The Design for Therapeutic Agents of Leucine Rich Repeat Protein Using Bioinformatics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nucleocytoplasmic Shuttling of the Glucocorticoid Receptor Is Influenced by Tetratricopeptide Repeat-Containing Proteins Gisela I
© 2020. Published by The Company of Biologists Ltd | Journal of Cell Science (2020) 133, jcs238873. doi:10.1242/jcs.238873 RESEARCH ARTICLE Nucleocytoplasmic shuttling of the glucocorticoid receptor is influenced by tetratricopeptide repeat-containing proteins Gisela I. Mazaira1,*, Pablo C. Echeverria2,* and Mario D. Galigniana1,3,‡ ABSTRACT FKBP52 (also known as FKBP4), FKBP51 (FKBP5) and CyP40 It has been demonstrated that tetratricopeptide-repeat (TPR) domain (PPID), and the immunophilin-like proteins PP5, FKBPL (WISp39) proteins regulate the subcellular localization of glucocorticoid receptor and FKBP37 (ARA9/XAP2/AIP) are counted among the best (GR). This study analyses the influence of the TPR domain of high characterized members of the TPR domain family of proteins molecular weight immunophilins in the retrograde transport and associated with nuclear receptor family members via Hsp90 (Pratt nuclear retention of GR. Overexpression of the TPR peptide et al., 2004a; Storer et al., 2011). TPR domains are composed of prevented efficient nuclear accumulation of the GR by disrupting the loosely conserved 34 amino acid sequence motifs that are found in formation of complexes with the dynein-associated immunophilin arrays comprising between 2 and 20 repeats, wherein the repeats pack FKBP52 (also known as FKBP4), the adaptor transporter importin-β1 against each other giving rise to coiled and superhelical structures (KPNB1), the nuclear pore-associated glycoprotein Nup62 and nuclear (Perez-Riba and Itzhaki, 2019). Originally identified in components of matrix-associated structures. We also show that nuclear import of GR the anaphase-promoting complex (Sikorski et al., 1991), TPR was impaired, whereas GR nuclear export was enhanced. domains are now known to mediate specific protein interactions in Interestingly, the CRM1 (exportin-1) inhibitor leptomycin-B abolished numerous cellular contexts. -

Ankrd9 Is a Metabolically-Controlled Regulator of Impdh2 Abundance and Macro-Assembly
ANKRD9 IS A METABOLICALLY-CONTROLLED REGULATOR OF IMPDH2 ABUNDANCE AND MACRO-ASSEMBLY by Dawn Hayward A dissertation submitted to The Johns Hopkins University in conformity with the requirements of the degree of Doctor of Philosophy Baltimore, Maryland April 2019 ABSTRACT Members of a large family of Ankyrin Repeat Domains proteins (ANKRD) regulate numerous cellular processes by binding and changing properties of specific protein targets. We show that interactions with a target protein and the functional outcomes can be markedly altered by cells’ metabolic state. ANKRD9 facilitates degradation of inosine monophosphate dehydrogenase 2 (IMPDH2), the rate-limiting enzyme in GTP biosynthesis. Under basal conditions ANKRD9 is largely segregated from the cytosolic IMPDH2 by binding to vesicles. Upon nutrient limitation, ANKRD9 loses association with vesicles and assembles with IMPDH2 into rod-like structures, in which IMPDH2 is stable. Inhibition of IMPDH2 with Ribavirin favors ANKRD9 binding to rods. The IMPDH2/ANKRD9 assembly is reversed by guanosine, which restores association of ANKRD9 with vesicles. The conserved Cys109Cys110 motif in ANKRD9 is required for the vesicles-to-rods transition as well as binding and regulation of IMPDH2. ANKRD9 knockdown increases IMPDH2 levels and prevents formation of IMPDH2 rods upon nutrient limitation. Thus, the status of guanosine pools affects the mode of ANKRD9 action towards IMPDH2. Advisor: Dr. Svetlana Lutsenko, Department of Physiology, Johns Hopkins University School of Medicine Second reader: -

Identification of Cyclophilin Gene Family in Soybean and Characterization of Gmcyp1
Western University Scholarship@Western Electronic Thesis and Dissertation Repository 7-4-2013 12:00 AM Identification of Cyclophilin gene family in soybean and characterization of GmCYP1 Hemanta Raj Mainali The University of Western Ontario Supervisor Dr. Sangeeta Dhaubhadel The University of Western Ontario Graduate Program in Biology A thesis submitted in partial fulfillment of the equirr ements for the degree in Master of Science © Hemanta Raj Mainali 2013 Follow this and additional works at: https://ir.lib.uwo.ca/etd Part of the Agricultural Science Commons, Biochemistry Commons, Bioinformatics Commons, Biology Commons, Biotechnology Commons, Molecular Biology Commons, Plant Biology Commons, and the Plant Breeding and Genetics Commons Recommended Citation Mainali, Hemanta Raj, "Identification of Cyclophilin gene family in soybean and characterization of GmCYP1" (2013). Electronic Thesis and Dissertation Repository. 1362. https://ir.lib.uwo.ca/etd/1362 This Dissertation/Thesis is brought to you for free and open access by Scholarship@Western. It has been accepted for inclusion in Electronic Thesis and Dissertation Repository by an authorized administrator of Scholarship@Western. For more information, please contact [email protected]. Identification of Cyclophilin gene family in soybean and characterization of GmCYP1 (Thesis format: Monograph) by Hemanta Raj Mainali Graduate Program in Biology A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science The School of Graduate and Postdoctoral Studies The University of Western Ontario London, Ontario, Canada © Hemanta Raj Mainali 2013 Abstract I identified members of the Cyclophilin (CYP) gene family in soybean (Glycine max) and characterized the GmCYP1, one of the members of soybean CYP. -

