Implementation, Verification and Validation of an Openrisc-1200
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Debugging System for Openrisc 1000- Based Systems
Debugging System for OpenRisc 1000- based Systems Nathan Yawn [email protected] 05/12/09 Copyright (C) 2008 Nathan Yawn Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license should be included with this document. If not, the license may be obtained from www.gnu.org, or by writing to the Free Software Foundation. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. History Rev Date Author Comments 1.0 20/7/2008 Nathan Yawn Initial version Contents 1.Introduction.............................................................................................................................................5 1.1.Overview.........................................................................................................................................5 1.2.Versions...........................................................................................................................................6 1.3.Stub-based methods.........................................................................................................................6 2.System Components................................................................................................................................7 -

Embedded Processors on FPGA: Hard-Core Vs Soft-Core Vivek J
Grand Valley State University ScholarWorks@GVSU Masters Theses Graduate Research and Creative Practice 5-19-2017 Embedded processors on FPGA: Hard-core vs Soft-core Vivek J. Vazhoth Kanhiroth Grand Valley State University Follow this and additional works at: http://scholarworks.gvsu.edu/theses Part of the Engineering Commons Recommended Citation Vazhoth Kanhiroth, Vivek J., "Embedded processors on FPGA: Hard-core vs Soft-core" (2017). Masters Theses. 845. http://scholarworks.gvsu.edu/theses/845 This Thesis is brought to you for free and open access by the Graduate Research and Creative Practice at ScholarWorks@GVSU. It has been accepted for inclusion in Masters Theses by an authorized administrator of ScholarWorks@GVSU. For more information, please contact [email protected]. Embedded processors on FPGA: Hard-core vs Soft-core Vivek Jayakrishnan Vazhoth Kanhiroth A Thesis submitted to the Graduate Faculty of GRAND VALLEY STATE UNIVERSITY In Partial Fulfilment of the Requirements For the Degree of Master of Science in Electrical Engineering Padnos College of Engineering and Computing April 2017 DEDICATION To my parents Jayakrishnan and Jayalakshmi who are my biggest inspiration and to my mentor Rajesh without whose help I would never have come out of my shell. 3 ACKNOWLEDGEMENTS I would like to thank my Thesis Advisor Dr. Chirag Parikh without whose patience, guidance and understanding I would not have finished this thesis. I would also like to thank my Thesis committee members Dr. Christian Trefftz and Dr. Azizur Rahman for their valuable inputs and feedback about my thesis. I am indebted to Dr. Shabbir Choudhuri for always being approachable and helping me on innumerable occasions over the last 3 years. -
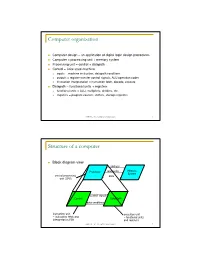
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Xilinx Synthesis and Verification Design Guide
Synthesis and Simulation Design Guide 8.1i R R Xilinx is disclosing this Document and Intellectual Property (hereinafter “the Design”) to you for use in the development of designs to operate on, or interface with Xilinx FPGAs. Except as stated herein, none of the Design may be copied, reproduced, distributed, republished, downloaded, displayed, posted, or transmitted in any form or by any means including, but not limited to, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of Xilinx. Any unauthorized use of the Design may violate copyright laws, trademark laws, the laws of privacy and publicity, and communications regulations and statutes. Xilinx does not assume any liability arising out of the application or use of the Design; nor does Xilinx convey any license under its patents, copyrights, or any rights of others. You are responsible for obtaining any rights you may require for your use or implementation of the Design. Xilinx reserves the right to make changes, at any time, to the Design as deemed desirable in the sole discretion of Xilinx. Xilinx assumes no obligation to correct any errors contained herein or to advise you of any correction if such be made. Xilinx will not assume any liability for the accuracy or correctness of any engineering or technical support or assistance provided to you in connection with the Design. THE DESIGN IS PROVIDED “AS IS” WITH ALL FAULTS, AND THE ENTIRE RISK AS TO ITS FUNCTION AND IMPLEMENTATION IS WITH YOU. YOU ACKNOWLEDGE AND AGREE THAT YOU HAVE NOT RELIED ON ANY ORAL OR WRITTEN INFORMATION OR ADVICE, WHETHER GIVEN BY XILINX, OR ITS AGENTS OR EMPLOYEES. -

