Cognitive Dimensions Usability Assessment of Textual and Visual VHDL Environments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers. -
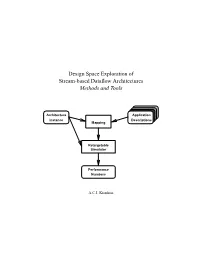
Design Space Exploration of Stream-Based Dataflow Architectures
Design Space Exploration of Stream-based Dataflow Architectures Methods and Tools Architecture Application Instance Descriptions Mapping Retargetable Simulator Performance Numbers A.C.J. Kienhuis Design Space Exploration of Stream-based Dataflow Architectures PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof.ir. K.F. Wakker, in het openbaar te verdedigen ten overstaan van een commissie, door het College voor Promoties aangewezen, op vrijdag 29 Januari 1999 te 10:30 uur door Albert Carl Jan KIENHUIS elektrotechnisch ingenieur geboren te Vleuten. Dit proefschrift is goedgekeurd door de promotor: Prof.dr.ir. P.M. Dewilde Toegevoegd promotor: Dr.ir. E.F. Deprettere. Samenstelling promotiecommissie: Rector Magnificus, voorzitter Prof.dr.ir. P.M. Dewilde, Technische Universiteit Delft, promotor Dr.ir. E.F. Deprettere, Technische Universiteit Delft, toegevoegd promotor Ir. K.A. Vissers, Philips Research Eindhoven Prof.dr.ir. J.L. van Meerbergen, Technische Universiteit Eindhoven Prof.Dr.-Ing. R. Ernst, Technische Universit¨at Braunschweig Prof.dr. S. Vassiliadis, Technische Universiteit Delft Prof.dr.ir. R.H.J.M. Otten, Technische Universiteit Delft Ir. K.A. Vissers en Dr.ir. P. van der Wolf van Philips Research Eindhoven, hebben als begeleiders in belangrijke mate aan de totstandkoming van het proefschrift bijgedragen. CIP-DATA KONINKLIJKE BIBLIOTHEEK, DEN HAAG Kienhuis, Albert Carl Jan Design Space Exploration of Stream-based Dataflow Architectures : Methods and Tools Albert Carl Jan Kienhuis. - Delft: Delft University of Technology Thesis Technische Universiteit Delft. - With index, ref. - With summary in Dutch ISBN 90-5326-029-3 Subject headings: IC-design; Data flow Computing; Systems Analysis Copyright c 1999 by A.C.J. -

Object-Oriented Development for Reconfigurable Architectures
Object-Oriented Development for Reconfigurable Architectures Von der Fakultät für Mathematik und Informatik der Technischen Universität Bergakademie Freiberg genehmigte DISSERTATION zur Erlangung des akademischen Grades Doktor Ingenieur Dr.-Ing., vorgelegt von Dipl.-Inf. (FH) Dominik Fröhlich geboren am 19. Februar 1974 Gutachter: Prof. Dr.-Ing. habil. Bernd Steinbach (Freiberg) Prof. Dr.-Ing. Thomas Beierlein (Mittweida) PD Dr.-Ing. habil. Michael Ryba (Osnabrück) Tag der Verleihung: 20. Juni 2007 To my parents. ABSTRACT Reconfigurable hardware architectures have been available now for several years. Yet the application devel- opment for such architectures is still a challenging and error-prone task, since the methods, languages, and tools being used for development are inappropriate to handle the complexity of the problem. This hampers the widespread utilization, despite of the numerous advantages offered by this type of architecture in terms of computational power, flexibility, and cost. This thesis introduces a novel approach that tackles the complexity challenge by raising the level of ab- straction to system-level and increasing the degree of automation. The approach is centered around the paradigms of object-orientation, platforms, and modeling. An application and all platforms being used for its design, implementation, and deployment are modeled with objects using UML and an action language. The application model is then transformed into an implementation, whereby the transformation is steered by the platform models. In this thesis solutions for the relevant problems behind this approach are discussed. It is shown how UML can be used for complete and precise modeling of applications and platforms. Application development is done at the system-level using a set of well-defined, orthogonal platform models. -

