MIPS Architecture with Tomasulo Algorithm [12]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IEEE Paper Template in A4
Vasantha.N.S. et al, International Journal of Computer Science and Mobile Computing, Vol.6 Issue.6, June- 2017, pg. 302-306 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IMPACT FACTOR: 6.017 IJCSMC, Vol. 6, Issue. 6, June 2017, pg.302 – 306 Enhancing Performance in Multiple Execution Unit Architecture using Tomasulo Algorithm Vasantha.N.S.1, Meghana Kulkarni2 ¹Department of VLSI and Embedded Systems, Centre for PG Studies, VTU Belagavi, India ²Associate Professor Department of VLSI and Embedded Systems, Centre for PG Studies, VTU Belagavi, India 1 [email protected] ; 2 [email protected] Abstract— Tomasulo’s algorithm is a computer architecture hardware algorithm for dynamic scheduling of instructions that allows out-of-order execution, designed to efficiently utilize multiple execution units. It was developed by Robert Tomasulo at IBM. The major innovations of Tomasulo’s algorithm include register renaming in hardware. It also uses the concept of reservation stations for all execution units. A common data bus (CDB) on which computed values broadcast to all reservation stations that may need them is also present. The algorithm allows for improved parallel execution of instructions that would otherwise stall under the use of other earlier algorithms such as scoreboarding. Keywords— Reservation Station, Register renaming, common data bus, multiple execution unit, register file I. INTRODUCTION The instructions in any program may be executed in any of the 2 ways namely sequential order and the other is the data flow order. The sequential order is the one in which the instructions are executed one after the other but in reality this flow is very rare in programs. -

Review Memory Disambiguation Review Explicit Register Renaming
5HYLHZ5HRUGHU%XIIHU 52% &6 *UDGXDWH&RPSXWHU$UFKLWHFWXUH 8VHRIUHRUGHUEXIIHU /HFWXUH ² ,QRUGHULVVXH2XWRIRUGHUH[HFXWLRQ,QRUGHUFRPPLW ² +ROGVUHVXOWVXQWLOWKH\FDQEHFRPPLWWHGLQRUGHU ,QVWUXFWLRQ/HYHO3DUDOOHOLVP ª 6HUYHVDVVRXUFHRIYDOXHVXQWLOLQVWUXFWLRQVFRPPLWWHG ² 3URYLGHVVXSSRUWIRUSUHFLVHH[FHSWLRQV6SHFXODWLRQVLPSO\WKURZRXW *HWWLQJWKH&3, LQVWUXFWLRQVODWHUWKDQH[FHSWHGLQVWUXFWLRQ ² &RPPLWVXVHUYLVLEOHVWDWHLQLQVWUXFWLRQRUGHU ² 6WRUHVVHQWWRPHPRU\V\VWHPRQO\ZKHQWKH\UHDFKKHDGRIEXIIHU 6HSWHPEHU ,Q2UGHU&RPPLW LVLPSRUWDQWEHFDXVH 3URI-RKQ.XELDWRZLF] ² $OORZVWKHJHQHUDWLRQRISUHFLVHH[FHSWLRQV ² $OORZVVSHFXODWLRQDFURVVEUDQFKHV &6.XELDWRZLF] &6.XELDWRZLF] /HF /HF 5HYLHZ0HPRU\'LVDPELJXDWLRQ 5HYLHZ([SOLFLW5HJLVWHU5HQDPLQJ 4XHVWLRQ*LYHQDORDGWKDWIROORZVDVWRUHLQSURJUDP 0DNHXVHRIDSK\VLFDO UHJLVWHUILOHWKDWLVODUJHUWKDQ RUGHUDUHWKHWZRUHODWHG" QXPEHURIUHJLVWHUVVSHFLILHGE\,6$ ² 7U\LQJWRGHWHFW5$:KD]DUGVWKURXJKPHPRU\ .H\LQVLJKW$OORFDWHDQHZSK\VLFDOGHVWLQDWLRQUHJLVWHU ² 6WRUHVFRPPLWLQRUGHU 52% VRQR:$5:$:PHPRU\KD]DUGV IRUHYHU\LQVWUXFWLRQWKDWZULWHV ,PSOHPHQWDWLRQ ² 5HPRYHVDOOFKDQFHRI:$5RU:$:KD]DUGV ² .HHSTXHXHRIVWRUHVLQSURJRUGHU ² 6LPLODUWRFRPSLOHUWUDQVIRUPDWLRQFDOOHG6WDWLF6LQJOH$VVLJQPHQW ² :DWFKIRUSRVLWLRQRIQHZORDGVUHODWLYHWRH[LVWLQJVWRUHV ª /LNHKDUGZDUHEDVHGG\QDPLFFRPSLODWLRQ" :KHQKDYHDGGUHVVIRUORDGFKHFNVWRUHTXHXH 0HFKDQLVP".HHSDWUDQVODWLRQWDEOH ² ,IDQ\ VWRUHSULRUWRORDGLVZDLWLQJIRULWVDGGUHVVVWDOOORDG ² ,6$UHJLVWHU⇒ SK\VLFDOUHJLVWHUPDSSLQJ ² ,IORDGDGGUHVVPDWFKHVHDUOLHUVWRUHDGGUHVV DVVRFLDWLYHORRNXS ² :KHQUHJLVWHUZULWWHQUHSODFHHQWU\ZLWKQHZUHJLVWHUIURPIUHHOLVW WKHQZHKDYHDPHPRU\LQGXFHG -

