High Level Synthesis with a Dataflow Architectural Template
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Introduction to High-Level Synthesis
High-Level Synthesis An Introduction to High-Level Synthesis Philippe Coussy Michael Meredith Universite´ de Bretagne-Sud, Lab-STICC Forte Design Systems Daniel D. Gajski Andres Takach University of California, Irvine Mentor Graphics today would even think of program- Editor’s note: ming a complex software application High-level synthesis raises the design abstraction level and allows rapid gener- solely by using an assembly language. ation of optimized RTL hardware for performance, area, and power require- In the hardware domain, specification ments. This article gives an overview of state-of-the-art HLS techniques and languages and design methodologies tools. 1,2 ÀÀTim Cheng, Editor in Chief have evolved similarly. For this reason, until the late 1960s, ICs were designed, optimized, and laid out by hand. Simula- THE GROWING CAPABILITIES of silicon technology tion at the gate level appeared in the early 1970s, and and the increasing complexity of applications in re- cycle-based simulation became available by 1979. Tech- cent decades have forced design methodologies niques introduced during the 1980s included place-and- and tools to move to higher abstraction levels. Raising route, schematic circuit capture, formal verification, the abstraction levels and accelerating automation of and static timing analysis. Hardware description lan- both the synthesis and the verification processes have guages (HDLs), such as Verilog (1986) and VHDL for this reason always been key factors in the evolu- (1987), have enabled wide adoption of simulation tion of the design process, which in turn has allowed tools. These HDLs have also served as inputs to logic designers to explore the design space efficiently and synthesis tools leading to the definition of their synthe- rapidly. -

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers. -

Xcell Journal Issue 50, Fall 2004
ISSUE 50, FALL 2004ISSUE 50, FALL XCELL JOURNAL XILINX, INC. Issue 50 Fall 2004 XcellXcelljournaljournal THETHE AUTHORITATIVEAUTHORITATIVE JOURNALJOURNAL FORFOR PROGRAMMABLEPROGRAMMABLE LOGICLOGIC USERSUSERS MEMORYMEMORY DESIGNDESIGN Streaming Data at 10 Gbps Control Your QDR Designs PARTNERSHIP 20 Years of Partnership Author! Author! Programmable WorldWorld 20042004 SOFTWARE Algorithmic C Synthesis The Need for Speed MANUFACTURING Lower PCB Mfg. Costs Optimize PCB Routability R COVER STORY FPGAs on Mars The New SPARTAN™-3 Make It You r ASIC The world’s lowest-cost FPGAs Spartan-3 Platform FPGAs deliver everything you need at the price you want. Leading the way in 90nm process technology, the new Spartan-3 devices are driving down costs in a huge range of high-capability, cost-sensitive applications. With the industry’s widest density range in its class — 50K to 5 Million gates — the Spartan-3 family gives you unbeatable value and flexibility. Lots of features … without compromising on price Check it out. You get 18x18 embedded multipliers for XtremeDSP™ processing in a low-cost FPGA. Our unique staggered pad technology delivers a ton of I/Os for total connectivity solutions. Plus our XCITE technology improves signal integrity, while eliminating hundreds of resistors to simplify board layout and reduce your bill of materials. With the lowest cost per I/O and lowest cost per logic cell, Spartan-3 Platform FPGAs are the perfect fit for any design … and any budget. MAKE IT YOUR ASIC The Programmable Logic CompanySM For more information visit www.xilinx.com/spartan3 Pb-free devices available now ©2004 Xilinx, Inc., 2100 Logic Drive, San Jose, CA 95124. -
Design Space Exploration of Stream-Based Dataflow Architectures
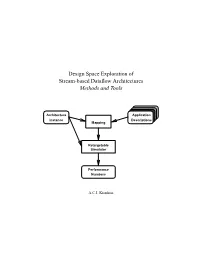
Design Space Exploration of Stream-based Dataflow Architectures Methods and Tools Architecture Application Instance Descriptions Mapping Retargetable Simulator Performance Numbers A.C.J. Kienhuis Design Space Exploration of Stream-based Dataflow Architectures PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof.ir. K.F. Wakker, in het openbaar te verdedigen ten overstaan van een commissie, door het College voor Promoties aangewezen, op vrijdag 29 Januari 1999 te 10:30 uur door Albert Carl Jan KIENHUIS elektrotechnisch ingenieur geboren te Vleuten. Dit proefschrift is goedgekeurd door de promotor: Prof.dr.ir. P.M. Dewilde Toegevoegd promotor: Dr.ir. E.F. Deprettere. Samenstelling promotiecommissie: Rector Magnificus, voorzitter Prof.dr.ir. P.M. Dewilde, Technische Universiteit Delft, promotor Dr.ir. E.F. Deprettere, Technische Universiteit Delft, toegevoegd promotor Ir. K.A. Vissers, Philips Research Eindhoven Prof.dr.ir. J.L. van Meerbergen, Technische Universiteit Eindhoven Prof.Dr.-Ing. R. Ernst, Technische Universit¨at Braunschweig Prof.dr. S. Vassiliadis, Technische Universiteit Delft Prof.dr.ir. R.H.J.M. Otten, Technische Universiteit Delft Ir. K.A. Vissers en Dr.ir. P. van der Wolf van Philips Research Eindhoven, hebben als begeleiders in belangrijke mate aan de totstandkoming van het proefschrift bijgedragen. CIP-DATA KONINKLIJKE BIBLIOTHEEK, DEN HAAG Kienhuis, Albert Carl Jan Design Space Exploration of Stream-based Dataflow Architectures : Methods and Tools Albert Carl Jan Kienhuis. - Delft: Delft University of Technology Thesis Technische Universiteit Delft. - With index, ref. - With summary in Dutch ISBN 90-5326-029-3 Subject headings: IC-design; Data flow Computing; Systems Analysis Copyright c 1999 by A.C.J. -

