X86-64 Overview 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

The Von Neumann Computer Model 5/30/17, 10:03 PM
The von Neumann Computer Model 5/30/17, 10:03 PM CIS-77 Home http://www.c-jump.com/CIS77/CIS77syllabus.htm The von Neumann Computer Model 1. The von Neumann Computer Model 2. Components of the Von Neumann Model 3. Communication Between Memory and Processing Unit 4. CPU data-path 5. Memory Operations 6. Understanding the MAR and the MDR 7. Understanding the MAR and the MDR, Cont. 8. ALU, the Processing Unit 9. ALU and the Word Length 10. Control Unit 11. Control Unit, Cont. 12. Input/Output 13. Input/Output Ports 14. Input/Output Address Space 15. Console Input/Output in Protected Memory Mode 16. Instruction Processing 17. Instruction Components 18. Why Learn Intel x86 ISA ? 19. Design of the x86 CPU Instruction Set 20. CPU Instruction Set 21. History of IBM PC 22. Early x86 Processor Family 23. 8086 and 8088 CPU 24. 80186 CPU 25. 80286 CPU 26. 80386 CPU 27. 80386 CPU, Cont. 28. 80486 CPU 29. Pentium (Intel 80586) 30. Pentium Pro 31. Pentium II 32. Itanium processor 1. The von Neumann Computer Model Von Neumann computer systems contain three main building blocks: The following block diagram shows major relationship between CPU components: the central processing unit (CPU), memory, and input/output devices (I/O). These three components are connected together using the system bus. The most prominent items within the CPU are the registers: they can be manipulated directly by a computer program. http://www.c-jump.com/CIS77/CPU/VonNeumann/lecture.html Page 1 of 15 IPR2017-01532 FanDuel, et al. -
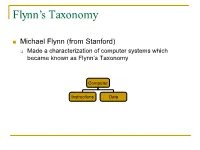
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

Demystifying Internet of Things Security Successful Iot Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M
Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment — Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Ned Smith David M. Wheeler Demystifying Internet of Things Security: Successful IoT Device/Edge and Platform Security Deployment Sunil Cheruvu Anil Kumar Chandler, AZ, USA Chandler, AZ, USA Ned Smith David M. Wheeler Beaverton, OR, USA Gilbert, AZ, USA ISBN-13 (pbk): 978-1-4842-2895-1 ISBN-13 (electronic): 978-1-4842-2896-8 https://doi.org/10.1007/978-1-4842-2896-8 Copyright © 2020 by The Editor(s) (if applicable) and The Author(s) This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Open Access This book is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made. The images or other third party material in this book are included in the book’s Creative Commons license, unless indicated otherwise in a credit line to the material. -
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK -

Computer Architectures
Parallel (High-Performance) Computer Architectures Tarek El-Ghazawi Department of Electrical and Computer Engineering The George Washington University Tarek El-Ghazawi, Introduction to High-Performance Computing slide 1 Introduction to Parallel Computing Systems Outline Definitions and Conceptual Classifications » Parallel Processing, MPP’s, and Related Terms » Flynn’s Classification of Computer Architectures Operational Models for Parallel Computers Interconnection Networks MPP’s Performance Tarek El-Ghazawi, Introduction to High-Performance Computing slide 2 Definitions and Conceptual Classification What is Parallel Processing? - A form of data processing which emphasizes the exploration and exploitation of inherent parallelism in the underlying problem. Other related terms » Massively Parallel Processors » Heterogeneous Processing – In the1990s, heterogeneous workstations from different processor vendors – Now, accelerators such as GPUs, FPGAs, Intel’s Xeon Phi, … » Grid computing » Cloud Computing Tarek El-Ghazawi, Introduction to High-Performance Computing slide 3 Definitions and Conceptual Classification Why Massively Parallel Processors (MPPs)? » Increase processing speed and memory allowing studies of problems with higher resolutions or bigger sizes » Provide a low cost alternative to using expensive processor and memory technologies (as in traditional vector machines) Tarek El-Ghazawi, Introduction to High-Performance Computing slide 4 Stored Program Computer The IAS machine was the first electronic computer developed, under -

Reverse Engineering X86 Processor Microcode
Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz, Ruhr-University Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/koppe This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz Ruhr-Universitat¨ Bochum Abstract hardware modifications [48]. Dedicated hardware units to counter bugs are imperfect [36, 49] and involve non- Microcode is an abstraction layer on top of the phys- negligible hardware costs [8]. The infamous Pentium fdiv ical components of a CPU and present in most general- bug [62] illustrated a clear economic need for field up- purpose CPUs today. In addition to facilitate complex and dates after deployment in order to turn off defective parts vast instruction sets, it also provides an update mechanism and patch erroneous behavior. Note that the implementa- that allows CPUs to be patched in-place without requiring tion of a modern processor involves millions of lines of any special hardware. While it is well-known that CPUs HDL code [55] and verification of functional correctness are regularly updated with this mechanism, very little is for such processors is still an unsolved problem [4, 29]. known about its inner workings given that microcode and the update mechanism are proprietary and have not been Since the 1970s, x86 processor manufacturers have throughly analyzed yet. -