MIPS Architecture
Introduction to the MIPS Architecture January 14–16, 2013 1 / 24 Unofficial textbook MIPS Assembly Language Programming by Robert Britton A beta version of this book (2003) is available free online 2 / 24 Exercise 1 clarification This is a question about converting between bases • bit – base-2 (states: 0 and 1) • flash cell – base-4 (states: 0–3) • hex digit – base-16 (states: 0–9, A–F) • Each hex digit represents 4 bits of information: 0xE ) 1110 • It takes two hex digits to represent one byte: 1010 0111 ) 0xA7 3 / 24 Outline Overview of the MIPS architecture What is a computer architecture? Fetch-decode-execute cycle Datapath and control unit Components of the MIPS architecture Memory Other components of the datapath Control unit 4 / 24 What is a computer architecture? One view: The machine language the CPU implements Instruction set architecture (ISA) • Built in data types (integers, floating point numbers) • Fixed set of instructions • Fixed set of on-processor variables (registers) • Interface for reading/writing memory • Mechanisms to do input/output 5 / 24 What is a computer architecture? Another view: How the ISA is implemented Microarchitecture 6 / 24 How a computer executes a program Fetch-decode-execute cycle (FDX) 1. fetch the next instruction from memory 2. decode the instruction 3. execute the instruction Decode determines: • operation to execute • arguments to use • where the result will be stored Execute: • performs the operation • determines next instruction to fetch (by default, next one) 7 / 24 Datapath and control unit -

Computer Science 246 Computer Architecture Spring 2010 Harvard University
Computer Science 246 Computer Architecture Spring 2010 Harvard University Instructor: Prof. David Brooks [email protected] Dynamic Branch Prediction, Speculation, and Multiple Issue Computer Science 246 David Brooks Lecture Outline • Tomasulo’s Algorithm Review (3.1-3.3) • Pointer-Based Renaming (MIPS R10000) • Dynamic Branch Prediction (3.4) • Other Front-end Optimizations (3.5) – Branch Target Buffers/Return Address Stack Computer Science 246 David Brooks Tomasulo Review • Reservation Stations – Distribute RAW hazard detection – Renaming eliminates WAW hazards – Buffering values in Reservation Stations removes WARs – Tag match in CDB requires many associative compares • Common Data Bus – Achilles heal of Tomasulo – Multiple writebacks (multiple CDBs) expensive • Load/Store reordering – Load address compared with store address in store buffer Computer Science 246 David Brooks Tomasulo Organization From Mem FP Op FP Registers Queue Load Buffers Load1 Load2 Load3 Load4 Load5 Store Load6 Buffers Add1 Add2 Mult1 Add3 Mult2 Reservation To Mem Stations FP adders FP multipliers Common Data Bus (CDB) Tomasulo Review 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 LD F0, 0(R1) Iss M1 M2 M3 M4 M5 M6 M7 M8 Wb MUL F4, F0, F2 Iss Iss Iss Iss Iss Iss Iss Iss Iss Ex Ex Ex Ex Wb SD 0(R1), F0 Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss Iss M1 M2 M3 Wb SUBI R1, R1, 8 Iss Ex Wb BNEZ R1, Loop Iss Ex Wb LD F0, 0(R1) Iss Iss Iss Iss M Wb MUL F4, F0, F2 Iss Iss Iss Iss Iss Ex Ex Ex Ex Wb SD 0(R1), F0 Iss Iss Iss Iss Iss Iss Iss Iss Iss M1 M2 -