Catapult DS 1-10 2PG Datasheet US.Qxd
C-B ase d D e s i g n Catapult C Synthesis D ATASHEET Major product features: • Mixed datapath and control logic synthesis from both pure ANSI C++ and SystemC • Multi-abstraction synthesis supports untimed, transaction-level, and cycle-accurate modeling styles • Full-chip synthesis capabilities including pipelined multi-block subsystems and SoC interconnects • Power, performance, and area exploration and optimization • Push button generation of RTL verification infrastructure • Advanced top-down and bottom-up hierarchical design management Catapult C Synthesis produces high-quality RTL implementations from abstract • Full and accurate control over design specifications written in C++ or SystemC, dramatically reducing design and interfaces with Interface Synthesis verification efforts. technology and Modular IO • Interactive and incremental design Tackle Complexity, Accelerate Time to RTL, Reduce Verification Effort methodology achieves fastest path to optimal hardware Traditional hardware design methods that require manual RTL development and debugging are too time consuming and error prone for today’s complex designs. • Fine-grain control for superior The Catapult® C Synthesis tool empowers designers to use industry standard ANSI quality of results C++ and SystemC to describe functional intent, and move up to a more productive • Built-in analysis tools including abstraction level. From these high-level descriptions Catapult generates production Gantt charts, critical path viewer, and quality RTL. With this approach, full hierarchical systems comprised of both cross-probing control blocks and algorithmic units are implemented automatically, eliminating the typical coding errors and bugs introduced by manual flows. By speeding time • Silicon vendor certified synthesis to RTL and automating the generation of bug free RTL, the Catapult C Synthesis libraries and integration with RTL tool significantly reduces the time to verified RTL. -

