Computer Organization Structure of a Computer Registers Register
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Data Hazards Can Be Removed Effectively
International Journal of Scientific & Engineering Research, Volume 7, Issue 9, September-2016 116 ISSN 2229-5518 How Data Hazards can be removed effectively Muhammad Zeeshan, Saadia Anayat, Rabia and Nabila Rehman Abstract—For fast Processing of instructions in computer architecture, the most frequently used technique is Pipelining technique, the Pipelining is consider an important implementation technique used in computer hardware for multi-processing of instructions. Although multiple instructions can be executed at the same time with the help of pipelining, but sometimes multi-processing create a critical situation that altered the normal CPU executions in expected way, sometime it may cause processing delay and produce incorrect computational results than expected. This situation is known as hazard. Pipelining processing increase the processing speed of the CPU but these Hazards that accrue due to multi-processing may sometime decrease the CPU processing. Hazards can be needed to handle properly at the beginning otherwise it causes serious damage to pipelining processing or overall performance of computation can be effected. Data hazard is one from three types of pipeline hazards. It may result in Race condition if we ignore a data hazard, so it is essential to resolve data hazards properly. In this paper, we tries to present some ideas to deal with data hazards are presented i.e. introduce idea how data hazards are harmful for processing and what is the cause of data hazards, why data hazard accord, how we remove data hazards effectively. While pipelining is very useful but there are several complications and serious issue that may occurred related to pipelining i.e. -
Computer Organization
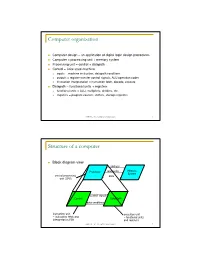
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

The Central Processing Unit(CPU). the Brain of Any Computer System Is the CPU
Computer Fundamentals 1'stage Lec. (8 ) College of Computer Technology Dept.Information Networks The central processing unit(CPU). The brain of any computer system is the CPU. It controls the functioning of the other units and process the data. The CPU is sometimes called the processor, or in the personal computer field called “microprocessor”. It is a single integrated circuit that contains all the electronics needed to execute a program. The processor calculates (add, multiplies and so on), performs logical operations (compares numbers and make decisions), and controls the transfer of data among devices. The processor acts as the controller of all actions or services provided by the system. Processor actions are synchronized to its clock input. A clock signal consists of clock cycles. The time to complete a clock cycle is called the clock period. Normally, we use the clock frequency, which is the inverse of the clock period, to specify the clock. The clock frequency is measured in Hertz, which represents one cycle/second. Hertz is abbreviated as Hz. Usually, we use mega Hertz (MHz) and giga Hertz (GHz) as in 1.8 GHz Pentium. The processor can be thought of as executing the following cycle forever: 1. Fetch an instruction from the memory, 2. Decode the instruction (i.e., determine the instruction type), 3. Execute the instruction (i.e., perform the action specified by the instruction). Execution of an instruction involves fetching any required operands, performing the specified operation, and writing the results back. This process is often referred to as the fetch- execute cycle, or simply the execution cycle. -

The Microarchitecture of a Low Power Register File
The Microarchitecture of a Low Power Register File Nam Sung Kim and Trevor Mudge Advanced Computer Architecture Lab The University of Michigan 1301 Beal Ave., Ann Arbor, MI 48109-2122 {kimns, tnm}@eecs.umich.edu ABSTRACT Alpha 21464, the 512-entry 16-read and 8-write (16-r/8-w) ports register file consumed more power and was larger than The access time, energy and area of the register file are often the 64 KB primary caches. To reduce the cycle time impact, it critical to overall performance in wide-issue microprocessors, was implemented as two 8-r/8-w split register files [9], see because these terms grow superlinearly with the number of read Figure 1. Figure 1-(a) shows the 16-r/8-w file implemented and write ports that are required to support wide-issue. This paper directly as a monolithic structure. Figure 1-(b) shows it presents two techniques to reduce the number of ports of a register implemented as the two 8-r/8-w register files. The monolithic file intended for a wide-issue microprocessor without hardly any register file design is slow because each memory cell in the impact on IPC. Our results show that it is possible to replace a register file has to drive a large number of bit-lines. In register file with 16 read and 8 write ports, intended for an eight- contrast, the split register file is fast, but duplicates the issue processor, with a register file with just 8 read and 8 write contents of the register file in two memory arrays, resulting in ports so that the impact on IPC is a few percent. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

