A Hybrid Systolic-Dataflow Architecture for Inductive Matrix
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Architecture: Dataflow (Part I)
Computer Architecture: Dataflow (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture n These slides are from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 22: Dataflow I n Video: n http://www.youtube.com/watch? v=D2uue7izU2c&list=PL5PHm2jkkXmh4cDkC3s1VBB7- njlgiG5d&index=19 2 Some Required Dataflow Readings n Dataflow at the ISA level q Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. q Arvind and Nikhil, “Executing a Program on the MIT Tagged- Token Dataflow Architecture,” IEEE TC 1990. n Restricted Dataflow q Patt et al., “HPS, a new microarchitecture: rationale and introduction,” MICRO 1985. q Patt et al., “Critical issues regarding HPS, a high performance microarchitecture,” MICRO 1985. 3 Other Related Recommended Readings n Dataflow n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Lee and Hurson, “Dataflow Architectures and Multithreading,” IEEE Computer 1994. n Restricted Dataflow q Sankaralingam et al., “Exploiting ILP, TLP and DLP with the Polymorphous TRIPS Architecture,” ISCA 2003. q Burger et al., “Scaling to the End of Silicon with EDGE Architectures,” IEEE Computer 2004. 4 Today n Start Dataflow 5 Data Flow Readings: Data Flow (I) n Dennis and Misunas, “A Preliminary Architecture for a Basic Data Flow Processor,” ISCA 1974. n Treleaven et al., “Data-Driven and Demand-Driven Computer Architecture,” ACM Computing Surveys 1982. n Veen, “Dataflow Machine Architecture,” ACM Computing Surveys 1986. n Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985. n Arvind and Nikhil, “Executing a Program on the MIT Tagged-Token Dataflow Architecture,” IEEE TC 1990. -

A Dataflow Architecture for Beamforming Operations
A dataflow architecture for beamforming operations Msc Assignment by Rinse Wester Supervisors: dr. ir. Andr´eB.J. Kokkeler dr. ir. Jan Kuper ir. Kenneth Rovers Anja Niedermeier, M.Sc ir. Andr´eW. Gunst dr. Albert-Jan Boonstra Computer Architecture for Embedded Systems Faculty of EEMCS University of Twente December 10, 2010 Abstract As current radio telescopes get bigger and bigger, so does the demand for processing power. General purpose processors are considered infeasible for this type of processing which is why this thesis investigates the design of a dataflow architecture. This architecture is able to execute the operations which are common in radio astronomy. The architecture presented in this thesis, the FlexCore, exploits regularities found in the mathematics on which the radio telescopes are based: FIR filters, FFTs and complex multiplications. Analysis shows that there is an overlap in these operations. The overlap is used to design the ALU of the architecture. However, this necessitates a way to handle state of the FIR filters. The architecture is not only able to execute dataflow graphs but also uses the dataflow techniques in the implementation. All communication between modules of the architecture are based on dataflow techniques i.e. execution is triggered by the availability of data. This techniques has been implemented using the hardware description language VHDL and forms the basis for the FlexCore design. The FlexCore is implemented using the TSMC 90 nm tech- nology. The design is done in two phases, first a design with a standard ALU is given which acts as reference design, secondly the Extended FlexCore is presented. -

ECE 590: Digital Systems Design Using Hardware Description Language (VHDL) Systolic Implementation of Faddeev's Algorithm in V
Project Report ECE 590: Digital Systems Design using Hardware Description Language (VHDL) Systolic Implementation of Faddeev’s Algorithm in VHDL. Final Project Tejas Tapsale. PSU ID: 973524088. Project Report Introduction: = In this project we are implementing Nash’s systolic implementation and Chuang an He,s systolic implementation for Faddeev’s algorithm. These two implementations have their own advantages and drawbacks. Here in this project report we first see detail of Nash implementation and then we will go for Chaung and He’s implementation. The organization of this report is like this:- 1. First we take detail idea about what is systolic architecture and how it can be used for matrix multiplication and its advantages and disadvantages. 2. Then we discuss about Gaussian Elimination for matrix computation and its properties. 3. Then we will see Faddeev’s algorithm and how it is used. 4. Systolic arrays for MATRIX TRIANGULARIZATION 5. We will discuss Nash implementation in detail and its VHDL coding. 6. Advantages and disadvantage of Nash systolic implementation. 7. Chaung and He’s implementation in detail and its VHDL coding. 8. Difficulties chased in this project. 9. Conclusion. 10. VHDL code for Nash Implementation. 11. VHDL code for Chaung and He’s Implementation. 12. Simulation Results. 13. References. 14. PowerPoint Presentation Project Report 1: Systolic Architecture: = A systolic array is composed of matrix-like rows of data processing units called cells. Data processing units (DPU) are similar to central processing units (CPU)s, (except for the usual lack of a program counter, since operation is transport-triggered, i.e., by the arrival of a data object). -

