Performance and Energy Efficient Network-On-Chip Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 5: Scaled MOSFETS for Ics
Lecture 5: Scaled MOSFETS for ICs MSE 6001, Semiconductor Materials Lectures Fall 2006 5 MOSFETS and scaling Silicon is a mediocre semiconductor, and several other semiconductors have better electrical and optical properties. However, the very high quality of the electrical properties of the silicon-silicon dioxide interface allows very good metal-oxide-semiconductor field-effect transistors (MOSFETs) to be fabricated. These devices have several properties, such as operation frequency and power con- sumption, that improve as their size is scaled down to smaller dimensions, which also allows more transistors to be packed onto a chip. The smaller sizes are achieved using higher-resolution pho- tolithography, which is improved by steadily improving the fabrication technologies. The trends of steadily improving performance and greater integration density with time are generically refered to A 70 Mbit SRAM test vehicle with >as0.5 “Moore’s billion trans Law”.istors Of course, scaling has to end eventually, somewhere before the scale of atoms and incorporating all of the features described in this paper has been fabricated on this technologyis. reached.The aggressive de- sign rules allow for a small 0.57Pm2 6-T SRAM cell that is also compatible with high performance logic processing. A top view of the cell after poly patterni5.1ng is show Basicn in Figur MOSFETe 12. In addition to small size, this cell has a robust static noise margin down to 0.7V VDD to alloMOSFETsw low voltage turnopera- on and off via the non-linear gate capacitor between the gate electrode and the tion (Fig. 13). Figure 14 is a Shmosubstrate.o plot for the The 70 M MOSFETb of Fig. -

By Erika Azabache Villar a Thesis Submitted in Partial Fulfillment of The
SMALLER/FASTER DELTA-SIGMA DIGITAL PIXEL SENSORS by Erika Azabache Villar A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Integrated Circuits and Systems Department of Electrical and Computer Engineering University of Alberta c Erika Azabache Villar, 2016 Abstract A digital pixel sensor (DPS) array is an image sensor where each pixel has an analog-to-digital converter (ADC). Recently, a logarithmic delta-sigma (ΔΣ) DPS array, using first-order ΔΣ ADCs, achieved wide dynamic range and high signal-to-noise-and-distortion ratios at video rates, requirements that are difficult to meet using conventional image sensors. However, this state-of-the-art ΔΣ DPS design is either too large for some applications, such as optical imag- ing, or too slow for others, such as gamma imaging. Consequently, this master’s thesis investi- gates smaller or faster ΔΣ DPS designs, relative to the state of the art. All designs are validated through simulations. Commercial image sensors, for optical and gamma imaging, are used as targeted baselines to establish competitive specifications. To achieve a smaller pixel, process scaling is exploited. Three logarithmic ΔΣ DPS designs are presented for 180, 130, and 65 nm fabrication processes, demonstrating a path to competitiveness for the optical imaging market. Decimator and readout circuits are improved, compared to previous work, while reducing area, and capacitors in the modulator prove to be the limiting factor in deep-submicron processes. Area trends are used to construct a roadmap to even smaller pixels. To achieve a faster pixel, a higher-order ΔΣ architecture is exploited. -

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -
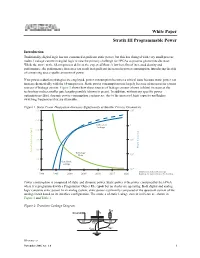
Stratix III Programmable Power
White Paper Stratix III Programmable Power Introduction Traditionally, digital logic has not consumed significant static power, but this has changed with very small process nodes. Leakage current in digital logic is now the primary challenge for FPGAs as process geometries decrease. While the move to the 65-nm process delivers the expected Moore's law benefits of increased density and performance, the performance increases can result in significant increases in power consumption, introducing the risk of consuming unacceptable amounts of power. If no power-reduction strategies are employed, power consumption becomes a critical issue because static power can increase dramatically with the 65-nm process. Static power consumption rises largely because of increases in various sources of leakage current. Figure 1 shows how these sources of leakage current (shown in blue) increase as the technology makes smaller gate lengths possible (shown in green). In addition, without any specific power optimization effort, dynamic power consumption can increase due to the increased logic capacity and higher switching frequencies that are attainable. Figure 1. Static Power Dissipation Increases Significantly at Smaller Process Geometries 300 100 250 Subthreshold 1 Leakage 200 150 10-2 Power Dissipation 100 Physical Gate Length [nm] Technology -4 Node 10 50 Gate-Oxide Leakage 0 10-6 Data from International Technology 1990 1995 2000 2005 2010 2015 2020 Roadmap for Semiconductors ITRS Roadmap Power consumption is composed of static and dynamic power. Static power is the power consumed by the FPGA when it is programmed with a Programmer Object File (.pof) but no clocks are operating. Both digital and analog logic consume static power. -

Configurable Fine-Grain Protection for Multicore Processor Virtualization 1
Configurable Fine-Grain Protection for Multicore Processor Virtualization David Wentzlaff1, Christopher J. Jackson2, Patrick Griffin3, and Anant Agarwal2 [email protected], [email protected], griffi[email protected], [email protected] 1Princeton University 2Tilera Corp. 3Google Inc. Abstract TLB Access DMA Engine “User” Network I/O Network 2 2 2 2 1 3 1 3 1 3 1 3 Multicore architectures, with their abundant on-chip re- 0 0 0 0 sources, are effectively collections of systems-on-a-chip. The protection system for these architectures must support Key: 0 – User Code, 1 – OS, 2 – Hypervisor, 3 – Hypervisor Debugger multiple concurrently executing operating systems (OSes) Figure 1. With CFP, system software can dy• with different needs, and manage and protect the hard- namically set the privilege level needed to ac• ware’s novel communication mechanisms and hardware cess each fine•grain processor resource. features. Traditional protection systems are insufficient; they protect supervisor from user code, but typically do not protect one system from another, and only support fixed as- ticore systems, a protection system must both temporally signment of resources to protection levels. In this paper, protect and spatially isolate access to resources. Spatial iso- we propose an alternative to traditional protection systems lation is the need to isolate different system software stacks which we call configurable fine-grain protection (CFP). concurrently executing on spatially disparate cores in a mul- CFP enables the dynamic assignment of in-core resources ticore system. Spatial isolation is especially important now to protection levels. We investigate how CFP enables differ- that multicore systems have directly accessible networks ent system software stacks to utilize the same configurable connecting cores to other cores and cores to I/O devices. -

CG-Ooo Energy-Efficient Coarse-Grain Out-Of-Order Execution
CG-OoO Energy-Efficient Coarse-Grain Out-of-Order Execution Milad Mohammadi⋆, Tor M. Aamodt†, William J. Dally⋆‡ ⋆Stanford University, †University of British Columbia, ‡NVIDIA Research [email protected], [email protected], [email protected] ABSTRACT CG-OoO model to make it even more energy efficient. We introduce the Coarse-Grain Out-of-Order (CG- Despite the significant achievements in improving en- OoO) general purpose processor designed to achieve ergy and performance properties of the OoO proces- close to In-Order processor energy while maintaining sor in the recent years [2], studies show the energy Out-of-Order (OoO) performance. CG-OoO is an and performance attributes of the OoO execution model energy-performance proportional general purpose remain superlinearly proportional [3, 4]. Studies indi- architecture that scales according to the program cate control speculation and dynamic scheduling tech- load1. Block-level code processing is at the heart of nique amount to 88% and 10% of the OoO superior the this architecture; CG-OoO speculates, fetches, performance compared to the In-Order (InO) proces- schedules, and commits code at block-level granu- sor [5]. Scheduling and speculation in OoO is performed larity. It eliminates unnecessary accesses to energy at instruction granularity regardless of the instruction consuming tables, and turns large tables into smaller type even though they are mainly effective during un- and distributed tables that are cheaper to access. predictable dynamic events (e.g. unpredictable cache CG-OoO leverages compiler-level code optimizations misses) [5]. Furthermore, our studies show speculation to deliver efficient static code, and exploits dynamic and dynamic scheduling amount to 67% and 51% of instruction-level parallelism and block-level parallelism. -

