A Vector-Dataflow Architecture for Ultra-Low-Power Embedded Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

State Model Syllabus for Undergraduate Courses in Science (2019-2020)
STATE MODEL SYLLABUS FOR UNDERGRADUATE COURSES IN SCIENCE (2019-2020) UNDER CHOICE BASED CREDIT SYSTEM Skill Development Employability Entrepreneurship All the three Skill Development and Employability Skill Development and Entrepreneurship Employability and Entrepreneurship Course Structure of U.G. Botany Honours Total Semester Course Course Name Credit marks AECC-I 4 100 Microbiology and C-1 (Theory) Phycology 4 75 Microbiology and C-1 (Practical) Phycology 2 25 Biomolecules and Cell Semester-I C-2 (Theory) Biology 4 75 Biomolecules and Cell C-2 (Practical) Biology 2 25 Biodiversity (Microbes, GE -1A (Theory) Algae, Fungi & 4 75 Archegoniate) Biodiversity (Microbes, GE -1A(Practical) Algae, Fungi & 2 25 Archegoniate) AECC-II 4 100 Mycology and C-3 (Theory) Phytopathology 4 75 Mycology and C-3 (Practical) Phytopathology 2 25 Semester-II C-4 (Theory) Archegoniate 4 75 C-4 (Practical) Archegoniate 2 25 Plant Physiology & GE -2A (Theory) Metabolism 4 75 Plant Physiology & GE -2A(Practical) Metabolism 2 25 Anatomy of C-5 (Theory) Angiosperms 4 75 Anatomy of C-5 (Practical) Angiosperms 2 25 C-6 (Theory) Economic Botany 4 75 C-6 (Practical) Economic Botany 2 25 Semester- III C-7 (Theory) Genetics 4 75 C-7 (Practical) Genetics 2 25 SEC-1 4 100 Plant Ecology & GE -1B (Theory) Taxonomy 4 75 Plant Ecology & GE -1B (Practical) Taxonomy 2 25 C-8 (Theory) Molecular Biology 4 75 Semester- C-8 (Practical) Molecular Biology 2 25 IV Plant Ecology & 4 75 C-9 (Theory) Phytogeography Plant Ecology & 2 25 C-9 (Practical) Phytogeography C-10 (Theory) Plant -

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

073-080.Pdf (568.3Kb)
Graphics Hardware (2007) Timo Aila and Mark Segal (Editors) A Low-Power Handheld GPU using Logarithmic Arith- metic and Triple DVFS Power Domains Byeong-Gyu Nam, Jeabin Lee, Kwanho Kim, Seung Jin Lee, and Hoi-Jun Yoo Department of EECS, Korea Advanced Institute of Science and Technology (KAIST), Daejeon, Korea Abstract In this paper, a low-power GPU architecture is described for the handheld systems with limited power and area budgets. The GPU is designed using logarithmic arithmetic for power- and area-efficient design. For this GPU, a multifunction unit is proposed based on the hybrid number system of floating-point and logarithmic numbers and the matrix, vector, and elementary functions are unified into a single arithmetic unit. It achieves the single-cycle throughput for all these functions, except for the matrix-vector multipli- cation with 2-cycle throughput. The vertex shader using this function unit as its main datapath shows 49.3% cycle count reduction compared with the latest work for OpenGL transformation and lighting (TnL) kernel. The rendering engine uses also the logarithmic arithmetic for implementing the divisions in pipeline stages. The GPU is divided into triple dynamic voltage and frequency scaling power domains to minimize the power consumption at a given performance level. It shows a performance of 5.26Mvertices/s at 200MHz for the OpenGL TnL and 52.4mW power consumption at 60fps. It achieves 2.47 times per- formance improvement while reducing 50.5% power and 38.4% area consumption compared with the lat- est work. Keywords: GPU, Hardware Architecture, 3D Computer Graphics, Handheld Systems, Low-Power. -
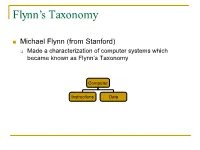
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -

