The Microarchitecture of the Pentium 4 Processor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® IA-64 Architecture Software Developer's Manual
Intel® IA-64 Architecture Software Developer’s Manual Volume 1: IA-64 Application Architecture Revision 1.1 July 2000 Document Number: 245317-002 THIS DOCUMENT IS PROVIDED “AS IS” WITH NO WARRANTIES WHATSOEVER, INCLUDING ANY WARRANTY OF MERCHANTABILITY, NONINFRINGEMENT, FITNESS FOR ANY PARTICULAR PURPOSE, OR ANY WARRANTY OTHERWISE ARISING OUT OF ANY PROPOSAL, SPECIFICATION OR SAMPLE. Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel® IA-64 processors may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1-800- 548-4725, or by visiting Intel’s website at http://developer.intel.com/design/litcentr. -

Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa Chikkagoudar, Dr
Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa chikkagoudar, Dr. U. N. Sinha, Prof. B. L. Desai. [email protected], [email protected], [email protected] Department of Electronics and Communication B. V. Bhoomaraddi college of Engg. And Tech. Hubli-580031 Abstract: aero dynamical problems, [1].Since 1986, six Flosolver MK6 is a Parallel processing system, generations of Flosolver machine have evolved based on distributed memory concept and built namely Flosolver MK-1, MK-2, MK-3, MK-4, MK-5 around Pentium-III processors, which acts as and MK-6. processing elements (PEs). Communication Flosolver MK-6 is the latest of the parallel between processing elements is very important, computer based on 128 Pentium III processors which is done through hardware switch called (which act as processing elements, PEs) in 64 dual Floswitch. Floswitch supports both message processor boards each with 1GB RAM and 80 GB passing as well as message processing. Message HDD. It is essentially a distributed memory system. processing is a unique feature of Floswitch. A group of four Dual processor boards with a Floswitch and an optical module is a natural cluster. In existing MK-6 system, communication 16 such clusters form the system. Processing between PEs is done through the Intel 486-based elements (PEs) communicate through Floswitch (a Floswitch, which operates at 32MHz and has 32- communication switch) using PCI-DPM interface bit wide data path. The data transfer rate and card. Clusters communicate through Optical module. floating point computation of existing switch need to be increased. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -
Computer Organization
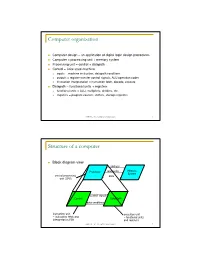
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Validating the Intel® Pentium® 4 Microprocessor
16.1 9DOLGDWLQJ WKH ,QWHO 3HQWLXP 0LFURSURFHVVRU %RE%HQWOH\ ,QWHO&RUSRUDWLRQ 1(WK$YHQXH +LOOVERUR2UHJRQ86$ EREEHQWOH\#LQWHOFRP ABSTRACT 2. OVERVIEW Developing a new leading edge IA-32 microprocessor is an The Pentium® 4 processor is Intel’s most advanced IA-32 immensely complicated undertaking. In the case of the Pentium® microprocessor, incorporating a host of new microarchitectural 4 processor, the microarchitecture is significantly more complex features including a 400-MHz system bus, hyper-pipelined than any previous IA-32 microprocessor and the implementation technology, advanced dynamic execution, rapid execution engine, borrows almost nothing from any previous implementation. This advanced transfer cache, execution trace cache, and Streaming paper describes how we went about the task of finding bugs in the SIMD (Single Instruction, Multiple Data) Extensions 2 (SSE2). Pentium® 4 processor design prior to initial silicon, and what we For the most part, we applied similar tools and methodologies to found along the way. validating the Pentium® 4 processor that we had used previously General Terms on the Pentium® Pro processor. However, we developed new Management, Verification. methodologies and tools in response to lessons learnt from previous projects, and to address some of the new challenges that the Pentium® 4 processor design presented from a validation 1. INTRODUCTION perspective. In particular, the use of Formal Verification, Cluster Validation case studies are relatively rare in the literature of Test Environments and focused Power Reduction Validation were computer architecture and design ([1] and [2] contain lists of either new or greatly extended from previous projects; each of some recent papers) and case studies of commercial these is discussed in more detail in a section of this paper microprocessors are even rarer. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

Implementation, Verification and Validation of an Openrisc-1200
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 1, 2019 Implementation, Verification and Validation of an OpenRISC-1200 Soft-core Processor on FPGA Abdul Rafay Khatri Department of Electronic Engineering, QUEST, NawabShah, Pakistan Abstract—An embedded system is a dedicated computer system in which hardware and software are combined to per- form some specific tasks. Recent advancements in the Field Programmable Gate Array (FPGA) technology make it possible to implement the complete embedded system on a single FPGA chip. The fundamental component of an embedded system is a microprocessor. Soft-core processors are written in hardware description languages and functionally equivalent to an ordinary microprocessor. These soft-core processors are synthesized and implemented on the FPGA devices. In this paper, the OpenRISC 1200 processor is used, which is a 32-bit soft-core processor and Fig. 1. General block diagram of embedded systems. written in the Verilog HDL. Xilinx ISE tools perform synthesis, design implementation and configure/program the FPGA. For verification and debugging purpose, a software toolchain from (RISC) processor. This processor consists of all necessary GNU is configured and installed. The software is written in C components which are available in any other microproces- and Assembly languages. The communication between the host computer and FPGA board is carried out through the serial RS- sor. These components are connected through a bus called 232 port. Wishbone bus. In this work, the OR1200 processor is used to implement the system on a chip technology on a Virtex-5 Keywords—FPGA Design; HDLs; Hw-Sw Co-design; Open- FPGA board from Xilinx. -

Intel(R) Pentium(R) 4 Processor on 90 Nm Process Datasheet
Intel® Pentium® 4 Processor on 90 nm Process Datasheet 2.80 GHz – 3.40 GHz Frequencies Supporting Hyper-Threading Technology1 for All Frequencies with 800 MHz Front Side Bus February 2005 Document Number: 300561-003 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Pentium® 4 processor on 90 nm process may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. 1Hyper-Threading Technology requires a computer system with an Intel® Pentium® 4 processor supporting HT Technology and a Hyper-Threading Technology enabled chipset, BIOS and operating system. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References .............................................