The Micro-Architecture of a Capability-Based Computer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -

Programming Model, Address Mode, HC12 Hardware Introduction
EEL 4744C: Microprocessor Applications Lecture 2 Programming Model, Address Mode, HC12 Hardware Introduction Dr. Tao Li 1 Reading Assignment • Microcontrollers and Microcomputers: Chapter 3, Chapter 4 • Software and Hardware Engineering: Chapter 2 Or • Software and Hardware Engineering: Chapter 4 Plus • CPU12 Reference Manual: Chapter 3 • M68HC12B Family Data Sheet: Chapter 1, 2, 3, 4 Dr. Tao Li 2 EEL 4744C: Microprocessor Applications Lecture 2 Part 1 CPU Registers and Control Codes Dr. Tao Li 3 CPU Registers • Accumulators – Registers that accumulate answers, e.g. the A Register – Can work simultaneously as the source register for one operand and the destination register for ALU operations • General-purpose registers – Registers that hold data, work as source and destination register for data transfers and source for ALU operations • Doubled registers – An N-bit CPU in general uses N-bit data registers – Sometimes 2 of the N-bit registers are used together to double the number of bits, thus “doubled” registers Dr. Tao Li 4 CPU Registers (2) • Pointer registers – Registers that address memory by pointing to specific memory locations that hold the needed data – Contain memory addresses (without offset) • Stack pointer registers – Pointer registers dedicated to variable data and return address storage in subroutine calls • Index registers – Also used to address memory – An effective memory address is found by adding an offset to the content of the involved index register Dr. Tao Li 5 CPU Registers (3) • Segment registers – In some architectures, memory addressing requires that the physical address be specified in 2 parts • Segment part: specifies a memory page • Offset part: specifies a particular place in the page • Condition code registers – Also called flag or status registers – Hold condition code bits generated when instructions are executed, e.g. -

System Design for a Computational-RAM Logic-In-Memory Parailel-Processing Machine
System Design for a Computational-RAM Logic-In-Memory ParaIlel-Processing Machine Peter M. Nyasulu, B .Sc., M.Eng. A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy Ottaw a-Carleton Ins titute for Eleceical and Computer Engineering, Department of Electronics, Faculty of Engineering, Carleton University, Ottawa, Ontario, Canada May, 1999 O Peter M. Nyasulu, 1999 National Library Biôiiothkque nationale du Canada Acquisitions and Acquisitions et Bibliographie Services services bibliographiques 39S Weiiington Street 395. nie WeUingtm OnawaON KlAW Ottawa ON K1A ON4 Canada Canada The author has granted a non- L'auteur a accordé une licence non exclusive licence allowing the exclusive permettant à la National Library of Canada to Bibliothèque nationale du Canada de reproduce, ban, distribute or seU reproduire, prêter, distribuer ou copies of this thesis in microform, vendre des copies de cette thèse sous paper or electronic formats. la forme de microficbe/nlm, de reproduction sur papier ou sur format électronique. The author retains ownership of the L'auteur conserve la propriété du copyright in this thesis. Neither the droit d'auteur qui protège cette thèse. thesis nor substantial extracts fkom it Ni la thèse ni des extraits substantiels may be printed or otherwise de celle-ci ne doivent être imprimés reproduced without the author's ou autrement reproduits sans son permission. autorisation. Abstract Integrating several 1-bit processing elements at the sense amplifiers of a standard RAM improves the performance of massively-paralle1 applications because of the inherent parallelism and high data bandwidth inside the memory chip. -

The Birth, Evolution and Future of Microprocessor
The Birth, Evolution and Future of Microprocessor Swetha Kogatam Computer Science Department San Jose State University San Jose, CA 95192 408-924-1000 [email protected] ABSTRACT timed sequence through the bus system to output devices such as The world's first microprocessor, the 4004, was co-developed by CRT Screens, networks, or printers. In some cases, the terms Busicom, a Japanese manufacturer of calculators, and Intel, a U.S. 'CPU' and 'microprocessor' are used interchangeably to denote the manufacturer of semiconductors. The basic architecture of 4004 same device. was developed in August 1969; a concrete plan for the 4004 The different ways in which microprocessors are categorized are: system was finalized in December 1969; and the first microprocessor was successfully developed in March 1971. a) CISC (Complex Instruction Set Computers) Microprocessors, which became the "technology to open up a new b) RISC (Reduced Instruction Set Computers) era," brought two outstanding impacts, "power of intelligence" and "power of computing". First, microprocessors opened up a new a) VLIW(Very Long Instruction Word Computers) "era of programming" through replacing with software, the b) Super scalar processors hardwired logic based on IC's of the former "era of logic". At the same time, microprocessors allowed young engineers access to "power of computing" for the creative development of personal 2. BIRTH OF THE MICROPROCESSOR computers and computer games, which in turn led to growth in the In 1970, Intel introduced the first dynamic RAM, which increased software industry, and paved the way to the development of high- IC memory by a factor of four. -
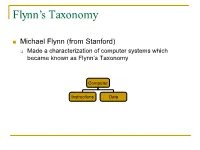
Flynn's Taxonomy
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

