Computer Architecture: Dataflow (Part I)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Performance and Energy Efficient Network-On-Chip Architectures
Linköping Studies in Science and Technology Dissertation No. 1130 Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 ISBN 978-91-85895-91-5 ISSN 0345-7524 ii Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal ISBN 978-91-85895-91-5 Copyright Sriram. R. Vangal, 2007 Linköping Studies in Science and Technology Dissertation No. 1130 ISSN 0345-7524 Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 Author email: [email protected] Cover Image A chip microphotograph of the industry’s first programmable 80-tile teraFLOPS processor, which is implemented in a 65-nm eight-metal CMOS technology. Printed by LiU-Tryck, Linköping University Linköping, Sweden, 2007 Abstract The scaling of MOS transistors into the nanometer regime opens the possibility for creating large Network-on-Chip (NoC) architectures containing hundreds of integrated processing elements with on-chip communication. NoC architectures, with structured on-chip networks are emerging as a scalable and modular solution to global communications within large systems-on-chip. NoCs mitigate the emerging wire-delay problem and addresses the need for substantial interconnect bandwidth by replacing today’s shared buses with packet-switched router networks. With on-chip communication consuming a significant portion of the chip power and area budgets, there is a compelling need for compact, low power routers. While applications dictate the choice of the compute core, the advent of multimedia applications, such as three-dimensional (3D) graphics and signal processing, places stronger demands for self-contained, low-latency floating-point processors with increased throughput. -

CS 2210: Theory of Computation
CS 2210: Theory of Computation Spring, 2019 Administrative Information • Background survey • Textbook: E. Rich, Automata, Computability, and Complexity: Theory and Applications, Prentice-Hall, 2008. • Book website: http://www.cs.utexas.edu/~ear/cs341/automatabook/ • My Office Hours: – Monday, 6:00-8:00pm, Searles 224 – Tuesday, 1:00-2:30pm, Searles 222 • TAs – Anjulee Bhalla: Hours TBA, Searles 224 – Ryan St. Pierre, Hours TBA, Searles 224 What you can expect from the course • How to do proofs • Models of computation • What’s the difference between computability and complexity? • What’s the Halting Problem? • What are P and NP? • Why do we care whether P = NP? • What are NP-complete problems? • Where does this make a difference outside of this class? • How to work the answers to these questions into the conversation at a cocktail party… What I will expect from you • Problem Sets (25%): – Goal: Problems given on Mondays and Wednesdays – Due the next Monday – Graded by following Monday – A learning tool, not a testing tool – Collaboration encouraged; more on this in next slide • Quizzes (15%) • Exams (2 non-cumulative, 30% each): – Closed book, closed notes, but… – Can bring in 8.5 x 11 page with notes on both sides • Class participation: Tiebreaker Other Important Things • Go to the TA hours • Study and work on problem sets in groups • Collaboration Issues: – Level 0 (In-Class Problems) • No restrictions – Level 1 (Homework Problems) • Verbal collaboration • But, individual write-ups – Level 2 (not used in this course) • Discussion with TAs only – Level 3 (Exams) • Professor clarifications only Right now… • What does it mean to study the “theory” of something? • Experience with theory in other disciplines? • Relationship to practice? – “In theory, theory and practice are the same. -

The Problem with Threads
The Problem with Threads Edward A. Lee Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2006-1 http://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-1.html January 10, 2006 Copyright © 2006, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. Acknowledgement This work was supported in part by the Center for Hybrid and Embedded Software Systems (CHESS) at UC Berkeley, which receives support from the National Science Foundation (NSF award No. CCR-0225610), the State of California Micro Program, and the following companies: Agilent, DGIST, General Motors, Hewlett Packard, Infineon, Microsoft, and Toyota. The Problem with Threads Edward A. Lee Professor, Chair of EE, Associate Chair of EECS EECS Department University of California at Berkeley Berkeley, CA 94720, U.S.A. [email protected] January 10, 2006 Abstract Threads are a seemingly straightforward adaptation of the dominant sequential model of computation to concurrent systems. Languages require little or no syntactic changes to sup- port threads, and operating systems and architectures have evolved to efficiently support them. Many technologists are pushing for increased use of multithreading in software in order to take advantage of the predicted increases in parallelism in computer architectures. -