Object-Oriented Development for Reconfigurable Architectures
Object-Oriented Development for Reconfigurable Architectures Von der Fakultät für Mathematik und Informatik der Technischen Universität Bergakademie Freiberg genehmigte DISSERTATION zur Erlangung des akademischen Grades Doktor Ingenieur Dr.-Ing., vorgelegt von Dipl.-Inf. (FH) Dominik Fröhlich geboren am 19. Februar 1974 Gutachter: Prof. Dr.-Ing. habil. Bernd Steinbach (Freiberg) Prof. Dr.-Ing. Thomas Beierlein (Mittweida) PD Dr.-Ing. habil. Michael Ryba (Osnabrück) Tag der Verleihung: 20. Juni 2007 To my parents. ABSTRACT Reconfigurable hardware architectures have been available now for several years. Yet the application devel- opment for such architectures is still a challenging and error-prone task, since the methods, languages, and tools being used for development are inappropriate to handle the complexity of the problem. This hampers the widespread utilization, despite of the numerous advantages offered by this type of architecture in terms of computational power, flexibility, and cost. This thesis introduces a novel approach that tackles the complexity challenge by raising the level of ab- straction to system-level and increasing the degree of automation. The approach is centered around the paradigms of object-orientation, platforms, and modeling. An application and all platforms being used for its design, implementation, and deployment are modeled with objects using UML and an action language. The application model is then transformed into an implementation, whereby the transformation is steered by the platform models. In this thesis solutions for the relevant problems behind this approach are discussed. It is shown how UML can be used for complete and precise modeling of applications and platforms. Application development is done at the system-level using a set of well-defined, orthogonal platform models. -

An Introduction to High-Level Synthesis
[3B2-8] mdt2009040008.3d 17/7/09 13:24 Page 8 High-Level Synthesis An Introduction to High-Level Synthesis Philippe Coussy Michael Meredith Universite´ de Bretagne-Sud, Lab-STICC Forte Design Systems Daniel D. Gajski Andres Takach University of California, Irvine Mentor Graphics today would even think of program- Editor’s note: ming a complex software application High-level synthesis raises the design abstraction level and allows rapid gener- solely by using an assembly language. ation of optimized RTL hardware for performance, area, and power require- In the hardware domain, specification ments. This article gives an overview of state-of-the-art HLS techniques and languages and design methodologies tools. 1,2 Tim Cheng, Editor in Chief have evolved similarly. For this reason, ÀÀ until the late 1960s, ICs were designed, optimized, and laid out by hand. Simula- THE GROWING CAPABILITIES of silicon technology tion at the gate level appeared in the early 1970s, and and the increasing complexity of applications in re- cycle-based simulation became available by 1979. Tech- cent decades have forced design methodologies niques introducedduring the 1980s included place-and- and tools to move to higher abstraction levels. Raising route, schematic circuit capture, formal verification, the abstraction levels and accelerating automation of and static timing analysis. Hardware description lan- both the synthesis and the verification processes have guages (HDLs), such as Verilog (1986) and VHDL for this reason always been key factors in the evolu- (1987), have enabled wide adoption of simulation tion of the design process, which in turn has allowed tools. These HDLs have also served as inputs to logic designers to explore the design space efficiently and synthesis tools leading to the definition of their synthe- rapidly. -

High Level Synthesis with Catapult
High Level Synthesis with Catapult 8.0 Richard Langridge European AE Manager 21 st January 2015 Calypto Overview • Background – Founded in 2002 – SLEC released 2005 & PowerPro 2006 – Acquired Mentor’s Catapult HLS technology and team in 2011 • Operations – Headquarters in San Jose with R&D in California, Oregon, NOIDA India – Sales and support worldwide, with new support office opened in Korea • Technology – Patented Deep Sequential Analysis Technology for verification and power optimization – Industry leading High-Level Synthesis technology – 30 patents granted; 17 pending • Customers – Over 130 customers worldwide • FY14 Results - Record revenue 2 Calypto Design Systems Calypto Design Systems’ Platforms Catapult HL Design & Verification Platform PowerPro RTL Low Power Platform 3 Calypto Design Systems Why Teams Want to Adopt HLS • Accelerate design time by working at higher level of void func (short a[N], abstraction for (int i=0; i<N; i++) { if (cond) – z+=a[i]*b[i]; New features added in days not weeks else – Address complexity through abstraction • Cut verification costs with 1000x speedup vs RTL – Faster design simulation in higher level languages – Easier functional verification and debug • Determine optimal microarchitecture – Rapidly explore multiple options for optimal Power Performance Area (PPA) • Facilitate collaboration, reuse and creation of derivatives – Technology and architectural neutral design descriptions RTL are easily shared, modified and retargeted – HLS becoming an IP enabler 4 Calypto Design Systems Catapult Delivers -