Dop – a Cpu Core for Teaching Basics of Computer Architecture
DOP – A CPU CORE FOR TEACHING BASICS OF COMPUTER ARCHITECTURE Milos Becvar, Alois Pluhacek and Jiri Danecek Department of Computer Science and Engineering Faculty of Electrical Engineering Czech Technical University in Prague, Abstract: A simple 16-bit processor core called DOP and its teaching environment is presented. The DOP processor illustrates the basic principles of computer organization and is therefore used in the introductory hardware course. Its major features are simplicity, availability of an FPGA implementation and a C compiler. This paper presents the description of the core, HW and SW tools and teaching methodology. computing performance. The DOP processor core was 1. INTRODUCTION developed at our department together with various SW and HW visualization tools (Danecek et al., 1994a). An introductory computer hardware course should teach students to the fundamental principles of computer The goal of this paper is to describe this processor core internal functionality. Students, who are familiar with and its learning environment for teaching basics of programming in high-level languages, are required to computer organization. The paper is organized as understand the interaction between a processor, a follows - section 2 outlines the introductory course and memory and I/O devices, an internal organization of characterizes the students, section 3 describes the DOP processor, computer arithmetic and basics of digital processor core, section 4 describes the SW and HW design. Our experience has shown that it is not an easy tools supporting this processor and finally section 5 task for most of them. The functionality of the processor outlines the use of the DOP in our introductory course. -

Pipeline and Vector Processing
Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Chapter – 4 Pipeline and Vector Processing 4.1 Pipelining Pipelining is a technique of decomposing a sequential process into suboperations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments. The overlapping of computation is made possible by associating a register with each segment in the pipeline. The registers provide isolation between each segment so that each can operate on distinct data simultaneously. Perhaps the simplest way of viewing the pipeline structure is to imagine that each segment consists of an input register followed by a combinational circuit. o The register holds the data. o The combinational circuit performs the suboperation in the particular segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. The pipeline organization will be demonstrated by means of a simple example. o To perform the combined multiply and add operations with a stream of numbers Ai * Bi + Ci for i = 1, 2, 3, …, 7 Each suboperation is to be implemented in a segment within a pipeline. R1 Ai, R2 Bi Input Ai and Bi R3 R1 * R2, R4 Ci Multiply and input Ci R5 R3 + R4 Add Ci to product Each segment has one or two registers and a combinational circuit as shown in Fig. 9-2. The five registers are loaded with new data every clock pulse. The effect of each clock is shown in Table 4-1. Compiled By: Er. Hari Aryal [[email protected]] Reference: W. Stallings | 1 Computer Organization and Architecture Chapter 4 : Pipeline and Vector processing Fig 4-1: Example of pipeline processing Table 4-1: Content of Registers in Pipeline Example General Considerations Any operation that can be decomposed into a sequence of suboperations of about the same complexity can be implemented by a pipeline processor. -
IBM Z/Architecture Reference Summary
z/Architecture IBMr Reference Summary SA22-7871-06 . z/Architecture IBMr Reference Summary SA22-7871-06 Seventh Edition (August, 2010) This revision differs from the previous edition by containing instructions related to the facilities marked by a bar under “Facility” in “Preface” and minor corrections and clari- fications. Changes are indicated by a bar in the margin. References in this publication to IBM® products, programs, or services do not imply that IBM intends to make these available in all countries in which IBM operates. Any reference to an IBM program product in this publication is not intended to state or imply that only IBM’s program product may be used. Any functionally equivalent pro- gram may be used instead. Additional copies of this and other IBM publications may be ordered or downloaded from the IBM publications web site at http://www.ibm.com/support/documentation. Please direct any comments on the contents of this publication to: IBM Corporation Department E57 2455 South Road Poughkeepsie, NY 12601-5400 USA IBM may use or distribute whatever information you supply in any way it believes appropriate without incurring any obligation to you. © Copyright International Business Machines Corporation 2001-2010. All rights reserved. US Government Users Restricted Rights — Use, duplication, or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. ii z/Architecture Reference Summary Preface This publication is intended primarily for use by z/Architecture™ assembler-language application programmers. It contains basic machine information summarized from the IBM z/Architecture Principles of Operation, SA22-7832, about the zSeries™ proces- sors. It also contains frequently used information from IBM ESA/390 Common I/O- Device Commands and Self Description, SA22-7204, IBM System/370 Extended Architecture Interpretive Execution, SA22-7095, and IBM High Level Assembler for MVS & VM & VSE Language Reference, SC26-4940. -