Dataflow Computing Models, Languages, and Machines for Intelligence Computations
IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 14, NO. 12, DECEMBER 1988 1805 Dataflow Computing Models, Languages, and Machines for Intelligence Computations JAYANTHA HERATH, MEMBER, IEEE, YOSHINOR1 YAMAGUCHI, NOBUO SAITO, MEMBER, IEEE, AND TOSHITSUGU YUBA Abstract-Dataflow computing, a radical departure from von Neu- parallel and nondeterministic computations. The alterna- mann computing, supports multiprocessing on a massive scale and plays tive to sequential processing is parallel processing with a major role in permitting intelligence computing machines to achieve ultrahigh speeds. Intelligence computations consist of large complex high density devices. To solve nondeterministic prob- numerical and nonnumerical computations. Efficient computing models lems, it is necessary to research efficient computing are necessary to represent intelligence computations. An abstract com- models and more efficient heuristics. The machines pro- puting model, a base language specification for the abstract model, cessing intelligence computations must be dynamic. Ef- high-level and low-level language design to map parallel algorithms to ficient control mechanisms for load balancing of re- abstract computing model, parallel architecture design to support computing model and design of support software to map computing sources, communicating networks, garbage collectors, model to arcTiitecture are steps in constructing computing systems. This and schedulers are important in such machines. Computer paper concentrates on dataflow computing for intelligence computa- hardware improved from vacuum tubes to VLSI but there tions and presents a comparison of dataflow computing models, lan- has been no significant change in the sequential abstract guages and dataflow computing machines for numerical and nonnu- computing model, sequential algorithms, languages and merical computations. The high level language-graph transformation that must be performed to achieve high performance for numerical and architecture. -

Hyperflow: a Heterogeneous Dataflow Architecture
Eurographics Symposium on Parallel Graphics and Visualization (2012) H. Childs, T. Kuhlen, and F. Marton (Editors) HyperFlow: A Heterogeneous Dataflow Architecture Huy T. Vo1, Daniel K. Osmari1, João Comba2, Peter Lindstrom3 and Cláudio T. Silva1 1Polytechnic Institute of New York University 2Instituto de Informática, UFRGS, Brazil 3Lawrence Livermore National Laboratories Abstract We propose a dataflow architecture, called HyperFlow, that offers a supporting infrastructure that creates an abstraction layer over computation resources and naturally exposes heterogeneous computation to dataflow pro- cessing. In order to show the efficiency of our system as well as testing it, we have included a set of synthetic and real-case applications. First, we designed a general suite of micro-benchmarks that captures main parallel pipeline structures and allows evaluation of HyperFlow under different stress conditions. Finally, we demonstrate the potential of our system with relevant applications in visualization. Implementations in HyperFlow are shown to have greater performance than actual hand-tuning codes, yet still providing high scalability on different platforms. Categories and Subject Descriptors (according to ACM CCS): I.3.3 [Computer Graphics]: Picture/Image Generation—Line and curve generation 1. Introduction possibly many interconnected nodes. Each node is an indi- vidual machine that contains a set of heterogeneous process- The popularization of commodity multi-core CPUs and ing elements. The architecture is designed to make full use of multi-GPU units has opened many alternatives for the design data streaming, a concept used before in scientific dataflow and implementation of efficient visualization and data analy- systems. HyperFlow provides an infrastructure of abstract sis algorithms. However, manually distributing the process- layers that allow dataflow systems to be designed without ing load among CPU cores and GPU units can be very cum- knowledge of the actual processing elements used to exe- bersome. -