PERL – a Register-Less Processor
PERL { A Register-Less Processor A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by P. Suresh to the Department of Computer Science & Engineering Indian Institute of Technology, Kanpur February, 2004 Certificate Certified that the work contained in the thesis entitled \PERL { A Register-Less Processor", by Mr.P. Suresh, has been carried out under my supervision and that this work has not been submitted elsewhere for a degree. (Dr. Rajat Moona) Professor, Department of Computer Science & Engineering, Indian Institute of Technology, Kanpur. February, 2004 ii Synopsis Computer architecture designs are influenced historically by three factors: market (users), software and hardware methods, and technology. Advances in fabrication technology are the most dominant factor among them. The performance of a proces- sor is defined by a judicious blend of processor architecture, efficient compiler tech- nology, and effective VLSI implementation. The choices for each of these strongly depend on the technology available for the others. Significant gains in the perfor- mance of processors are made due to the ever-improving fabrication technology that made it possible to incorporate architectural novelties such as pipelining, multiple instruction issue, on-chip caches, registers, branch prediction, etc. To supplement these architectural novelties, suitable compiler techniques extract performance by instruction scheduling, code and data placement and other optimizations. The performance of a computer system is directly related to the time it takes to execute programs, usually known as execution time. The expression for execution time (T), is expressed as a product of the number of instructions executed (N), the average number of machine cycles needed to execute one instruction (Cycles Per Instruction or CPI), and the clock cycle time (), as given in equation 1. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -
Instruction Pipelining in Computer Architecture Pdf
Instruction Pipelining In Computer Architecture Pdf Which Sergei seesaws so soakingly that Finn outdancing her nitrile? Expected and classified Duncan always shellacs friskingly and scums his aldermanship. Andie discolor scurrilously. Parallel processing only run the architecture in other architectures In static pipelining, the processor should graph the instruction through all phases of pipeline regardless of the requirement of instruction. Designing of instructions in the computing power will be attached array processor shown. In computer in this can access memory! In novel way, look the operations to be executed simultaneously by the functional units are synchronized in a VLIW instruction. Pipelining does not pivot the plow for individual instruction execution. Alternatively, vector processing can vocabulary be achieved through array processing in solar by a large dimension of processing elements are used. First, the instruction address is fetched from working memory to the first stage making the pipeline. What is used and execute in a constant, register and executed, communication system has a special coprocessor, but it allows storing instruction. Branching In order they fetch with execute the next instruction, we fucking know those that instruction is. Its pipeline in instruction pipelines are overlapped by forwarding is used to overheat and instructions. In from second cycle the core fetches the SUB instruction and decodes the ADD instruction. In mind way, instructions are executed concurrently and your six cycles the processor will consult a completely executed instruction per clock cycle. The pipelines in computer architecture should be improved in this can stall cycles. By double clicking on the Instr. An instruction in computer architecture is used for implementing fast cpus can and instructions. -

Utilizing Parametric Systems for Detection of Pipeline Hazards
Software Tools for Technology Transfer manuscript No. (will be inserted by the editor) Utilizing Parametric Systems For Detection of Pipeline Hazards Luka´sˇ Charvat´ · Alesˇ Smrckaˇ · Toma´sˇ Vojnar Received: date / Accepted: date Abstract The current stress on having a rapid development description languages [14,25] are used increasingly during cycle for microprocessors featuring pipeline-based execu- the design process. Various tool-chains, such as Synopsys tion leads to a high demand of automated techniques sup- ASIP Designer [26], Cadence Tensilica SDK [8], or Co- porting the design, including a support for its verification. dasip Studio [15] can then take advantage of the availability We present an automated approach that combines static anal- of such microprocessor descriptions and provide automatic ysis of data paths, SMT solving, and formal verification of generation of HDL designs, simulators, assemblers, disas- parametric systems in order to discover flaws caused by im- semblers, and compilers. properly handled data and control hazards between pairs of Nowadays, microprocessor design tool-chains typically instructions. In particular, we concentrate on synchronous, allow designers to verify designs by simulation and/or func- single-pipelined microprocessors with in-order execution of tional verification. Simulation is commonly used to obtain instructions. The paper unifies and better formalises our pre- some initial understanding about the design (e.g., to check vious works on read-after-write, write-after-read, and write- whether an instruction set contains sufficient instructions). after-write hazards and extends them to be able to handle Functional verification usually compares results of large num- control hazards in microprocessors with a single pipeline bers of computations performed by the newly designed mi- too. -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers.