Compiling for EDGE Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Performance and Energy Efficient Network-On-Chip Architectures
Linköping Studies in Science and Technology Dissertation No. 1130 Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 ISBN 978-91-85895-91-5 ISSN 0345-7524 ii Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal ISBN 978-91-85895-91-5 Copyright Sriram. R. Vangal, 2007 Linköping Studies in Science and Technology Dissertation No. 1130 ISSN 0345-7524 Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 Author email: [email protected] Cover Image A chip microphotograph of the industry’s first programmable 80-tile teraFLOPS processor, which is implemented in a 65-nm eight-metal CMOS technology. Printed by LiU-Tryck, Linköping University Linköping, Sweden, 2007 Abstract The scaling of MOS transistors into the nanometer regime opens the possibility for creating large Network-on-Chip (NoC) architectures containing hundreds of integrated processing elements with on-chip communication. NoC architectures, with structured on-chip networks are emerging as a scalable and modular solution to global communications within large systems-on-chip. NoCs mitigate the emerging wire-delay problem and addresses the need for substantial interconnect bandwidth by replacing today’s shared buses with packet-switched router networks. With on-chip communication consuming a significant portion of the chip power and area budgets, there is a compelling need for compact, low power routers. While applications dictate the choice of the compute core, the advent of multimedia applications, such as three-dimensional (3D) graphics and signal processing, places stronger demands for self-contained, low-latency floating-point processors with increased throughput. -

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers. -

Configurable Fine-Grain Protection for Multicore Processor Virtualization 1
Configurable Fine-Grain Protection for Multicore Processor Virtualization David Wentzlaff1, Christopher J. Jackson2, Patrick Griffin3, and Anant Agarwal2 [email protected], [email protected], griffi[email protected], [email protected] 1Princeton University 2Tilera Corp. 3Google Inc. Abstract TLB Access DMA Engine “User” Network I/O Network 2 2 2 2 1 3 1 3 1 3 1 3 Multicore architectures, with their abundant on-chip re- 0 0 0 0 sources, are effectively collections of systems-on-a-chip. The protection system for these architectures must support Key: 0 – User Code, 1 – OS, 2 – Hypervisor, 3 – Hypervisor Debugger multiple concurrently executing operating systems (OSes) Figure 1. With CFP, system software can dy• with different needs, and manage and protect the hard- namically set the privilege level needed to ac• ware’s novel communication mechanisms and hardware cess each fine•grain processor resource. features. Traditional protection systems are insufficient; they protect supervisor from user code, but typically do not protect one system from another, and only support fixed as- ticore systems, a protection system must both temporally signment of resources to protection levels. In this paper, protect and spatially isolate access to resources. Spatial iso- we propose an alternative to traditional protection systems lation is the need to isolate different system software stacks which we call configurable fine-grain protection (CFP). concurrently executing on spatially disparate cores in a mul- CFP enables the dynamic assignment of in-core resources ticore system. Spatial isolation is especially important now to protection levels. We investigate how CFP enables differ- that multicore systems have directly accessible networks ent system software stacks to utilize the same configurable connecting cores to other cores and cores to I/O devices. -
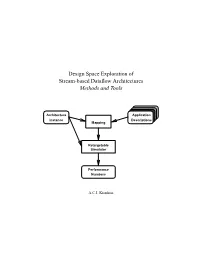
Design Space Exploration of Stream-Based Dataflow Architectures
Design Space Exploration of Stream-based Dataflow Architectures Methods and Tools Architecture Application Instance Descriptions Mapping Retargetable Simulator Performance Numbers A.C.J. Kienhuis Design Space Exploration of Stream-based Dataflow Architectures PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof.ir. K.F. Wakker, in het openbaar te verdedigen ten overstaan van een commissie, door het College voor Promoties aangewezen, op vrijdag 29 Januari 1999 te 10:30 uur door Albert Carl Jan KIENHUIS elektrotechnisch ingenieur geboren te Vleuten. Dit proefschrift is goedgekeurd door de promotor: Prof.dr.ir. P.M. Dewilde Toegevoegd promotor: Dr.ir. E.F. Deprettere. Samenstelling promotiecommissie: Rector Magnificus, voorzitter Prof.dr.ir. P.M. Dewilde, Technische Universiteit Delft, promotor Dr.ir. E.F. Deprettere, Technische Universiteit Delft, toegevoegd promotor Ir. K.A. Vissers, Philips Research Eindhoven Prof.dr.ir. J.L. van Meerbergen, Technische Universiteit Eindhoven Prof.Dr.-Ing. R. Ernst, Technische Universit¨at Braunschweig Prof.dr. S. Vassiliadis, Technische Universiteit Delft Prof.dr.ir. R.H.J.M. Otten, Technische Universiteit Delft Ir. K.A. Vissers en Dr.ir. P. van der Wolf van Philips Research Eindhoven, hebben als begeleiders in belangrijke mate aan de totstandkoming van het proefschrift bijgedragen. CIP-DATA KONINKLIJKE BIBLIOTHEEK, DEN HAAG Kienhuis, Albert Carl Jan Design Space Exploration of Stream-based Dataflow Architectures : Methods and Tools Albert Carl Jan Kienhuis. - Delft: Delft University of Technology Thesis Technische Universiteit Delft. - With index, ref. - With summary in Dutch ISBN 90-5326-029-3 Subject headings: IC-design; Data flow Computing; Systems Analysis Copyright c 1999 by A.C.J. -