On the Efficiency of Register File Versus Broadcast Interconnect For
On the Efficiency of Register File versus Broadcast Interconnect for Collective Communications in Data-Parallel Hardware Accelerators Ardavan Pedram, Andreas Gerstlauer Robert A. van de Geijn Department of Electrical and Computer Engineering Department of Computer Science The University of Texas at Austin The University of Texas at Austin fardavan,[email protected] [email protected] Abstract—Reducing power consumption and increasing effi- on broadcast communication among a 2D array of PEs. In ciency is a key concern for many applications. How to design this paper, we focus on the LAC’s data-parallel broadcast highly efficient computing elements while maintaining enough interconnect and on showing how representative collective flexibility within a domain of applications is a fundamental question. In this paper, we present how broadcast buses can communication operations can be efficiently mapped onto eliminate the use of power hungry multi-ported register files this architecture. Such collective communications are a core in the context of data-parallel hardware accelerators for linear component of many matrix or other data-intensive operations algebra operations. We demonstrate an algorithm/architecture that often demand matrix manipulations. co-design for the mapping of different collective communication We compare our design with typical SIMD cores with operations, which are crucial for achieving performance and efficiency in most linear algebra routines, such as GEMM, equivalent data parallelism and with L1 and L2 caches that SYRK and matrix transposition. We compare a broadcast bus amount to an equivalent aggregate storage space. To do so, based architecture with conventional SIMD, 2D-SIMD and flat we examine efficiency and performance of the cores for data register file for these operations in terms of area and energy movement and data manipulation in both GEneral matrix- efficiency. -
![Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model](https://docslib.b-cdn.net/cover/0197/arxiv-1801-05178v1-cs-ar-16-jan-2018-single-instruction-multiple-threads-simt-model-910197.webp)
Arxiv:1801.05178V1 [Cs.AR] 16 Jan 2018 Single-Instruction Multiple Threads (SIMT) Model
Inter-thread Communication in Multithreaded, Reconfigurable Coarse-grain Arrays Dani Voitsechov1 and Yoav Etsion1;2 Electrical Engineering1 Computer Science2 Technion - Israel Institute of Technology {dani,yetsion}@tce.technion.ac.il ABSTRACT the order of scheduling of the threads within a CTA is un- Traditional von Neumann GPGPUs only allow threads to known, a synchronization barrier must be invoked before communicate through memory on a group-to-group basis. consumer threads can read the values written to the shared In this model, a group of producer threads writes interme- memory by their respective producer threads. diate values to memory, which are read by a group of con- Seeking an alternative to the von Neumann GPGPU model, sumer threads after a barrier synchronization. To alleviate both the research community and industry began exploring the memory bandwidth imposed by this method of commu- dataflow-based systolic and coarse-grained reconfigurable ar- nication, GPGPUs provide a small scratchpad memory that chitectures (CGRA) [1–5]. As part of this push, Voitsechov prevents intermediate values from overloading DRAM band- and Etsion introduced the massively multithreaded CGRA width. (MT-CGRA) architecture [6,7], which maps the compute In this paper we introduce direct inter-thread communica- graph of CUDA kernels to a CGRA and uses the dynamic tions for massively multithreaded CGRAs, where intermedi- dataflow execution model to run multiple CUDA threads. ate values are communicated directly through the compute The MT-CGRA architecture leverages the direct connectiv- fabric on a point-to-point basis. This method avoids the ity between functional units, provided by the CGRA fab- need to write values to memory, eliminates the need for a ric, to eliminate multiple von Neumann bottlenecks includ- dedicated scratchpad, and avoids workgroup-global barriers. -