Control Unit Operation
PART SIX: THE CONTROL UNIT CHAPTER 19 CONTROL UNIT OPERATION 19.1 MICRO-OPERATIONS ............................................................... 3 The Fetch Cycle ...................................................................... 5 The Indirect Cycle................................................................... 8 The Interrupt Cycle ................................................................. 9 The Execute Cycle................................................................... 9 The Instruction Cycle............................................................. 12 19.2 CONTROL OF THE PROCESSOR ............................................... 13 Functional Requirements........................................................ 13 Control Signals ..................................................................... 16 A Control Signals Example ..................................................... 19 Internal Processor Organization .............................................. 23 The Intel 8085...................................................................... 24 19.3 HARDWIRED IMPLEMENTATION .............................................. 30 Control Unit Inputs ............................................................... 30 Control Unit Logic ................................................................. 33 19.4 RECOMMENDED READING ...................................................... 35 19.5 KEY TERMS, REVIEW QUESTIONS, AND PROBLEMS ................... 35 Key Terms .......................................................................... -

UTP Cable Connectors
Computer Architecture Prof. Dr. Nizamettin AYDIN [email protected] MIPS ISA - I [email protected] http://www.yildiz.edu.tr/~naydin 1 2 Outline Computer Architecture • Overview of the MIPS architecture • can be viewed as – ISA vs Microarchitecture? – the machine language the CPU implements – CISC vs RISC • Instruction set architecture (ISA) – Basics of MIPS – Built in data types (integers, floating point numbers) – Components of the MIPS architecture – Fixed set of instructions – Fixed set of on-processor variables (registers) – Datapath and control unit – Interface for reading/writing memory – Memory – Mechanisms to do input/output – Memory addressing issue – how the ISA is implemented – Other components of the datapath • Microarchitecture – Control unit 3 4 Computer Architecture MIPS Architecture • Microarchitecture • MIPS – An acronym for Microprocessor without Interlocking Pipeline Stages – Not to be confused with a unit of computing speed equivalent to a Million Instructions Per Second • MIPS processor – born in the early 1980s from the work done by John Hennessy and his students at Stanford University • exploring the architectural concept of RISC – Originally used in Unix workstations, – now mainly used in small devices • Play Station, routers, printers, robots, cameras 5 6 Copyright 2000 N. AYDIN. All rights reserved. 1 MIPS Architecture CISC vs RISC • Designer MIPS Technologies, Imagination Technologies • Advantages of CISC Architecture: • Bits 64-bit (32 → 64) • Introduced 1985; – Microprogramming is easy to implement and much • Version MIPS32/64 Release 6 (2014) less expensive than hard wiring a control unit. • Design RISC – It is easy to add new commands into the chip without • Type Register-Register changing the structure of the instruction set as the • Encoding Fixed architecture uses general-purpose hardware to carry out • Branching Compare and branch commands. -

IBM Z Connectivity Handbook
Front cover IBM Z Connectivity Handbook Octavian Lascu John Troy Anna Shugol Frank Packheiser Kazuhiro Nakajima Paul Schouten Hervey Kamga Jannie Houlbjerg Bo XU Redbooks IBM Redbooks IBM Z Connectivity Handbook August 2020 SG24-5444-20 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. Twentyfirst Edition (August 2020) This edition applies to connectivity options available on the IBM z15 (M/T 8561), IBM z15 (M/T 8562), IBM z14 (M/T 3906), IBM z14 Model ZR1 (M/T 3907), IBM z13, and IBM z13s. © Copyright International Business Machines Corporation 2020. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix Authors. ix Now you can become a published author, too! . xi Comments welcome. xi Stay connected to IBM Redbooks . xi Chapter 1. Introduction. 1 1.1 I/O channel overview. 2 1.1.1 I/O hardware infrastructure . 2 1.1.2 I/O connectivity features . 3 1.2 FICON Express . 4 1.3 zHyperLink Express . 5 1.4 Open Systems Adapter-Express. 6 1.5 HiperSockets. 7 1.6 Parallel Sysplex and coupling links . 8 1.7 Shared Memory Communications. 9 1.8 I/O feature support . 10 1.9 Special-purpose feature support . 12 1.9.1 Crypto Express features . 12 1.9.2 Flash Express feature . 12 1.9.3 zEDC Express feature . 13 Chapter 2. Channel subsystem overview . 15 2.1 CSS description . 16 2.1.1 CSS elements .