CG-Ooo Energy-Efficient Coarse-Grain Out-Of-Order Execution
CG-OoO Energy-Efficient Coarse-Grain Out-of-Order Execution Milad Mohammadi⋆, Tor M. Aamodt†, William J. Dally⋆‡ ⋆Stanford University, †University of British Columbia, ‡NVIDIA Research [email protected], [email protected], [email protected] ABSTRACT CG-OoO model to make it even more energy efficient. We introduce the Coarse-Grain Out-of-Order (CG- Despite the significant achievements in improving en- OoO) general purpose processor designed to achieve ergy and performance properties of the OoO proces- close to In-Order processor energy while maintaining sor in the recent years [2], studies show the energy Out-of-Order (OoO) performance. CG-OoO is an and performance attributes of the OoO execution model energy-performance proportional general purpose remain superlinearly proportional [3, 4]. Studies indi- architecture that scales according to the program cate control speculation and dynamic scheduling tech- load1. Block-level code processing is at the heart of nique amount to 88% and 10% of the OoO superior the this architecture; CG-OoO speculates, fetches, performance compared to the In-Order (InO) proces- schedules, and commits code at block-level granu- sor [5]. Scheduling and speculation in OoO is performed larity. It eliminates unnecessary accesses to energy at instruction granularity regardless of the instruction consuming tables, and turns large tables into smaller type even though they are mainly effective during un- and distributed tables that are cheaper to access. predictable dynamic events (e.g. unpredictable cache CG-OoO leverages compiler-level code optimizations misses) [5]. Furthermore, our studies show speculation to deliver efficient static code, and exploits dynamic and dynamic scheduling amount to 67% and 51% of instruction-level parallelism and block-level parallelism. -