Comparative Analysis of Dataflow Engines and Conventional Cpus in Data-Intensive Applications
IJCSN - International Journal of Computer Science and Network, Volume 7, Issue 4, August 2018 ISSN (Online) : 2277-5420 www.IJCSN.org Impact Factor: 1.5 Comparative Analysis of Dataflow Engines and Conventional CPUs in Data-intensive Applications 1Abdulkadir Dauda; 2Haruna Umar Adoga; 3John Francis Ogbonoko 1Department of Computer Science, Federal University Lafia, Nasarawa, Nigeria 2Department of Computer Science, Federal University Lafia, Nasarawa, Nigeria 3Department of Computer Science, Federal University Lafia, Nasarawa, Nigeria Abstract - High-performance systems are a vital tool for supporting the rapid developments being recorded in software technologies. The recent innovations in software systems have changed the way we see and deal with our physical world. Many applications today, as part of their functions, implement highly data-intensive algorithms such as machine learning, graphics processing, and scientific calculations which require high processing power to deliver acceptable performance. The Central Processing Unit (CPU)-based architectures, which have been used over the years, are not coping well with these classes of applications. This has led to the emergence of a new set of architectures such as Graphics Processing Units (GPUs) and Field Programmable Gate Arrays (FPGAs). These architectures are based on the computing paradigm referred to as dataflow computing in contrast to the popular control-flow computing. In this research, we used the dataflow engines developed by Maxeler Technologies, to compare performance with conventional CPU- based parallel systems by writing a program each for the two platforms, which solves a typical vector operation, and run it on the two platforms. The results of the experiment show that even though the Dataflow Engines (DFEs) we used in our experiments run at the clock frequency of 100MHz, its performance is at par with a quad core CPU which runs at 1.86GHz per core. -

Neuflow: a Runtime Reconfigurable Dataflow Processor for Vision
Invited Paper NeuFlow: A Runtime Reconfigurable Dataflow Processor for Vision Clement´ Farabet1;2 Berin Martini2 Benoit Corda1 Polina Akselrod2 Eugenio Culurciello2 Yann LeCun1 1 Courant Institute of Mathematical Sciences, New York University, New York, NY, USA 2 Electrical Engineering Department, Yale University, New Haven, CT, USA http://www.neuflow.org Abstract tions), a non-linear operation (quantization, winner-take-all, sparsification, normalization, and/or point-wise saturation) In this paper we present a scalable dataflow hard- and finally a pooling operation (max, average or histogram- ware architecture optimized for the computation of general- ming). For example, the scale-invariant feature transform purpose vision algorithms—neuFlow—and a dataflow (SIFT [23]) operator applies oriented edge filters to a small compiler—luaFlow—that transforms high-level flow-graph patch and determines the dominant orientation through a representations of these algorithms into machine code for winner-take-all operation. Finally, the resulting sparse vec- neuFlow. This system was designed with the goal of pro- tors are added (pooled) over a larger patch to form local ori- viding real-time detection, categorization and localization entation histograms. Some recognition systems use a single of objects in complex scenes, while consuming 10 Watts stage of feature extractors [19,7, 25]. Other models like when implemented on a Xilinx Virtex 6 FPGA platform, or HMAX-type models [27, 24] and convolutional networks about ten times less than a laptop computer, and producing use two or more layers of successive feature extractors. speedups of up to 100 times in real-world applications. We This paper presents a scalable hardware architecture for present an application of the system on street scene anal- large-scale multi-layered synthetic vision systems based on ysis, segmenting 20 categories on 500 × 375 frames at 12 large parallel filter banks, such as convolutional networks— frames per second on our custom hardware neuFlow. -

High Level Synthesis with a Dataflow Architectural Template
High Level Synthesis with a Dataflow Architectural Template Shaoyi Cheng and John Wawrzynek Department of EECS, UC Berkeley, California, USA 94720 Email: sh [email protected], [email protected] Abstract—In this work, we present a new approach to high of the FPGAs as throughput-oriented devices, it structures level synthesis (HLS), where high level functions are first the computation and data accesses into a series of coarse- mapped to an architectural template, before hardware synthe- grained pipeline stages, through which data flows. To target sis is performed. As FPGA platforms are especially suitable for implementing streaming processing pipelines, we perform this architectural template, we have developed a tool to slice transformations on conventional high level programs where they the original CDFG of the performance critical loop nests are turned into multi-stage dataflow engines [1]. This target into subgraphs, connected by communication channels (sec- template naturally overlaps slow memory data accesses with tion III). This decouples the scheduling of operations between computations and therefore has much better tolerance towards different subgraphs and subsequently improves the overall memory subsystem latency. Using a state-of-the-art HLS tool for the actual circuit generation, we observe up to 9x improvement throughput in the presence of data fetch stalls. Then, each in overall performance when the dataflow architectural template of the subgraphs is fed to a conventional high-level synthesis is used as an intermediate compilation target. flow, generating independent datapaths and controllers. FIFO Index Terms—FPGA, Overlay Architecture, Hardware design channels are instantiated to connect the datapaths, forming the template, High-level Synthesis, Pipeline Parallelism final system (section IV). -