Design and Analysis of Integrated CMOS High-Voltage Drivers in Low-Voltage Technologies
Design and Analysis of Integrated CMOS High-Voltage Drivers in Low-Voltage Technologies Von der Fakultat¨ fur¨ MINT – Mathematik, Informatik, Physik, Elektro- und Informationstechnik der Brandenburgischen Technischen Universitat¨ Cottbus-Senftenberg zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften (Dr.-Ing.) genehmigte Dissertation vorgelegt von M.Sc. Dipl.-Ing. Sara Toktam Pashmineh Azar geboren am 20.11.1972 in Torbat Heydarieh Gutachter: Prof. Dr.-Ing. Matthias Rudolph (Vorsitzender der Prufungskommission)¨ Gutachter: Prof. Dr.-Ing. Dirk Killat Gutachter: Prof. Dr.-Ing. Klaus Hofmann (Technische Universitat¨ Darmstadt) Tag der mundlichen¨ Prufung:¨ 10.07.2017 Selbstst¨andigkeitserkl¨arung Die Verfasserin erkl¨art, dass sie die vorliegende Arbeit selbst¨andig, ohne fremde Hilfe und ohne Benutzung anderer als die angegebenen Hilfsmittel angefertigt hat. Die aus frem- den Quellen (einschließlich elektronischer Quellen) direkt oder indirektubernommenen ¨ Gedanken sind ausnahmslos als solche kenntlich gemacht. Die Arbeit ist in gleicher oder ¨ahnlicher Form oder auszugsweise im Rahmen einer anderen Pr¨ufung noch nicht vorgelegt worden. Cottbus, Abstract With scaling technology, the nominal I/O voltage of standard transistors has been re- duced from 5.0 V in 0.25-μm processes to 2.5 V in 65-nm. However, the supply voltages of some applications cannot be reduced at the same rate as that of shrinking technolo- gies. Since high-voltage (HV-) compatible transistors are not available for some recent technologies and need time to be designed after developing a new process technology, de- signing HV-circuits based on stacked transistors has better benefits because such circuits offer technology independence and full integration with digital circuits to provide system- on-chip solutions. -

WP Microelectronics and Interconnections
Advanced European Infrastructures for Detectors at Accelerators FirSecondst Ann Annualual MeMeetingeting: WPWP44 St Statusatus R Reporteport ChrisChristophetophe de LA TA ILdeLE (laCN TailleRS/IN2P(CNRS/IN2P3)3) Valerio RE (INFN ) Valerio Re (INFN/Univ. Bergamo) LPNHE, Paris, April 7, 2017 DESY, Hamburg, June 17, 2016 This project has received funding from the European Union’s Horizon 2020 Research and Innovation programme under Grant Agreement no. 654168. WP4: microelectronics and interconnections • WP Coordinators: Christophe de la Taille, Valerio Re • Goal : provide chips and interconnections to detectors developed by other WPs • Task 1: Scientific coordination (CNRS-OMEGA, INFN-UNIBG) • Task 2 : 65 nm chips for trackers (CERN) • Fine pitch, low power, advanced digital processing • Task 3 : SiGe 130nm for calorimeters/gaseous (IN2P3) • Highly integrated charge and time measurement • Task 4 : interconnections between 65 nm chips and pixel sensors (INFN) • TSVs in 65 nm CMOS wafers, bonding of 65 nm chips to sensors, exploration of fine pitch bonding processes AIDA WP4 milestones MS4.1 Architectural review of deliverable chips in 65nm run M14 (accomplished) MS4.2 Final design review of 65nm M30 (October 2017) MS4.3 Test report of deliverable D4.1 M46 (February 2019) MS4.4 Selection of SiGe foundry M14 (accomplished) MS4.5 Final design review of deliverable chips in SiGe run M30 (October 2017) MS4.6 Test report of deliverable D4.2 M46 MS4.7 Selection of TSV process M14 (accomplished) MS4.8 Final design review of deliverable D4.3 (TSV -

Parallel Computer Architecture III
Parallel Computer Architecture III Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-69120 Heidelberg phone: 06221/54-8264 email: [email protected] WS 14/15 Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 1 / 51 Parallel Computer Architecture III Parallelism and Granularity Graphic cards I/O Detailed study Hypertransport Protocol Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 2 / 51 Parallelism and Granularity level five jobs or Programs coarse grained Subprograms, modules level four or classes middle grained Increase of Increase of Parallelism Communications Procedures, functions level three Requirements or methods Non−recursive loops level two or iterators fine grained Instructions level one or statements Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 3 / 51 Graphics Cards GPU = Graphics Processing Unit CUDA = Compute Unified Device Architecture ◮ Toolkit by NVIDIA for direct GPU Programming ◮ Programming of a GPU without graphical API ◮ GPGPU compared to CPUs strongly increased computing performance and storage bandwidth GPUs are cheap and broadly established Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 4 / 51 Computing Performance: CPU vs. GPU Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 5 / 51 Graphics Cards: Hardware Specification Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 6 / 51 Chip Architecture: CPU vs. GPU Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 7 / 51 Graphics Cards: Hardware Design Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 8 / 51 Graphics Cards: Memory Design 8192 registers (32-bit), in total 32KB per multiprocessor 16KB of fast shared memory per multiprocessor Large global memory (hundreds of MBs, e.g. -

Distributed Microarchitectural Protocols in the TRIPS Prototype Processor
Øh Appears in the ¿9 Annual International Symposium on Microarchitecture Distributed Microarchitectural Protocols in the TRIPS Prototype Processor Karthikeyan Sankaralingam Ramadass Nagarajan Robert McDonald Ý Rajagopalan DesikanÝ Saurabh Drolia M.S. Govindan Paul Gratz Divya Gulati Heather HansonÝ ChangkyuKim HaimingLiu NityaRanganathan Simha Sethumadhavan Sadia SharifÝ Premkishore Shivakumar Stephen W. Keckler Doug Burger Department of Computer Sciences ÝDepartment of Electrical and Computer Engineering The University of Texas at Austin [email protected] www.cs.utexas.edu/users/cart Abstract are clients on one or more micronets. Higher-level mi- croarchitectural protocols direct global control across the Growing on-chip wire delays will cause many future mi- micronets and tiles in a manner invisible to software. croarchitectures to be distributed, in which hardware re- In this paper, we describe the tile partitioning, micronet sources within a single processor become nodes on one or connectivity, and distributed protocols that provide global more switched micronetworks. Since large processor cores services in the TRIPS processor, including distributed fetch, will require multiple clock cycles to traverse, control must execution, flush, and commit. Prior papers have described be distributed, not centralized. This paper describes the this approach to exploiting parallelism as well as high-level control protocols in the TRIPS processor, a distributed, tiled performanceresults [15, 3], but have not described the inter- microarchitecture that supports dynamic execution. It de- tile connectivity or protocols. Tiled architectures such as tails each of the five types of reused tiles that compose the RAW [23] use static orchestration to manage global oper- processor, the control and data networks that connect them, ations, but in a dynamically scheduled, distributed archi- and the distributed microarchitectural protocols that imple- tecture such as TRIPS, hardware protocols are required to ment instruction fetch, execution, flush, and commit. -

An Evaluation of the TRIPS Computer System
Appears in the Proceedings of the 14th International Conference on Architecture Support for Programming Languages and Operating Systems An Evaluation of the TRIPS Computer System Mark Gebhart Bertrand A. Maher Katherine E. Coons Jeff Diamond Paul Gratz Mario Marino Nitya Ranganathan Behnam Robatmili Aaron Smith James Burrill Stephen W. Keckler Doug Burger Kathryn S. McKinley Department of Computer Sciences The University of Texas at Austin [email protected] www.cs.utexas.edu/users/cart Abstract issue-width scaling of conventional superscalar architec- The TRIPS system employs a new instruction set architec- tures. Because of these trends, major microprocessor ven- ture (ISA) called Explicit Data Graph Execution (EDGE) dors have abandoned architectures for single-thread perfor- that renegotiates the boundary between hardware and soft- mance and turned to the promise of multiple cores per chip. ware to expose and exploit concurrency. EDGE ISAs use a While many applications can exploit multicore systems, this block-atomic execution model in which blocks are composed approach places substantial burdens on programmers to par- of dataflow instructions. The goal of the TRIPS design is allelize their codes. Despite these trends, Amdahl’s law dic- to mine concurrency for high performance while tolerating tates that single-thread performance will remain key to the emerging technology scaling challenges, such as increas- future success of computer systems [9]. ing wire delays and power consumption. This paper eval- In response to semiconductor scaling trends, we designed uates how well TRIPS meets this goal through a detailed a new architecture and microarchitecture intended to extend ISA and performance analysis.