Computer Architectures
Parallel (High-Performance) Computer Architectures Tarek El-Ghazawi Department of Electrical and Computer Engineering The George Washington University Tarek El-Ghazawi, Introduction to High-Performance Computing slide 1 Introduction to Parallel Computing Systems Outline Definitions and Conceptual Classifications » Parallel Processing, MPP’s, and Related Terms » Flynn’s Classification of Computer Architectures Operational Models for Parallel Computers Interconnection Networks MPP’s Performance Tarek El-Ghazawi, Introduction to High-Performance Computing slide 2 Definitions and Conceptual Classification What is Parallel Processing? - A form of data processing which emphasizes the exploration and exploitation of inherent parallelism in the underlying problem. Other related terms » Massively Parallel Processors » Heterogeneous Processing – In the1990s, heterogeneous workstations from different processor vendors – Now, accelerators such as GPUs, FPGAs, Intel’s Xeon Phi, … » Grid computing » Cloud Computing Tarek El-Ghazawi, Introduction to High-Performance Computing slide 3 Definitions and Conceptual Classification Why Massively Parallel Processors (MPPs)? » Increase processing speed and memory allowing studies of problems with higher resolutions or bigger sizes » Provide a low cost alternative to using expensive processor and memory technologies (as in traditional vector machines) Tarek El-Ghazawi, Introduction to High-Performance Computing slide 4 Stored Program Computer The IAS machine was the first electronic computer developed, under -

Systolic Computing on Gpus for Productive Performance
Systolic Computing on GPUs for Productive Performance Hongbo Rong Xiaochen Hao Yun Liang Intel Intel, Peking University Peking University [email protected] [email protected] [email protected] Lidong Xu Hong H Jiang Pradeep Dubey Intel Intel Intel [email protected] [email protected] [email protected] Abstract an SIMT (single-instruction multiple-threads) programming We propose a language and compiler to productively build interface, and rely on an underlying compiler to transparently high-performance software systolic arrays that run on GPUs. map a wrap of threads to SIMD execution units. If data need to Based on a rigorous mathematical foundation (uniform re- be exchanged among threads in the same wrap, programmers currence equations and space-time transform), our language have to write explicit shuffle instructions [19]. has a high abstraction level and covers a wide range of ap- This paper proposes a new programming style that pro- plications. A programmer specifies a projection of a dataflow grams GPUs as building software systolic arrays. Systolic ar- compute onto a linear systolic array, while leaving the detailed rays have been extensively studied since 1978 [15], and shown implementation of the projection to a compiler; the compiler an abundance of practice-oriented applications, mainly in implements the specified projection and maps the linear sys- fields dominated by iterative procedures [32], e.g. image and tolic array to the SIMD execution units and vector registers signal processing, matrix arithmetic, non-numeric applica- of GPUs. In this way, both productivity and performance are tions, relational database [7, 8, 10, 11, 16, 17, 30], and so on. -
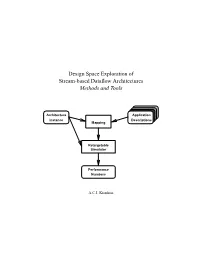
Design Space Exploration of Stream-Based Dataflow Architectures
Design Space Exploration of Stream-based Dataflow Architectures Methods and Tools Architecture Application Instance Descriptions Mapping Retargetable Simulator Performance Numbers A.C.J. Kienhuis Design Space Exploration of Stream-based Dataflow Architectures PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Technische Universiteit Delft, op gezag van de Rector Magnificus prof.ir. K.F. Wakker, in het openbaar te verdedigen ten overstaan van een commissie, door het College voor Promoties aangewezen, op vrijdag 29 Januari 1999 te 10:30 uur door Albert Carl Jan KIENHUIS elektrotechnisch ingenieur geboren te Vleuten. Dit proefschrift is goedgekeurd door de promotor: Prof.dr.ir. P.M. Dewilde Toegevoegd promotor: Dr.ir. E.F. Deprettere. Samenstelling promotiecommissie: Rector Magnificus, voorzitter Prof.dr.ir. P.M. Dewilde, Technische Universiteit Delft, promotor Dr.ir. E.F. Deprettere, Technische Universiteit Delft, toegevoegd promotor Ir. K.A. Vissers, Philips Research Eindhoven Prof.dr.ir. J.L. van Meerbergen, Technische Universiteit Eindhoven Prof.Dr.-Ing. R. Ernst, Technische Universit¨at Braunschweig Prof.dr. S. Vassiliadis, Technische Universiteit Delft Prof.dr.ir. R.H.J.M. Otten, Technische Universiteit Delft Ir. K.A. Vissers en Dr.ir. P. van der Wolf van Philips Research Eindhoven, hebben als begeleiders in belangrijke mate aan de totstandkoming van het proefschrift bijgedragen. CIP-DATA KONINKLIJKE BIBLIOTHEEK, DEN HAAG Kienhuis, Albert Carl Jan Design Space Exploration of Stream-based Dataflow Architectures : Methods and Tools Albert Carl Jan Kienhuis. - Delft: Delft University of Technology Thesis Technische Universiteit Delft. - With index, ref. - With summary in Dutch ISBN 90-5326-029-3 Subject headings: IC-design; Data flow Computing; Systems Analysis Copyright c 1999 by A.C.J. -