AN 307: Altera Design Flow for Xilinx Users Supersedes Information Published in Previous Versions
Altera Design Flow for Xilinx Users June 2005, ver. 5.0 Application Note 307 Introduction Designing for Altera® Programmable Logic Devices (PLDs) is very similar, both in concept and in practice, to designing for Xilinx PLDs. In most cases, you can simply import your register transfer level (RTL) into Altera’s Quartus® II software and begin compiling your design to the target device. This document will demonstrate the similar flows between the Altera Quartus II software and the Xilinx ISE software. For designs, which the designer has included Xilinx CORE generator modules or instantiated primitives, the bulk of this document guides the designer in design conversion considerations. Who Should Read This Document The first and third sections of this application note are designed for engineers who are familiar with the Xilinx ISE software and are using Altera’s Quartus II software. This first section describes the possible design flows available with the Altera Quartus II software and demonstrates how similar they are to the Xilinx ISE flows. The third section shows you how to convert your ISE constraints into Quartus II constraints. f For more information on setting up your design in the Quartus II software, refer to the Altera Quick Start Guide For Quartus II Software. The second section of this application note is designed for engineers whose design code contains Xilinx CORE generator modules or instantiated primitives. The second section provides comprehensive information on how to migrate a design targeted at a Xilinx device to one that is compatible with an Altera device. If your design contains pure behavioral coding, you can skip the second section entirely. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Programmable Logic Design Grzegorz Budzyń Lecture 11: Microcontroller
ProgrammableProgrammable LogicLogic DesignDesign GrzegorzGrzegorz BudzyBudzy ńń LLectureecture 11:11: MicrocontrollerMicrocontroller corescores inin FPGAFPGA Plan • Introduction • PicoBlaze • MicroBlaze • Cortex-M1 Introduction Introduction • There are dozens of 8-bit microcontroller architectures and instruction sets • Modern FPGAs can efficiently implement practically any 8-bit microcontroller • Available FPGA soft cores support popular instruction sets such as the PIC, 8051, AVR, 6502, 8080, and Z80 microcontrollers • Each significant FPGA producer offers their own soft core solution Introduction • Microcontrollers and FPGAs both successfully implement practically any digital logic function. • Each solution has unique advantages in cost, performance, and ease of use. • Microcontrollers are well suited to control applications, especially with widely changing requirements. • The FPGA resources required to implement the microcontroller are relatively constant. Introduction • The same FPGA logic is re-used by the various microcontroller instructions, conserving resources. • The program memory requirements grow with increasing complexity • Programming control sequences or state machines in assembly code is often easier than creating similar structures in FPGA logic • Microcontrollers are typically limited by performance. Each instruction executes sequentially. Introduction – block diagram Source:[1] FPGA vs Soft Core Microcontroller: – Easy to program, excellent for control and state machine applications – Resource requirements remain constant -

RTL Design and IP Generation Tutorial
RTL Design and IP Generation Tutorial PlanAhead Design Tool UG675(v14.5) April 10, 2013 This tutorial document was last validated using the following software version: ISE Design Suite 14.5 If using a later software version, there may be minor differences between the images and results shown in this document with what you will see in the Design Suite.Suite. Notice of Disclaimer The information disclosed to you hereunder (the "Materials") is provided solely for the selection and use of Xilinx products. To the maximum extent permitted by applicable law: (1) Materials are made available "AS IS" and with all faults, Xilinx hereby DISCLAIMS ALL WARRANTIES AND CONDITIONS, EXPRESS, IMPLIED, OR STATUTORY, INCLUDING BUT NOT LIMITED TO WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT, OR FITNESS FOR ANY PARTICULAR PURPOSE; and (2) Xilinx shall not be liable (whether in contract or tort, including negligence, or under any other theory of liability) for any loss or damage of any kind or nature related to, arising under, or in connection with, the Materials (including your use of the Materials), including for any direct, indirect, special, incidental, or consequential loss or damage (including loss of data, profits, goodwill, or any type of loss or damage suffered as a result of any action brought by a third party) even if such damage or loss was reasonably foreseeable or Xilinx had been advised of the possibility of the same. Xilinx assumes no obligation to correct any errors contained in the Materials or to notify you of updates to the Materials or to product specifications. You may not reproduce, modify, distribute, or publicly display the Materials without prior written consent.