Dynamic Scheduling
Dynamically-Scheduled Machines ! • In a Statically-Scheduled machine, the compiler schedules all instructions to avoid data-hazards: the ID unit may require that instructions can issue together without hazards, otherwise the ID unit inserts stalls until the hazards clear! • This section will deal with Dynamically-Scheduled machines, where hardware- based techniques are used to detect are remove avoidable data-hazards automatically, to allow ‘out-of-order’ execution, and improve performance! • Dynamic scheduling used in the Pentium III and 4, the AMD Athlon, the MIPS R10000, the SUN Ultra-SPARC III; the IBM Power chips, the IBM/Motorola PowerPC, the HP Alpha 21264, the Intel Dual-Core and Quad-Core processors! • In contrast, static multiple-issue with compiler-based scheduling is used in the Intel IA-64 Itanium architectures! • In 2007, the dual-core and quad-core Intel processors use the Pentium 5 family of dynamically-scheduled processors. The Itanium has had a hard time gaining market share.! Ch. 6, Advanced Pipelining-DYNAMIC, slide 1! © Ted Szymanski! Dynamic Scheduling - the Idea ! (class text - pg 168, 171, 5th ed.)" !DIVD ! !F0, F2, F4! ADDD ! !F10, F0, F8 !- data hazard, stall issue for 23 cc! SUBD ! !F12, F8, F14 !- SUBD inherits 23 cc of stalls! • ADDD depends on DIVD; in a static scheduled machine, the ID unit detects the hazard and causes the basic pipeline to stall for 23 cc! • The SUBD instruction cannot execute because the pipeline has stalled, even though SUBD does not logically depend upon either previous instruction! • suppose the machine architecture was re-organized to let the SUBD and subsequent instructions “bypass” the previous stalled instruction (the ADDD) and proceed with its execution -> we would allow “out-of-order” execution! • however, out-of-order execution would allow out-of-order completion, which may allow RW (Read-Write) and WW (Write-Write) data hazards ! • a RW and WW hazard occurs when the reads/writes complete in the wrong order, destroying the data. -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

United States Patent (19) 11 Patent Number: 5,680,565 Glew Et Al
USOO568.0565A United States Patent (19) 11 Patent Number: 5,680,565 Glew et al. 45 Date of Patent: Oct. 21, 1997 (54) METHOD AND APPARATUS FOR Diefendorff, "Organization of the Motorola 88110 Super PERFORMING PAGE TABLE WALKS INA scalar RISC Microprocessor.” IEEE Micro, Apr. 1996, pp. MCROPROCESSOR CAPABLE OF 40-63. PROCESSING SPECULATIVE Yeager, Kenneth C. "The MIPS R10000 Superscalar Micro INSTRUCTIONS processor.” IEEE Micro, Apr. 1996, pp. 28-40 Apr. 1996. 75 Inventors: Andy Glew, Hillsboro; Glenn Hinton; Smotherman et al. "Instruction Scheduling for the Motorola Haitham Akkary, both of Portland, all 88.110" Microarchitecture 1993 International Symposium, of Oreg. pp. 257-262. Circello et al., “The Motorola 68060 Microprocessor.” 73) Assignee: Intel Corporation, Santa Clara, Calif. COMPCON IEEE Comp. Soc. Int'l Conf., Spring 1993, pp. 73-78. 21 Appl. No.: 176,363 "Superscalar Microprocessor Design" by Mike Johnson, Advanced Micro Devices, Prentice Hall, 1991. 22 Filed: Dec. 30, 1993 Popescu, et al., "The Metaflow Architecture.” IEEE Micro, (51) Int. C. G06F 12/12 pp. 10-13 and 63–73, Jun. 1991. 52 U.S. Cl. ........................... 395/415: 395/800; 395/383 Primary Examiner-David K. Moore 58) Field of Search .................................. 395/400, 375, Assistant Examiner-Kevin Verbrugge 395/800, 414, 415, 421.03 Attorney, Agent, or Firm-Blakely, Sokoloff, Taylor & 56 References Cited Zafiman U.S. PATENT DOCUMENTS 57 ABSTRACT 5,136,697 8/1992 Johnson .................................. 395/586 A page table walk is performed in response to a data 5,226,126 7/1993 McFarland et al. 395/.394 translation lookaside buffer miss based on a speculative 5,230,068 7/1993 Van Dyke et al. -

ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills
ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills The ARM CortexA product line has changed significantly since the introduction of the CortexA8 in 2005. ARM’s next major leap came with the CortexA9 which was the first design to incorporate multiple cores. The next advance was the development of the big.LITTLE architecture, which incorporates both high performance (A15) and high efficiency(A7) cores. Most recently the A57 and A53 have added 64bit support to the product line. The ARM Cortex series cores are all made up of the main processing unit, a L1 instruction cache, a L1 data cache, an advanced SIMD core and a floating point core. Each processor then has an additional L2 cache shared between all cores (if there are multiple), debug support and an interface bus for communicating with the rest of the system. Multicore processors (such as the A53 and A57) also include additional hardware to facilitate coherency between cores. The ARM CortexA57 is a 64bit processor that supports 1 to 4 cores. The instruction pipeline in each core supports fetching up to three instructions per cycle to send down the pipeline. The instruction pipeline is made up of a 12 stage in order pipeline and a collection of parallel pipelines that range in size from 3 to 15 stages as seen below. The ARM CortexA53 is similar to the A57, but is designed to be more power efficient at the cost of processing power. The A57 in order pipeline is made up of 5 stages of instruction fetch and 7 stages of instruction decode and register renaming. -

MIPS IV Instruction Set
MIPS IV Instruction Set Revision 3.2 September, 1995 Charles Price MIPS Technologies, Inc. All Right Reserved RESTRICTED RIGHTS LEGEND Use, duplication, or disclosure of the technical data contained in this document by the Government is subject to restrictions as set forth in subdivision (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013 and / or in similar or successor clauses in the FAR, or in the DOD or NASA FAR Supplement. Unpublished rights reserved under the Copyright Laws of the United States. Contractor / manufacturer is MIPS Technologies, Inc., 2011 N. Shoreline Blvd., Mountain View, CA 94039-7311. R2000, R3000, R6000, R4000, R4400, R4200, R8000, R4300 and R10000 are trademarks of MIPS Technologies, Inc. MIPS and R3000 are registered trademarks of MIPS Technologies, Inc. The information in this document is preliminary and subject to change without notice. MIPS Technologies, Inc. (MTI) reserves the right to change any portion of the product described herein to improve function or design. MTI does not assume liability arising out of the application or use of any product or circuit described herein. Information on MIPS products is available electronically: (a) Through the World Wide Web. Point your WWW client to: http://www.mips.com (b) Through ftp from the internet site “sgigate.sgi.com”. Login as “ftp” or “anonymous” and then cd to the directory “pub/doc”. (c) Through an automated FAX service: Inside the USA toll free: (800) 446-6477 (800-IGO-MIPS) Outside the USA: (415) 688-4321 (call from a FAX machine) MIPS Technologies, Inc. -

Sections 3.2 and 3.3 Dynamic Scheduling – Tomasulo's Algorithm
EEF011 Computer Architecture 計算機結構 Sections 3.2 and 3.3 Dynamic Scheduling – Tomasulo’s Algorithm 吳俊興 高雄大學資訊工程學系 October 2004 A Dynamic Algorithm: Tomasulo’s Algorithm • For IBM 360/91 (before caches!) – 3 years after CDC • Goal: High Performance without special compilers • Small number of floating point registers (4 in 360) prevented interesting compiler scheduling of operations – This led Tomasulo to try to figure out how to get more effective registers — renaming in hardware! • Why Study 1966 Computer? • The descendants of this have flourished! – Alpha 21264, HP 8000, MIPS 10000, Pentium III, PowerPC 604, … Example to eleminate WAR and WAW by register renaming • Original DIV.D F0, F2, F4 ADD.D F6, F0, F8 S.D F6, 0(R1) SUB.D F8, F10, F14 MUL.D F6, F10, F8 WAR between ADD.D and SUB.D, WAW between ADD.D and MUL.D (Due to that DIV.D needs to take much longer cycles to get F0) • Register renaming DIV.D F0, F2, F4 ADD.D S, F0, F8 S.D S, 0(R1) SUB.D T, F10, F14 MUL.D F6, F10, T Tomasulo Algorithm • Register renaming provided – by reservation stations, which buffer the operands of instructions waiting to issue – by the issue logic • Basic idea: – a reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from a register (WAR) – pending instructions designate the reservation station that will provide their input (RAW) – when successive writes to a register overlap in execution, only the last one is actually used to update the register (WAW) As instructions are issued, the register specifiers for pending operands are renamed to the names of the reservation station, which provides register renaming • more reservation stations than real registers Properties of Tomasulo Algorithm 1. -
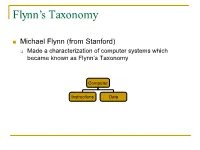
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing.