CPS 303 High Performance Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -
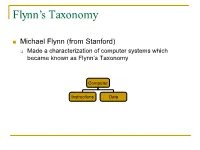
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK -

Computer Architectures
Parallel (High-Performance) Computer Architectures Tarek El-Ghazawi Department of Electrical and Computer Engineering The George Washington University Tarek El-Ghazawi, Introduction to High-Performance Computing slide 1 Introduction to Parallel Computing Systems Outline Definitions and Conceptual Classifications » Parallel Processing, MPP’s, and Related Terms » Flynn’s Classification of Computer Architectures Operational Models for Parallel Computers Interconnection Networks MPP’s Performance Tarek El-Ghazawi, Introduction to High-Performance Computing slide 2 Definitions and Conceptual Classification What is Parallel Processing? - A form of data processing which emphasizes the exploration and exploitation of inherent parallelism in the underlying problem. Other related terms » Massively Parallel Processors » Heterogeneous Processing – In the1990s, heterogeneous workstations from different processor vendors – Now, accelerators such as GPUs, FPGAs, Intel’s Xeon Phi, … » Grid computing » Cloud Computing Tarek El-Ghazawi, Introduction to High-Performance Computing slide 3 Definitions and Conceptual Classification Why Massively Parallel Processors (MPPs)? » Increase processing speed and memory allowing studies of problems with higher resolutions or bigger sizes » Provide a low cost alternative to using expensive processor and memory technologies (as in traditional vector machines) Tarek El-Ghazawi, Introduction to High-Performance Computing slide 4 Stored Program Computer The IAS machine was the first electronic computer developed, under -

UTP Cable Connectors
Computer Architecture Prof. Dr. Nizamettin AYDIN [email protected] MIPS ISA - I [email protected] http://www.yildiz.edu.tr/~naydin 1 2 Outline Computer Architecture • Overview of the MIPS architecture • can be viewed as – ISA vs Microarchitecture? – the machine language the CPU implements – CISC vs RISC • Instruction set architecture (ISA) – Basics of MIPS – Built in data types (integers, floating point numbers) – Components of the MIPS architecture – Fixed set of instructions – Fixed set of on-processor variables (registers) – Datapath and control unit – Interface for reading/writing memory – Memory – Mechanisms to do input/output – Memory addressing issue – how the ISA is implemented – Other components of the datapath • Microarchitecture – Control unit 3 4 Computer Architecture MIPS Architecture • Microarchitecture • MIPS – An acronym for Microprocessor without Interlocking Pipeline Stages – Not to be confused with a unit of computing speed equivalent to a Million Instructions Per Second • MIPS processor – born in the early 1980s from the work done by John Hennessy and his students at Stanford University • exploring the architectural concept of RISC – Originally used in Unix workstations, – now mainly used in small devices • Play Station, routers, printers, robots, cameras 5 6 Copyright 2000 N. AYDIN. All rights reserved. 1 MIPS Architecture CISC vs RISC • Designer MIPS Technologies, Imagination Technologies • Advantages of CISC Architecture: • Bits 64-bit (32 → 64) • Introduced 1985; – Microprogramming is easy to implement and much • Version MIPS32/64 Release 6 (2014) less expensive than hard wiring a control unit. • Design RISC – It is easy to add new commands into the chip without • Type Register-Register changing the structure of the instruction set as the • Encoding Fixed architecture uses general-purpose hardware to carry out • Branching Compare and branch commands. -

Assembly Language: IA-X86
Assembly Language for x86 Processors X86 Processor Architecture CS 271 Computer Architecture Purdue University Fort Wayne 1 Outline Basic IA Computer Organization IA-32 Registers Instruction Execution Cycle Basic IA Computer Organization Since the 1940's, the Von Neumann computers contains three key components: Processor, called also the CPU (Central Processing Unit) Memory and Storage Devices I/O Devices Interconnected with one or more buses Data Bus Address Bus data bus Control Bus registers Processor I/O I/O IA: Intel Architecture Memory Device Device (CPU) #1 #2 32-bit (or i386) ALU CU clock control bus address bus Processor The processor consists of Datapath ALU Registers Control unit ALU (Arithmetic logic unit) Performs arithmetic and logic operations Control unit (CU) Generates the control signals required to execute instructions Memory Address Space Address Space is the set of memory locations (bytes) that are addressable Next ... Basic Computer Organization IA-32 Registers Instruction Execution Cycle Registers Registers are high speed memory inside the CPU Eight 32-bit general-purpose registers Six 16-bit segment registers Processor Status Flags (EFLAGS) and Instruction Pointer (EIP) 32-bit General-Purpose Registers EAX EBP EBX ESP ECX ESI EDX EDI 16-bit Segment Registers EFLAGS CS ES SS FS EIP DS GS General-Purpose Registers Used primarily for arithmetic and data movement mov eax 10 ;move constant integer 10 into register eax Specialized uses of Registers eax – Accumulator register Automatically -

Lecture #2 "Computer Systems Big Picture"
18-600 Foundations of Computer Systems Lecture 2: “Computer Systems: The Big Picture” John P. Shen & Gregory Kesden 18-600 August 30, 2017 CS: AAP CS: APP ➢ Recommended Reference: ❖ Chapters 1 and 2 of Shen and Lipasti (SnL). ➢ Other Relevant References: ❖ “A Detailed Analysis of Contemporary ARM and x86 Architectures” by Emily Blem, Jaikrishnan Menon, and Karthikeyan Sankaralingam . (2013) ❖ “Amdahl’s and Gustafson’s Laws Revisited” by Andrzej Karbowski. (2008) 8/30/2017 (©J.P. Shen) 18-600 Lecture #2 1 18-600 Foundations of Computer Systems Lecture 2: “Computer Systems: The Big Picture” 1. Instruction Set Architecture (ISA) a. Hardware / Software Interface (HSI) b. Dynamic / Static Interface (DSI) c. Instruction Set Architecture Design & Examples 2. Historical Perspective on Computing a. Major Epochs of Modern Computers b. Computer Performance Iron Law (#1) 3. “Economics” of Computer Systems a. Amdahl’s Law and Gustafson’s Law b. Moore’s Law and Bell’s Law 8/30/2017 (©J.P. Shen) 18-600 Lecture #2 2 Anatomy of Engineering Design SPECIFICATION: Behavioral description of “What does it do?” Synthesis: Search for possible solutions; pick best one. Creative process IMPLEMENTATION: Structural description of “How is it constructed?” Analysis: Validate if the design meets the specification. “Does it do the right thing?” + “How well does it perform?” 8/30/2017 (©J.P. Shen) 18-600 Lecture #2 3 [Gerrit Blaauw & Fred Brooks, 1981] Instruction Set Processor Design ARCHITECTURE: (ISA) programmer/compiler view = SPECIFICATION • Functional programming model to application/system programmers • Opcodes, addressing modes, architected registers, IEEE floating point IMPLEMENTATION: (μarchitecture) processor designer view • Logical structure or organization that performs the ISA specification • Pipelining, functional units, caches, physical registers, buses, branch predictors REALIZATION: (Chip) chip/system designer view • Physical structure that embodies the implementation • Gates, cells, transistors, wires, dies, packaging 8/30/2017 (©J.P. -