Ece585 Lec2.Pdf
ECE 485/585 Microprocessor System Design Lecture 2: Memory Addressing 8086 Basics and Bus Timing Asynchronous I/O Signaling Zeshan Chishti Electrical and Computer Engineering Dept Maseeh College of Engineering and Computer Science Source: Lecture based on materials provided by Mark F. Basic I/O – Part I ECE 485/585 Outline for next few lectures Simple model of computation Memory Addressing (Alignment, Byte Order) 8088/8086 Bus Asynchronous I/O Signaling Review of Basic I/O How is I/O performed Dedicated/Isolated /Direct I/O Ports Memory Mapped I/O How do we tell when I/O device is ready or command complete? Polling Interrupts How do we transfer data? Programmed I/O DMA ECE 485/585 Simplified Model of a Computer Control Control Data, Address, Memory Data Path Microprocessor Keyboard Mouse [Fetch] Video display [Decode] Printer [Execute] I/O Device Hard disk drive Audio card Ethernet WiFi CD R/W DVD ECE 485/585 Memory Addressing Size of operands Bytes, words, long/double words, quadwords 16-bit half word (Intel: word) 32-bit word (Intel: doubleword, dword) 0x107 64-bit double word (Intel: quadword, qword) 0x106 Note: names are non-standard 0x105 SUN Sparc word is 32-bits, double is 64-bits 0x104 0x103 Alignment 0x102 Can multi-byte operands begin at any byte address? 0x101 Yes: non-aligned 0x100 No: aligned. Low order address bit(s) will be zero ECE 485/585 Memory Operand Alignment …Intel IA speak (i.e. word = 16-bits = 2 bytes) 0x107 0x106 0x105 0x104 0x103 0x102 0x101 0x100 Aligned Unaligned Aligned Unaligned Aligned Unaligned word word Double Double Quad Quad address address word word word word -----0 address address address address -----00 ----000 ECE 485/585 Memory Operand Alignment Why do we care? Unaligned memory references Can cause multiple memory bus cycles for a single operand May also span cache lines Requiring multiple evictions, multiple cache line fills Complicates memory system and cache controller design Some architectures restrict addresses to be aligned Even in architectures without alignment restrictions (e.g. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -

10. Assembly Language, Models of Computation
10. Assembly Language, Models of Computation 6.004x Computation Structures Part 2 – Computer Architecture Copyright © 2015 MIT EECS 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #1 Beta ISA Summary • Storage: – Processor: 32 registers (r31 hardwired to 0) and PC – Main memory: Up to 4 GB, 32-bit words, 32-bit byte addresses, 4-byte-aligned accesses OPCODE rc ra rb unused • Instruction formats: OPCODE rc ra 16-bit signed constant 32 bits • Instruction classes: – ALU: Two input registers, or register and constant – Loads and stores: access memory – Branches, Jumps: change program counter 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #2 Programming Languages 32-bit (4-byte) ADD instruction: 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 opcode rc ra rb (unused) Means, to the BETA, Reg[4] ß Reg[2] + Reg[3] We’d rather write in assembly language: Today ADD(R2, R3, R4) or better yet a high-level language: Coming up a = b + c; 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #3 Assembly Language Symbolic 01101101 11000110 Array of bytes representation Assembler 00101111 to be loaded of stream of bytes 10110001 into memory ..... Source Binary text file machine language • Abstracts bit-level representation of instructions and addresses • We’ll learn UASM (“microassembler”), built into BSim • Main elements: – Values – Symbols – Labels (symbols for addresses) – Macros 6.004 Computation Structures L10: Assembly Language, Models -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers. -