Object-Oriented Development for Reconfigurable Architectures
Object-Oriented Development for Reconfigurable Architectures Von der Fakultät für Mathematik und Informatik der Technischen Universität Bergakademie Freiberg genehmigte DISSERTATION zur Erlangung des akademischen Grades Doktor Ingenieur Dr.-Ing., vorgelegt von Dipl.-Inf. (FH) Dominik Fröhlich geboren am 19. Februar 1974 Gutachter: Prof. Dr.-Ing. habil. Bernd Steinbach (Freiberg) Prof. Dr.-Ing. Thomas Beierlein (Mittweida) PD Dr.-Ing. habil. Michael Ryba (Osnabrück) Tag der Verleihung: 20. Juni 2007 To my parents. ABSTRACT Reconfigurable hardware architectures have been available now for several years. Yet the application devel- opment for such architectures is still a challenging and error-prone task, since the methods, languages, and tools being used for development are inappropriate to handle the complexity of the problem. This hampers the widespread utilization, despite of the numerous advantages offered by this type of architecture in terms of computational power, flexibility, and cost. This thesis introduces a novel approach that tackles the complexity challenge by raising the level of ab- straction to system-level and increasing the degree of automation. The approach is centered around the paradigms of object-orientation, platforms, and modeling. An application and all platforms being used for its design, implementation, and deployment are modeled with objects using UML and an action language. The application model is then transformed into an implementation, whereby the transformation is steered by the platform models. In this thesis solutions for the relevant problems behind this approach are discussed. It is shown how UML can be used for complete and precise modeling of applications and platforms. Application development is done at the system-level using a set of well-defined, orthogonal platform models. -

Parallel Computer Architecture III
Parallel Computer Architecture III Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-69120 Heidelberg phone: 06221/54-8264 email: [email protected] WS 14/15 Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 1 / 51 Parallel Computer Architecture III Parallelism and Granularity Graphic cards I/O Detailed study Hypertransport Protocol Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 2 / 51 Parallelism and Granularity level five jobs or Programs coarse grained Subprograms, modules level four or classes middle grained Increase of Increase of Parallelism Communications Procedures, functions level three Requirements or methods Non−recursive loops level two or iterators fine grained Instructions level one or statements Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 3 / 51 Graphics Cards GPU = Graphics Processing Unit CUDA = Compute Unified Device Architecture ◮ Toolkit by NVIDIA for direct GPU Programming ◮ Programming of a GPU without graphical API ◮ GPGPU compared to CPUs strongly increased computing performance and storage bandwidth GPUs are cheap and broadly established Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 4 / 51 Computing Performance: CPU vs. GPU Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 5 / 51 Graphics Cards: Hardware Specification Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 6 / 51 Chip Architecture: CPU vs. GPU Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 7 / 51 Graphics Cards: Hardware Design Stefan Lang (IWR) Simulation on High-Performance Computers WS 14/15 8 / 51 Graphics Cards: Memory Design 8192 registers (32-bit), in total 32KB per multiprocessor 16KB of fast shared memory per multiprocessor Large global memory (hundreds of MBs, e.g. -

Distributed Microarchitectural Protocols in the TRIPS Prototype Processor
Øh Appears in the ¿9 Annual International Symposium on Microarchitecture Distributed Microarchitectural Protocols in the TRIPS Prototype Processor Karthikeyan Sankaralingam Ramadass Nagarajan Robert McDonald Ý Rajagopalan DesikanÝ Saurabh Drolia M.S. Govindan Paul Gratz Divya Gulati Heather HansonÝ ChangkyuKim HaimingLiu NityaRanganathan Simha Sethumadhavan Sadia SharifÝ Premkishore Shivakumar Stephen W. Keckler Doug Burger Department of Computer Sciences ÝDepartment of Electrical and Computer Engineering The University of Texas at Austin [email protected] www.cs.utexas.edu/users/cart Abstract are clients on one or more micronets. Higher-level mi- croarchitectural protocols direct global control across the Growing on-chip wire delays will cause many future mi- micronets and tiles in a manner invisible to software. croarchitectures to be distributed, in which hardware re- In this paper, we describe the tile partitioning, micronet sources within a single processor become nodes on one or connectivity, and distributed protocols that provide global more switched micronetworks. Since large processor cores services in the TRIPS processor, including distributed fetch, will require multiple clock cycles to traverse, control must execution, flush, and commit. Prior papers have described be distributed, not centralized. This paper describes the this approach to exploiting parallelism as well as high-level control protocols in the TRIPS processor, a distributed, tiled performanceresults [15, 3], but have not described the inter- microarchitecture that supports dynamic execution. It de- tile connectivity or protocols. Tiled architectures such as tails each of the five types of reused tiles that compose the RAW [23] use static orchestration to manage global oper- processor, the control and data networks that connect them, ations, but in a dynamically scheduled, distributed archi- and the distributed microarchitectural protocols that imple- tecture such as TRIPS, hardware protocols are required to ment instruction fetch, execution, flush, and commit. -