1.1.2. Register File
國 立 交 通 大 學 資訊科學與工程研究所 碩 士 論 文 同步多執行緒架構中可彈性切割與可延展的暫存 器檔案設計之研究 Design of a Flexibly Splittable and Stretchable Register File for SMT Architectures 研 究 生:鐘立傑 指導教授:單智君 教授 中 華 民 國 九 十 六 年 八 月 I II III IV 同步多執行緒架構中可彈性切割與可延展的暫存 器檔案設計之研究 學生:鐘立傑 指導教授:單智君 博士 國立交通大學資訊科學與工程研究所 碩士班 摘 要 如何利用最少的硬體資源來支援同步多執行緒是一個很重要的研究議題,暫存 器檔案(Register file)在微處理器晶片面積中佔有顯著的比例。而且為了支援同步多 執行緒,每一個執行緒享有自己的一份暫存器檔案,這樣的設計會增加晶片的面積。 在本篇論文中,我們提出了一份可彈性切割與可延展的暫存器檔案設計,在這 個設計裡:1.我們可以在需要的時候彈性切割一份暫存器檔案給兩個執行緒來同時 使用,2.適當的延伸暫存器檔案的大小來增加兩個執行緒共用的機會。 藉由我們設計可以得到的益處有:1.增加硬體資源的使用率,2. 減少對於記憶 體的存取以及 3.提升系統的效能。此外我們設計概念可以任意的滿足不同的應用程 式的需求。 V Design of a Flexibly Splittable and Stretchable Register File for SMT Architectures Student:Li-Jie Jhing Advisor:Dr, Jean Jyh-Jiun Shann Institute of Computer Science and Engineering National Chiao-Tung University Abstract How to support simultaneous multithreading (SMT) with minimum resource hence becomes a critical research issue. The register file in a microprocessor typically occupies a significant portion of the chip area, and in order to support SMT, each thread will have a copy of register file. That will increase the area overhead. In this thesis, we propose a register file design techniques that can 1. Split a copy of physical register file flexibly into two independent register sets when required, simultaneously operable for two independent threads. 2. Stretch the size of the physical register file arbitrarily, to increase probability of sharing by two threads. Benefits of these designs are: 1. Increased hardware resource utilization. 2. Reduced memory -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -
Flynn's Taxonomy
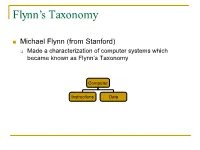
Flynn’s Taxonomy n Michael Flynn (from Stanford) q Made a characterization of computer systems which became known as Flynn’s Taxonomy Computer Instructions Data SISD – Single Instruction Single Data Systems SI SISD SD SIMD – Single Instruction Multiple Data Systems “Vector Processors” SIMD SD SI SIMD SD Multiple Data SIMD SD MIMD Multiple Instructions Multiple Data Systems “Multi Processors” Multiple Instructions Multiple Data SI SIMD SD SI SIMD SD SI SIMD SD MISD – Multiple Instructions / Single Data Systems n Some people say “pipelining” lies here, but this is debatable Single Data Multiple Instructions SIMD SI SD SIMD SI SIMD SI Abbreviations •PC – Program Counter •MAR – Memory Access Register •M – Memory •MDR – Memory Data Register •A – Accumulator •ALU – Arithmetic Logic Unit •IR – Instruction Register •OP – Opcode •ADDR – Address •CLU – Control Logic Unit LOAD X n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- MDR ADD n MAR <- PC n MDR <- M[ MAR ] n IR <- MDR n MAR <- IR[ ADDR ] n DECODER <- IR[ OP ] n MDR <- M[ MAR ] n A <- A+MDR STORE n MDR <- A n M[ MAR ] <- MDR SISD Stack Machine •Stack Trace •Push 1 1 _ •Push 2 2 1 •Add 2 3 •Pop _ 3 •Pop C _ _ •First Stack Machine •B5000 Array Processor Array Processors n One of the first Array Processors was the ILLIIAC IV n Load A1, V[1] n Load B1, Y[1] n Load A2, V[2] n Load B2, Y[2] n Load A3, V[3] n Load B3, Y[3] n ADDALL n Store C1, W[1] n Store C2, W[2] n Store C3, W[3] Memory Interleaving Definition: Memory interleaving is a design used to gain faster access to memory, by organizing memory into separate memories, each with their own MAR (memory address register). -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Implementation, Verification and Validation of an Openrisc-1200
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 1, 2019 Implementation, Verification and Validation of an OpenRISC-1200 Soft-core Processor on FPGA Abdul Rafay Khatri Department of Electronic Engineering, QUEST, NawabShah, Pakistan Abstract—An embedded system is a dedicated computer system in which hardware and software are combined to per- form some specific tasks. Recent advancements in the Field Programmable Gate Array (FPGA) technology make it possible to implement the complete embedded system on a single FPGA chip. The fundamental component of an embedded system is a microprocessor. Soft-core processors are written in hardware description languages and functionally equivalent to an ordinary microprocessor. These soft-core processors are synthesized and implemented on the FPGA devices. In this paper, the OpenRISC 1200 processor is used, which is a 32-bit soft-core processor and Fig. 1. General block diagram of embedded systems. written in the Verilog HDL. Xilinx ISE tools perform synthesis, design implementation and configure/program the FPGA. For verification and debugging purpose, a software toolchain from (RISC) processor. This processor consists of all necessary GNU is configured and installed. The software is written in C components which are available in any other microproces- and Assembly languages. The communication between the host computer and FPGA board is carried out through the serial RS- sor. These components are connected through a bus called 232 port. Wishbone bus. In this work, the OR1200 processor is used to implement the system on a chip technology on a Virtex-5 Keywords—FPGA Design; HDLs; Hw-Sw Co-design; Open- FPGA board from Xilinx.