 . 5 6 6 Out-of-order: 1 (2,1) 4 4 . 2 3 . 3 5 . -

Dynamic Register Renaming Through Virtual-Physical Registers
Dynamic Register Renaming Through Virtual-Physical Registers † Teresa Monreal [email protected] Antonio González* [email protected] Mateo Valero* [email protected] †† José González [email protected] † Víctor Viñals [email protected] †Departamento de Informática e Ing. de Sistemas. Centro Politécnico Superior - Univ. de Zaragoza, Zaragoza, Spain. *Departament d’ Arquitectura de Computadors. Universitat Politècnica de Catalunya, Barcelona, Spain. ††Departamento de Ingeniería y Tecnología de Computadores. Universidad de Murcia, Murcia, Spain. Abstract Register file access time represents one of the critical delays of current microprocessors, and it is expected to become more critical as future processors increase the instruction window size and the issue width. This paper present a novel dynamic register renaming scheme that delays the allocation of physical registers until a late stage in the pipeline. We show that it can provide important savings in number of physical registers so it can significantly shorter the register file access time. Delaying the allocation of physical registers requires some artifact to keep track of dependences. This is achieved by introducing the concept of virtual-physical registers, which are tags that do not require any storage location. The proposed renaming scheme shortens the average number of cycles that each physical register is allocated, and allows for an early execution of instructions since they can obtain a physical register for its destination earlier than with the conventional scheme. Early execution is especially beneficial for branches and memory operations, since the former can be resolved earlier and the latter can prefetch their data in advance. 1. Introduction Dynamically-scheduled superscalar processors exploit instruction-level parallelism (ILP) by overlapping the execution of instructions in an instruction window. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Hardware-Sensitive Database Operations - II
Faculty of Computer Science Database and Software Engineering Group Hardware-Sensitive Database Operations - II Balasubramanian (Bala) Gurumurthy Advanced Topics in Databases, 2019/May/17 Otto-von-Guericke University of Magdeburg So Far... ● Hardware evolution and current challenges ● Hardware-oblivious vs. hardware-sensitive programming ● Pipelining in RISC computing ● Pipeline Hazards ○ Structural hazard ○ Data hazard ○ Control hazard ● Resolving hazards ○ Loop-Unrolling ○ Predication Bala Gurumurthy | Hardware-Sensitive Database Operations Part II We will see ● Vectorization ○ SIMD Execution ○ SIMD in DBMS Operation ● GPUs in DBMSs ○ Processing Model ○ Handling Synchronization Bala Gurumurthy | Hardware-Sensitive Database Operations Vectorization Leveraging Modern Processing Capabilities Hardware Parallelism One we know already: Pipelining ● Separate chip regions for individual tasks to execute independently ● Advantage: parallelism + sequential execution semantics ● We discussed problems of hazards ● VLSI tech. limits degree up to which pipelining is feasible [Kaeslin, 2008] Bala Gurumurthy | Hardware-Sensitive Database Operations Hardware Parallelism Chip area can be used for other types of parallelism: Computer systems typically use identical hardware circuits, but their function may be controlled by different instruction stream Si: Bala Gurumurthy | Hardware-Sensitive Database Operations Special instances Example of this architecture? Bala Gurumurthy | Hardware-Sensitive Database Operations Special instances Example of this architecture? -
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK -

Trends in Processor Architecture
A. González Trends in Processor Architecture Trends in Processor Architecture Antonio González Universitat Politècnica de Catalunya, Barcelona, Spain 1. Past Trends Processors have undergone a tremendous evolution throughout their history. A key milestone in this evolution was the introduction of the microprocessor, term that refers to a processor that is implemented in a single chip. The first microprocessor was introduced by Intel under the name of Intel 4004 in 1971. It contained about 2,300 transistors, was clocked at 740 KHz and delivered 92,000 instructions per second while dissipating around 0.5 watts. Since then, practically every year we have witnessed the launch of a new microprocessor, delivering significant performance improvements over previous ones. Some studies have estimated this growth to be exponential, in the order of about 50% per year, which results in a cumulative growth of over three orders of magnitude in a time span of two decades [12]. These improvements have been fueled by advances in the manufacturing process and innovations in processor architecture. According to several studies [4][6], both aspects contributed in a similar amount to the global gains. The manufacturing process technology has tried to follow the scaling recipe laid down by Robert N. Dennard in the early 1970s [7]. The basics of this technology scaling consists of reducing transistor dimensions by a factor of 30% every generation (typically 2 years) while keeping electric fields constant. The 30% scaling in the dimensions results in doubling the transistor density (doubling transistor density every two years was predicted in 1975 by Gordon Moore and is normally referred to as Moore’s Law [21][22]).