Actor Model of Computation
Published in ArXiv http://arxiv.org/abs/1008.1459 Actor Model of Computation Carl Hewitt http://carlhewitt.info This paper is dedicated to Alonzo Church and Dana Scott. The Actor model is a mathematical theory that treats “Actors” as the universal primitives of concurrent digital computation. The model has been used both as a framework for a theoretical understanding of concurrency, and as the theoretical basis for several practical implementations of concurrent systems. Unlike previous models of computation, the Actor model was inspired by physical laws. It was also influenced by the programming languages Lisp, Simula 67 and Smalltalk-72, as well as ideas for Petri Nets, capability-based systems and packet switching. The advent of massive concurrency through client- cloud computing and many-core computer architectures has galvanized interest in the Actor model. An Actor is a computational entity that, in response to a message it receives, can concurrently: send a finite number of messages to other Actors; create a finite number of new Actors; designate the behavior to be used for the next message it receives. There is no assumed order to the above actions and they could be carried out concurrently. In addition two messages sent concurrently can arrive in either order. Decoupling the sender from communications sent was a fundamental advance of the Actor model enabling asynchronous communication and control structures as patterns of passing messages. November 7, 2010 Page 1 of 25 Contents Introduction ............................................................ 3 Fundamental concepts ............................................ 3 Illustrations ............................................................ 3 Modularity thru Direct communication and asynchrony ............................................................. 3 Indeterminacy and Quasi-commutativity ............... 4 Locality and Security ............................................ -

Configurable Fine-Grain Protection for Multicore Processor Virtualization 1
Configurable Fine-Grain Protection for Multicore Processor Virtualization David Wentzlaff1, Christopher J. Jackson2, Patrick Griffin3, and Anant Agarwal2 [email protected], [email protected], griffi[email protected], [email protected] 1Princeton University 2Tilera Corp. 3Google Inc. Abstract TLB Access DMA Engine “User” Network I/O Network 2 2 2 2 1 3 1 3 1 3 1 3 Multicore architectures, with their abundant on-chip re- 0 0 0 0 sources, are effectively collections of systems-on-a-chip. The protection system for these architectures must support Key: 0 – User Code, 1 – OS, 2 – Hypervisor, 3 – Hypervisor Debugger multiple concurrently executing operating systems (OSes) Figure 1. With CFP, system software can dy• with different needs, and manage and protect the hard- namically set the privilege level needed to ac• ware’s novel communication mechanisms and hardware cess each fine•grain processor resource. features. Traditional protection systems are insufficient; they protect supervisor from user code, but typically do not protect one system from another, and only support fixed as- ticore systems, a protection system must both temporally signment of resources to protection levels. In this paper, protect and spatially isolate access to resources. Spatial iso- we propose an alternative to traditional protection systems lation is the need to isolate different system software stacks which we call configurable fine-grain protection (CFP). concurrently executing on spatially disparate cores in a mul- CFP enables the dynamic assignment of in-core resources ticore system. Spatial isolation is especially important now to protection levels. We investigate how CFP enables differ- that multicore systems have directly accessible networks ent system software stacks to utilize the same configurable connecting cores to other cores and cores to I/O devices. -
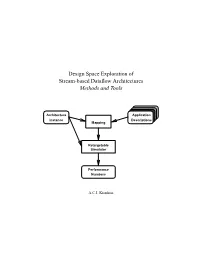
Design Space Exploration of Stream-Based Dataflow Architectures
Design Space Exploration of Stream-based Dataflow Architectures Methods and Tools Architecture Application Instance Descriptions Mapping Retargetable Simulator Performance Numbers A.C.J. Kienhuis Design Space Exploration of Stream-based Dataflow Architectures PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof.ir. K.F. Wakker, in het openbaar te verdedigen ten overstaan van een commissie, door het College voor Promoties aangewezen, op vrijdag 29 Januari 1999 te 10:30 uur door Albert Carl Jan KIENHUIS elektrotechnisch ingenieur geboren te Vleuten. Dit proefschrift is goedgekeurd door de promotor: Prof.dr.ir. P.M. Dewilde Toegevoegd promotor: Dr.ir. E.F. Deprettere. Samenstelling promotiecommissie: Rector Magnificus, voorzitter Prof.dr.ir. P.M. Dewilde, Technische Universiteit Delft, promotor Dr.ir. E.F. Deprettere, Technische Universiteit Delft, toegevoegd promotor Ir. K.A. Vissers, Philips Research Eindhoven Prof.dr.ir. J.L. van Meerbergen, Technische Universiteit Eindhoven Prof.Dr.-Ing. R. Ernst, Technische Universit¨at Braunschweig Prof.dr. S. Vassiliadis, Technische Universiteit Delft Prof.dr.ir. R.H.J.M. Otten, Technische Universiteit Delft Ir. K.A. Vissers en Dr.ir. P. van der Wolf van Philips Research Eindhoven, hebben als begeleiders in belangrijke mate aan de totstandkoming van het proefschrift bijgedragen. CIP-DATA KONINKLIJKE BIBLIOTHEEK, DEN HAAG Kienhuis, Albert Carl Jan Design Space Exploration of Stream-based Dataflow Architectures : Methods and Tools Albert Carl Jan Kienhuis. - Delft: Delft University of Technology Thesis Technische Universiteit Delft. - With index, ref. - With summary in Dutch ISBN 90-5326-029-3 Subject headings: IC-design; Data flow Computing; Systems Analysis Copyright c 1999 by A.C.J. -