10. Assembly Language, Models of Computation
10. Assembly Language, Models of Computation 6.004x Computation Structures Part 2 – Computer Architecture Copyright © 2015 MIT EECS 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #1 Beta ISA Summary • Storage: – Processor: 32 registers (r31 hardwired to 0) and PC – Main memory: Up to 4 GB, 32-bit words, 32-bit byte addresses, 4-byte-aligned accesses OPCODE rc ra rb unused • Instruction formats: OPCODE rc ra 16-bit signed constant 32 bits • Instruction classes: – ALU: Two input registers, or register and constant – Loads and stores: access memory – Branches, Jumps: change program counter 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #2 Programming Languages 32-bit (4-byte) ADD instruction: 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 opcode rc ra rb (unused) Means, to the BETA, Reg[4] ß Reg[2] + Reg[3] We’d rather write in assembly language: Today ADD(R2, R3, R4) or better yet a high-level language: Coming up a = b + c; 6.004 Computation Structures L10: Assembly Language, Models of Computation, Slide #3 Assembly Language Symbolic 01101101 11000110 Array of bytes representation Assembler 00101111 to be loaded of stream of bytes 10110001 into memory ..... Source Binary text file machine language • Abstracts bit-level representation of instructions and addresses • We’ll learn UASM (“microassembler”), built into BSim • Main elements: – Values – Symbols – Labels (symbols for addresses) – Macros 6.004 Computation Structures L10: Assembly Language, Models -

Computer Organization
Chapter 12 Computer Organization Central Processing Unit (CPU) • Data section ‣ Receives data from and sends data to the main memory subsystem and I/O devices • Control section ‣ Issues the control signals to the data section and the other components of the computer system Figure 12.1 CPU Input Data Control Main Output device section section Memory device Bus Data flow Control CPU components • 16-bit memory address register (MAR) ‣ 8-bit MARA and 8-bit MARB • 8-bit memory data register (MDR) • 8-bit multiplexers ‣ AMux, CMux, MDRMux ‣ 0 on control line routes left input ‣ 1 on control line routes right input Control signals • Originate from the control section on the right (not shown in Figure 12.2) • Two kinds of control signals ‣ Clock signals end in “Ck” to load data into registers with a clock pulse ‣ Signals that do not end in “Ck” to set up the data flow before each clock pulse arrives 0 1 8 14 15 22 23 A IR T3 M1 0x00 0x01 2 3 9 10 16 17 24 25 LoadCk Figure 12.2 X T4 M2 0x02 0x03 4 5 11 18 19 26 27 5 C SP T1 T5 M3 0x04 0x08 5 6 7 12 13 20 21 28 29 B PC T2 T6 M4 0xFA 0xFC 5 30 31 A CPU registers M5 0xFE 0xFF CBus ABus BBus Bus MARB MARCk MARA MDRCk MDR MDRMux AMux AMux MDRMux CMux 4 ALU ALU CMux Cin Cout C CCk Mem V VCk ANDZ Addr ANDZ Z ZCk Zout 0 Data 0 0 0 N NCk MemWrite MemRead Figure 12.2 (Expanded) 0 1 8 14 15 22 23 A IR T3 M1 0x00 0x01 2 3 9 10 16 17 24 25 LoadCk X T4 M2 0x02 0x03 4 5 11 18 19 26 27 5 C SP T1 T5 M3 0x04 0x08 5 6 7 12 13 20 21 28 29 B PC T2 T6 M4 0xFA 0xFC 5 30 31 A CPU registers M5 0xFE 0xFF CBus ABus BBus -
Computer Organization Structure of a Computer Registers Register
Computer Organization Structure of a Computer z Computer design as an application of digital logic design procedures z Block diagram view address z Computer = processing unit + memory system Processor read/write Memory System central processing data z Processing unit = control + datapath unit (CPU) z Control = finite state machine y Inputs = machine instruction, datapath conditions y Outputs = register transfer control signals, ALU operation control signals codes Control Data Path y Instruction interpretation = instruction fetch, decode, data conditions execute z Datapath = functional units + registers instruction unit execution unit y Functional units = ALU, multipliers, dividers, etc. instruction fetch and functional units interpretation FSM y Registers = program counter, shifters, storage registers and registers CS 150 - Spring 2001 - Computer Organization - 1 CS 150 - Spring 2001 - Computer Organization - 2 Registers Register Transfer z Selectively loaded EN or LD input z Point-to-point connection MUX MUX MUX MUX z Output enable OE input y Dedicated wires y Muxes on inputs of rs rt rd R4 z Multiple registers group 4 or 8 in parallel each register z Common input from multiplexer y Load enables LD OE for each register rs rt rd R4 D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they y Control signals D5 Q5 are left unconnected (high impedance) MUX D4 Q4 for multiplexer D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs z Common bus with output enables D0 CLK