Repeat Proteins Challenge the Concept of Structural Domains
844 Biochemical Society Transactions (2015) Volume 43, part 5 Repeat proteins challenge the concept of structural domains Rocıo´ Espada*1, R. Gonzalo Parra*1, Manfred J. Sippl†, Thierry Mora‡, Aleksandra M. Walczak§ and Diego U. Ferreiro*2 *Protein Physiology Lab, Dep de Qu´ımica Biologica, ´ Facultad de Ciencias Exactas y Naturales, UBA-CONICET-IQUIBICEN, Buenos Aires, C1430EGA, Argentina †Center of Applied Molecular Engineering, Division of Bioinformatics, Department of Molecular Biology, University of Salzburg, 5020 Salzburg, Austria ‡Laboratoire de physique statistique, CNRS, UPMC and Ecole normale superieure, ´ 24 rue Lhomond, 75005 Paris, France §Laboratoire de physique theorique, ´ CNRS, UPMC and Ecole normale superieure, ´ 24 rue Lhomond, 75005 Paris, France Abstract Structural domains are believed to be modules within proteins that can fold and function independently. Some proteins show tandem repetitions of apparent modular structure that do not fold independently, but rather co-operate in stabilizing structural forms that comprise several repeat-units. For many natural repeat-proteins, it has been shown that weak energetic links between repeats lead to the breakdown of co-operativity and the appearance of folding sub-domains within an apparently regular repeat array. The quasi-1D architecture of repeat-proteins is crucial in detailing how the local energetic balances can modulate the folding dynamics of these proteins, which can be related to the physiological behaviour of these ubiquitous biological systems. Introduction and between repeats, challenging the concept of structural It was early on noted that many natural proteins typically domain. collapse stretches of amino acid chains into compact units, defining structural domains [1]. These domains typically correlate with biological activities and many modern proteins can be described as composed by novel ‘domain arrange- Definition of the repeat-units ments’ [2]. -

Further Insights Into the Regulation of the Fanconi Anemia FANCD2 Protein
University of Rhode Island DigitalCommons@URI Open Access Dissertations 2015 Further Insights Into the Regulation of the Fanconi Anemia FANCD2 Protein Rebecca Anne Boisvert University of Rhode Island, [email protected] Follow this and additional works at: https://digitalcommons.uri.edu/oa_diss Recommended Citation Boisvert, Rebecca Anne, "Further Insights Into the Regulation of the Fanconi Anemia FANCD2 Protein" (2015). Open Access Dissertations. Paper 397. https://digitalcommons.uri.edu/oa_diss/397 This Dissertation is brought to you for free and open access by DigitalCommons@URI. It has been accepted for inclusion in Open Access Dissertations by an authorized administrator of DigitalCommons@URI. For more information, please contact [email protected]. FURTHER INSIGHTS INTO THE REGULATION OF THE FANCONI ANEMIA FANCD2 PROTEIN BY REBECCA ANNE BOISVERT A DISSERTATION SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN CELL AND MOLECULAR BIOLOGY UNIVERSITY OF RHODE ISLAND 2015 DOCTOR OF PHILOSOPHY DISSERTATION OF REBECCA ANNE BOISVERT APPROVED: Dissertation Committee: Major Professor Niall Howlett Paul Cohen Becky Sartini Nasser H. Zawia DEAN OF THE GRADUATE SCHOOL UNIVERSITY OF RHODE ISLAND 2015 ABSTRACT Fanconi anemia (FA) is a rare autosomal and X-linked recessive disorder, characterized by congenital abnormalities, pediatric bone marrow failure and cancer susceptibility. FA is caused by biallelic mutations in any one of 16 genes. The FA proteins function cooperatively in the FA-BRCA pathway to repair DNA interstrand crosslinks (ICLs). The monoubiquitination of FANCD2 and FANCI is a central step in the activation of the FA-BRCA pathway and is required for targeting these proteins to chromatin. -