Computer Architecture Lecture 1: Introduction and Basics Where We Are
Computer Architecture Lecture 1: Introduction and Basics Where we are “C” as a model of computation Programming Programmer’s view of a computer system works How does an assembly program end up executing as Architect/microarchitect’s view: digital logic? How to design a computer that meets system design goals. What happens in-between? Choices critically affect both How is a computer designed the SW programmer and using logic gates and wires the HW designer to satisfy specific goals? HW designer’s view of a computer system works CO Digital logic as a model of computation 2 Levels of Transformation “The purpose of computing is insight” (Richard Hamming) We gain and generate insight by solving problems How do we ensure problems are solved by electrons? Problem Algorithm Program/Language Runtime System (VM, OS, MM) ISA (Architecture) Microarchitecture Logic Circuits Electrons 3 The Power of Abstraction Levels of transformation create abstractions Abstraction: A higher level only needs to know about the interface to the lower level, not how the lower level is implemented E.g., high-level language programmer does not really need to know what the ISA is and how a computer executes instructions Abstraction improves productivity No need to worry about decisions made in underlying levels E.g., programming in Java vs. C vs. assembly vs. binary vs. by specifying control signals of each transistor every cycle Then, why would you want to know what goes on underneath or above? 4 Crossing the Abstraction Layers As long as everything goes well, not knowing what happens in the underlying level (or above) is not a problem. -

A Model of Computation for VLSI with Related Complexity Results
A Model of Computation for VLSI with Related Complexity Results BERNARD CHAZELLE AND LOUIS MONIER Carnegie-Mellon University, Pittsburgh, Pennsylvania Abstract. A new model of computation for VLSI, based on the assumption that time for propagating information is at least linear in the distance, is proposed. While accommodating for basic laws of physics, the model is designed to be general and technology independent. Thus, from a complexity viewpoint, it is especially suited for deriving lower bounds and trade-offs. New results for a number of problems, including fan-in, transitive functions, matrix multiplication, and sorting are presented. As regards upper bounds, it must be noted that, because of communication costs, the model clearly favors regular and pipelined architectures (e.g., systolic arrays). Categories and Subject Descriptors: B.7.1 [Integrated Circuits]: Types and Design Styles-%91 (very- large-scale integration) General Terms: Algorithms, Theory Additional Key Words and Phrases: Chip complexity, lower bounds 1. Introduction The importance of having general models of computation for very-large-scale integration (VLSI) is apparent for various reasons, chief of which are the need for evaluating and comparing circuit performance, establishing lower bounds and trade-offs on area, time, and energy, and, more generally, building a complexity theory of VLSI computation. Although models must be simple and general enough to allow for mathematical analysis, they must also reflect reality regardless of the size of the circuit. We justify the latter claim by observing that if today’s circuits are still relatively small, the use of high-level design languages combined with larger integration, bigger chips, and improved yield may make asymptotic analysis quite relevant in the near future.