HDL and Programming Languages ■ 6 Languages ■ 6.1 Analogue Circuit Design ■ 6.2 Digital Circuit Design ■ 6.3 Printed Circuit Board Design ■ 7 See Also
Hardware description language - Wikipedia, the free encyclopedia 페이지 1 / 11 Hardware description language From Wikipedia, the free encyclopedia In electronics, a hardware description language or HDL is any language from a class of computer languages, specification languages, or modeling languages for formal description and design of electronic circuits, and most-commonly, digital logic. It can describe the circuit's operation, its design and organization, and tests to verify its operation by means of simulation.[citation needed] HDLs are standard text-based expressions of the spatial and temporal structure and behaviour of electronic systems. Like concurrent programming languages, HDL syntax and semantics includes explicit notations for expressing concurrency. However, in contrast to most software programming languages, HDLs also include an explicit notion of time, which is a primary attribute of hardware. Languages whose only characteristic is to express circuit connectivity between a hierarchy of blocks are properly classified as netlist languages used on electric computer-aided design (CAD). HDLs are used to write executable specifications of some piece of hardware. A simulation program, designed to implement the underlying semantics of the language statements, coupled with simulating the progress of time, provides the hardware designer with the ability to model a piece of hardware before it is created physically. It is this executability that gives HDLs the illusion of being programming languages, when they are more-precisely classed as specification languages or modeling languages. Simulators capable of supporting discrete-event (digital) and continuous-time (analog) modeling exist, and HDLs targeted for each are available. It is certainly possible to represent hardware semantics using traditional programming languages such as C++, although to function such programs must be augmented with extensive and unwieldy class libraries. -

Automatic Instruction-Set Architecture Synthesis for VLIW Processor Cores in the ASAM Project
Automatic Instruction-set Architecture Synthesis for VLIW Processor Cores in the ASAM Project Roel Jordansa,∗, Lech J´o´zwiaka, Henk Corporaala, Rosilde Corvinob aEindhoven University of Technology, Postbus 513, 5600MB Eindhoven, The Netherlands bIntel Benelux B.V., Capronilaan 37, 1119NG Schiphol-Rijk Abstract The design of high-performance application-specific multi-core processor systems still is a time consuming task which involves many manual steps and decisions that need to be performed by experienced design engineers. The ASAM project sought to change this by proposing an auto- matic architecture synthesis and mapping flow aimed at the design of such application specific instruction-set processor (ASIP) systems. The ASAM flow separated the design problem into two cooperating exploration levels, known as the macro-level and micro-level exploration. This paper presents an overview of the micro-level exploration level, which is concerned with the anal- ysis and design of individual processors within the overall multi-core design starting at the initial exploration stages but continuing up to the selection of the final design of the individual proces- sors within the system. The designed processors use a combination of very-long instruction-word (VLIW), single-instruction multiple-data (SIMD), and complex custom DSP-like operations in or- der to provide an area- and energy-efficient and high-performance execution of the program parts assigned to the processor node. In this paper we present an overview of how the micro-level design space exploration interacts with the macro-level, how early performance estimates are used within the ASAM flow to determine the tasks executed by each processor node, and how an initial processor design is then proposed and refined into a highly specialized VLIW ASIP.