An Evaluation of the TRIPS Computer System
Appears in the Proceedings of the 14th International Conference on Architecture Support for Programming Languages and Operating Systems An Evaluation of the TRIPS Computer System Mark Gebhart Bertrand A. Maher Katherine E. Coons Jeff Diamond Paul Gratz Mario Marino Nitya Ranganathan Behnam Robatmili Aaron Smith James Burrill Stephen W. Keckler Doug Burger Kathryn S. McKinley Department of Computer Sciences The University of Texas at Austin [email protected] www.cs.utexas.edu/users/cart Abstract issue-width scaling of conventional superscalar architec- The TRIPS system employs a new instruction set architec- tures. Because of these trends, major microprocessor ven- ture (ISA) called Explicit Data Graph Execution (EDGE) dors have abandoned architectures for single-thread perfor- that renegotiates the boundary between hardware and soft- mance and turned to the promise of multiple cores per chip. ware to expose and exploit concurrency. EDGE ISAs use a While many applications can exploit multicore systems, this block-atomic execution model in which blocks are composed approach places substantial burdens on programmers to par- of dataflow instructions. The goal of the TRIPS design is allelize their codes. Despite these trends, Amdahl’s law dic- to mine concurrency for high performance while tolerating tates that single-thread performance will remain key to the emerging technology scaling challenges, such as increas- future success of computer systems [9]. ing wire delays and power consumption. This paper eval- In response to semiconductor scaling trends, we designed uates how well TRIPS meets this goal through a detailed a new architecture and microarchitecture intended to extend ISA and performance analysis. -

A Survey on Coarse-Grained Reconfigurable Architectures from a Performance Perspective
Received May 31, 2020, accepted July 13, 2020, date of publication July 27, 2020, date of current version August 20, 2020. Digital Object Identifier 10.1109/ACCESS.2020.3012084 A Survey on Coarse-Grained Reconfigurable Architectures From a Performance Perspective ARTUR PODOBAS 1,2, KENTARO SANO1, AND SATOSHI MATSUOKA1,3 1RIKEN Center for Computational Science, Kobe 650-0047, Japan 2Department of Computer Science, KTH Royal Institute of Technology, 114 28 Stockholm, Sweden 3Department of Mathematical and Computing Sciences, Tokyo Institute of Technology, Tokyo 152-8550, Japan Corresponding author: Artur Podobas ([email protected]) This work was supported by the New Energy and Industrial Technology Development Organization (NEDO). ABSTRACT With the end of both Dennard’s scaling and Moore’s law, computer users and researchers are aggressively exploring alternative forms of computing in order to continue the performance scaling that we have come to enjoy. Among the more salient and practical of the post-Moore alternatives are reconfigurable systems, with Coarse-Grained Reconfigurable Architectures (CGRAs) seemingly capable of striking a balance between performance and programmability. In this paper, we survey the landscape of CGRAs. We summarize nearly three decades of literature on the subject, with a particular focus on the premise behind the different CGRAs and how they have evolved. Next, we compile metrics of available CGRAs and analyze their performance properties in order to understand and discover knowledge gaps and opportunities for future CGRA research specialized towards High-Performance Computing (HPC). We find that there are ample opportunities for future research on CGRAs, in particular with respect to size, functionality, support for parallel programming models, and to evaluate more complex applications.