Compiling for EDGE Architectures
Appears in the Proceedings of the 4th International Symposium on Code Generation and Optimization (CGO 04). Compiling for EDGE Architectures AaronSmith JimBurrill1 Jon Gibson Bertrand Maher Nick Nethercote BillYoder DougBurger KathrynS.McKinley Department of Computer Sciences 1Department of Computer Science The University of Texas at Austin University of Massachusetts Austin, Texas 78712 Amherst, Massachusetts 01003 Abstract sibilities between programmer, compiler, and hardware to discover and exploit concurrency. Explicit Data Graph Execution (EDGE) architectures of- In previous solutions, CISC processors intentionally fer the possibility of high instruction-level parallelism with placed few ISA-imposed requirements on the compiler to energy efficiency. In EDGE architectures, the compiler expose concurrency. In-order RISC processors required the breaks a program into a sequence of structured blocks that compiler to schedule instructions to minimize pipeline bub- the hardware executes atomically. The instructions within bles for effective pipelining concurrency. With the advent each block communicate directly, instead of communicating of large-window out-of-order microarchitectures, however, through shared registers. The TRIPS EDGE architecture both RISC and CISC processors rely mostly on the hard- imposes restrictions on its blocks to simplify the microar- ware to support superscalar issue. These processors use a chitecture: each TRIPS block has at most 128 instructions, dynamic placement, dynamic issue execution model that re- issues at most 32 loads and/or stores, and executes at most quires the hardware to construct the program dataflow graph 32 register bank reads and 32 writes. To detect block com- on the fly, with little compiler assistance. VLIW processors, pletion, each TRIPS block must produce a constant number conversely, place most of the burden of identifying con- of outputs (stores and register writes) and a branch deci- current instructions on the compiler, which must fill long sion. -

Reconfigurable Dataflow Graphs for Processing-In-Memory
Reconfigurable Dataflow Graphs For Processing-In-Memory Charles F. Shelor Krishna M. Kavi Computer Science and Engineering Computer Science and Engineering University of North Texas University of North Texas Denton, Texas, USA Denton, Texas, USA [email protected] [email protected] ABSTRACT 1 Introduction In order to meet the ever-increasing speed differences between One of the major problems facing today’s computer systems is the processor clocks and memory access times, there has been an disparate speeds between processor instruction cycles and memory interest in moving computation closer to memory. The near data access times. This is not a new issue as this timing mismatch was processing or processing-in-memory is particularly suited for very recognized and known as the memory wall [42]. Advances in high bandwidth memories such as the 3D-DRAMs. There are processor clock rates and architectures have outpaced different ideas proposed for PIMs, including simple in-order improvements in memory bandwidth and access delay. Processors processors, GPUs, specialized ASICs and reconfigurable designs. are running at 2 to 4 GHz range, while DRAM latency is 41.25 ns In our case, we use Coarse-Grained Reconfigurable Logic to build for the fastest DDR4 device from Micron [31]. The cache dataflow graphs for computational kernels as the PIM. We show hierarchy in computer systems has been used to reduce the effects that our approach can achieve significant speedups and save of the memory wall by providing fast access to data items on energy consumed by computations. We evaluated our designs subsequent accesses. The use of multilevel memory caches, using several processing technologies for building the coarse- prefetching of data, multiple memory channels, and wide data gained logic units.