Evaluation of Synthesizable CPU Cores
Evaluation of synthesizable CPU cores DANIEL MATTSSON MARCUS CHRISTENSSON Maste r ' s Thesis Com p u t e r Science an d Eng i n ee r i n g Pro g r a m CHALMERS UNIVERSITY OF TECHNOLOGY Depart men t of Computer Engineering Gothe n bu r g 20 0 4 All rights reserved. This publication is protected by law in accordance with “Lagen om Upphovsrätt, 1960:729”. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of the authors. Daniel Mattsson and Marcus Christensson, Gothenburg 2004. Evaluation of synthesizable CPU cores Abstract The three synthesizable processors: LEON2 from Gaisler Research, MicroBlaze from Xilinx, and OpenRISC 1200 from OpenCores are evaluated and discussed. Performance in terms of benchmark results and area resource usage is measured. Different aspects like usability and configurability are also reviewed. Three configurations for each of the processors are defined and evaluated: the comparable configuration, the performance optimized configuration and the area optimized configuration. For each of the configurations three benchmarks are executed: the Dhrystone 2.1 benchmark, the Stanford benchmark suite and a typical control application run as a benchmark. A detailed analysis of the three processors and their development tools is presented. The three benchmarks are described and motivated. Conclusions and results in terms of benchmark results, performance per clock cycle and performance per area unit are discussed and presented. Sammanfattning De tre syntetiserbara processorerna: LEON2 från Gaisler Research, MicroBlaze från Xilinx och OpenRISC 1200 från OpenCores utvärderas och diskuteras. -
![MIPS Architecture with Tomasulo Algorithm [12]](https://docslib.b-cdn.net/cover/1642/mips-architecture-with-tomasulo-algorithm-12-1591642.webp)
MIPS Architecture with Tomasulo Algorithm [12]
CALIFORNIA STATE UNIVERSITY NORTHRIDGE TOMASULO ARCHITECTURE BASED MIPS PROCESSOR A graduate project submitted in partial fulfilment for the requirement Of the degree of Master of Science In Electrical Engineering By Sameer S Pandit May 2014 The graduate project of Sameer Pandit is approved by: ______________________________________ ____________ Dr. Ali Amini, Ph.D. Date _______________________________________ ____________ Dr. Shahnam Mirzaei, Ph.D. Date _______________________________________ ____________ Dr. Ramin Roosta, Ph.D., Chair Date California State University Northridge ii ACKNOWLEDGEMENT I would like to express my gratitude towards all the members of the project committee and would like to thank them for their continuous support and mentoring me for every step that I have taken towards the completion of this project. Dr. Roosta, for his guidance, Dr. Shahnam for his ideas, and Dr. Ali Amini for his utmost support. I would also like to thank my family and friends for their love, care and support through all the tough times during my graduation. iii Table of Contents SIGNATURE PAGE .......................................................................................................... ii ACKNOWLEDGEMENT ................................................................................................. iii LIST OF FIGURES .......................................................................................................... vii ABSTRACT ....................................................................................................................... -

Chapter 1 + Basic Concepts and Computer Evolution Computer Architecture 2 Computer Organization
1 Chapter 1 + Basic Concepts and Computer Evolution Computer Architecture 2 Computer Organization • Attributes of a • Instruction set, system visible to number of bits used to represent various the programmer data types, I/O • Have a direct mechanisms, impact on the techniques for logical execution addressing memory of a program Architectural Computer attributes Architecture include: Organizational Computer attributes Organization include: • The operational • Hardware details units and their transparent to the interconnections programmer, control that realize the signals, interfaces between the computer and architectural peripherals, memory specifications technology used + IBM System 370 Architecture 3 ◼ IBM System/370 architecture ◼ Was introduced in 1970 ◼ Included a number of models ◼ Could upgrade to a more expensive, faster model without having to abandon original software ◼ New models are introduced with improved technology, but retain the same architecture so that the customer’s software investment is protected ◼ Architecture has survived to this day as the architecture of IBM’s mainframe product line System/370-145 system console. + 4 Structure and Function ◼Structure ◼ The way in which ◼ Hierarchical system components relate to each other ◼ Set of interrelated subsystems ◼Function ◼ Hierarchical nature of complex ◼ The operation of individual systems is essential to both components as part of the their design and their structure description ◼ Designer need only deal with a particular level of the system at a time ◼ Concerned