Object-Oriented Development for Reconfigurable Architectures
Object-Oriented Development for Reconfigurable Architectures Von der Fakultät für Mathematik und Informatik der Technischen Universität Bergakademie Freiberg genehmigte DISSERTATION zur Erlangung des akademischen Grades Doktor Ingenieur Dr.-Ing., vorgelegt von Dipl.-Inf. (FH) Dominik Fröhlich geboren am 19. Februar 1974 Gutachter: Prof. Dr.-Ing. habil. Bernd Steinbach (Freiberg) Prof. Dr.-Ing. Thomas Beierlein (Mittweida) PD Dr.-Ing. habil. Michael Ryba (Osnabrück) Tag der Verleihung: 20. Juni 2007 To my parents. ABSTRACT Reconfigurable hardware architectures have been available now for several years. Yet the application devel- opment for such architectures is still a challenging and error-prone task, since the methods, languages, and tools being used for development are inappropriate to handle the complexity of the problem. This hampers the widespread utilization, despite of the numerous advantages offered by this type of architecture in terms of computational power, flexibility, and cost. This thesis introduces a novel approach that tackles the complexity challenge by raising the level of ab- straction to system-level and increasing the degree of automation. The approach is centered around the paradigms of object-orientation, platforms, and modeling. An application and all platforms being used for its design, implementation, and deployment are modeled with objects using UML and an action language. The application model is then transformed into an implementation, whereby the transformation is steered by the platform models. In this thesis solutions for the relevant problems behind this approach are discussed. It is shown how UML can be used for complete and precise modeling of applications and platforms. Application development is done at the system-level using a set of well-defined, orthogonal platform models. -

Research Article a Systolic Array-Based FPGA Parallel Architecture for the BLAST Algorithm
International Scholarly Research Network ISRN Bioinformatics Volume 2012, Article ID 195658, 11 pages doi:10.5402/2012/195658 Research Article A Systolic Array-Based FPGA Parallel Architecture for the BLAST Algorithm Xinyu Guo,1 Hong Wang,2 and Vijay Devabhaktuni1 1 Electrical Engineering and Computer Science Department, The University of Toledo, MS.308, 2801 W. Bancroft Street, Toledo, OH 43607, USA 2 Department of Engineering Technology, The University of Toledo, MS.402, 2801 W. Bancroft Street, Toledo, OH 43606, USA Correspondence should be addressed to Hong Wang, [email protected] Received 23 May 2012; Accepted 25 July 2012 Academic Editors: F. Couto, B. Haubold, and J. T. L. Wang Copyright © 2012 Xinyu Guo et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. A design of systolic array-based Field Programmable Gate Array (FPGA) parallel architecture for Basic Local Alignment Search Tool (BLAST) Algorithm is proposed. BLAST is a heuristic biological sequence alignment algorithm which has been used by bio- informatics experts. In contrast to other designs that detect at most one hit in one-clock-cycle, our design applies a Multiple Hits Detection Module which is a pipelining systolic array to search multiple hits in a single-clock-cycle. Further, we designed a Hits Combination Block which combines overlapping hits from systolic array into one hit. These implementations completed the first and second step of BLAST architecture and achieved significant speedup comparing with previously published architectures. -

EE 7722—GPU Microarchitecture
Course Organization Text EE 7722|GPU Microarchitecture EE 7722|GPU Microarchitecture URL: https://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 3316R P.F. Taylor Hall, 578-5482, [email protected], https://www.ece.lsu.edu/koppel Office Hours: Monday - Friday, 15:00-16:00. Prerequisites By Topic: • Computer architecture. • C++ and machine language programming. Text Papers, technical reports, etc. (Available online.) -1 EE 7722 Lecture Transparency. Formatted 11:25, 13 January 2021 from lsli00-TeXize. -1 Course Organization Course Objectives Course Objectives • Understand low-level accelerator (for scientific and ML workloads) organizations. • Be able to fine-tune accelerator codes based on this low-level knowledge. • Understand issues and ideas being discussed for the next generation of accelerators ::: ::: including tensor processing (machine-learning, inference, training) accelerators. -2 EE 7722 Lecture Transparency. Formatted 11:25, 13 January 2021 from lsli00-TeXize. -2 Course Organization Course Topics Course Topics • Performance Limiters (Floating Point, Bandwidth, etc.) • Parallelism Fundamentals • Distinction between processor types: CPU, many-core CPU, (many-thread) GPU, FPGA, large spatial processors, large systolic array. • GPU Architecture and CUDA Programming • GPU Microarchitecture (Low-Level Organization) • Tuning based on machine instruction analysis. • Tensor Processing Units, machine learning accelerators. -3 EE 7722 Lecture Transparency. Formatted 11:25, 13 January 2021 from lsli00-TeXize. -3 Course Organization Graded Material Graded Material Midterm Exam, 35% Fifty minutes in-class or take-home. Final Exam, 35% Two hours in-class or take-home. Yes, it's cumulative. Homework, 30% Written and computer assignments. Lowest grade or unsubmitted assignment dropped. -4 EE 7722 Lecture Transparency. -

Dataflow Computing Models, Languages, and Machines for Intelligence Computations
IEEE TRANSACTIONS ON SOFTWARE ENGINEERING, VOL. 14, NO. 12, DECEMBER 1988 1805 Dataflow Computing Models, Languages, and Machines for Intelligence Computations JAYANTHA HERATH, MEMBER, IEEE, YOSHINOR1 YAMAGUCHI, NOBUO SAITO, MEMBER, IEEE, AND TOSHITSUGU YUBA Abstract-Dataflow computing, a radical departure from von Neu- parallel and nondeterministic computations. The alterna- mann computing, supports multiprocessing on a massive scale and plays tive to sequential processing is parallel processing with a major role in permitting intelligence computing machines to achieve ultrahigh speeds. Intelligence computations consist of large complex high density devices. To solve nondeterministic prob- numerical and nonnumerical computations. Efficient computing models lems, it is necessary to research efficient computing are necessary to represent intelligence computations. An abstract com- models and more efficient heuristics. The machines pro- puting model, a base language specification for the abstract model, cessing intelligence computations must be dynamic. Ef- high-level and low-level language design to map parallel algorithms to ficient control mechanisms for load balancing of re- abstract computing model, parallel architecture design to support computing model and design of support software to map computing sources, communicating networks, garbage collectors, model to arcTiitecture are steps in constructing computing systems. This and schedulers are important in such machines. Computer paper concentrates on dataflow computing for intelligence computa- hardware improved from vacuum tubes to VLSI but there tions and presents a comparison of dataflow computing models, lan- has been no significant change in the sequential abstract guages and dataflow computing machines for numerical and nonnu- computing model, sequential algorithms, languages and merical computations. The high level language-graph transformation that must be performed to achieve high performance for numerical and architecture.