A Structural Guide to Proteins of the NF-Kb Signaling Module
Downloaded from http://cshperspectives.cshlp.org/ on September 26, 2021 - Published by Cold Spring Harbor Laboratory Press A Structural Guide to Proteins of the NF-kB Signaling Module Tom Huxford1 and Gourisankar Ghosh2 1Department of Chemistry and Biochemistry, San Diego State University, 5500 Campanile Drive, San Diego, California 92182-1030 2Department of Chemistry and Biochemistry, University of California, San Diego, 9500 Gilman Drive, La Jolla, California 92093-0375 Correspondence: [email protected] The prosurvival transcription factor NF-kB specifically binds promoter DNA to activate target gene expression. NF-kB is regulated through interactions with IkB inhibitor proteins. Active proteolysis of these IkB proteins is, in turn, under the control of the IkB kinase complex (IKK). Together, these three molecules form the NF-kB signaling module. Studies aimed at charac- terizing the molecular mechanisms of NF-kB, IkB, and IKK in terms of their three-dimen- sional structures have lead to a greater understanding of this vital transcription factor system. F-kB is a master transcription factor that from the perspective of their three-dimensional Nresponds to diverse cell stimuli by activat- structures. ing the expression of stress response genes. Multiple signals, including cytokines, growth factors, engagement of the T-cell receptor, and NF-kB bacterial and viral products, induce NF-kB Introduction to NF-kB transcriptional activity (Hayden and Ghosh 2008). A point of convergence for the myriad NF-kB was discovered in the laboratory of of NF-kB inducing signals is the IkB kinase David Baltimore as a nuclear activity with bind- complex (IKK). Active IKK in turn controls ing specificity toward a ten-base-pair DNA transcription factor NF-kB by regulating pro- sequence 50-GGGACTTTCC-30 present within teolysis of the IkB inhibitor protein (Fig. -
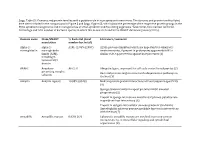
Supp. Table S2: Domains and Protein Families with a Putative Role in Host-Symbiont Interactions
Supp. Table S2: Domains and protein families with a putative role in host-symbiont interactions. The domains and protein families listed here were included in the comparisons in Figure 5 and Supp. Figure S5, which show the percentage of the respective protein groups in the Riftia symbiont metagenome and in metagenomes of other symbiotic and free-living organisms. % bacterial, total number bacterial: Percentage and total number of bacterial species in which this domain is found in the SMART database (January 2019). Domain name Pfam/SMART % bacterial (total Literature/comment annotation number bacterial) Alpha-2- alpha-2- A2M: 42.05% (2057) A2Ms: protease inhibitors which are important for eukaryotic macroglobulin macroglobulin innate immunity, if present in prokaryotes apparently fulfill a family (A2M), similar role, e.g. protection against host proteases (1) including N- terminal MG1 domain ANAPC Anaphase- APC2: 0 Ubiquitin ligase, important for cell cycle control in eukaryotes (2) promoting complex Bacterial proteins might interact with ubiquitination pathways in subunits the host (3) Ankyrin Ankyrin repeats 10.88% (8348) Mediate protein-protein interactions without sequence specificity (4) Sponge symbiont ankyrin-repeat proteins inhibit amoebal phagocytosis (5) Present in sponge microbiome metatranscriptomes, putative role in symbiont-host interactions (6) Present in obligate intracellular amoeba symbiont Candidatus Amoebophilus asiaticus genome, probable function in interactions with the host (7) Armadillo Armadillo repeats 0.83% (67) -

Insights Into Regulation of Human RAD51 Nucleoprotein Filament Activity During
Insights into Regulation of Human RAD51 Nucleoprotein Filament Activity During Homologous Recombination Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Ravindra Bandara Amunugama, B.S. Biophysics Graduate Program The Ohio State University 2011 Dissertation Committee: Richard Fishel PhD, Advisor Jeffrey Parvin MD PhD Charles Bell PhD Michael Poirier PhD Copyright by Ravindra Bandara Amunugama 2011 ABSTRACT Homologous recombination (HR) is a mechanistically conserved pathway that occurs during meiosis and following the formation of DNA double strand breaks (DSBs) induced by exogenous stresses such as ionization radiation. HR is also involved in restoring replication when replication forks have stalled or collapsed. Defective recombination machinery leads to chromosomal instability and predisposition to tumorigenesis. However, unregulated HR repair system also leads to similar outcomes. Fortunately, eukaryotes have evolved elegant HR repair machinery with multiple mediators and regulatory inputs that largely ensures an appropriate outcome. A fundamental step in HR is the homology search and strand exchange catalyzed by the RAD51 recombinase. This process requires the formation of a nucleoprotein filament (NPF) on single-strand DNA (ssDNA). In Chapter 2 of this dissertation I describe work on identification of two residues of human RAD51 (HsRAD51) subunit interface, F129 in the Walker A box and H294 of the L2 ssDNA binding region that are essential residues for salt-induced recombinase activity. Mutation of F129 or H294 leads to loss or reduced DNA induced ATPase activity and formation of a non-functional NPF that eliminates recombinase activity. DNA binding studies indicate that these residues may be essential for sensing the ATP nucleotide for a functional NPF formation. -

Consensus Tetratricopeptide Repeat Proteins Are Complex Superhelical 2 Nanosprings
bioRxiv preprint doi: https://doi.org/10.1101/2021.03.27.437344; this version posted August 30, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Consensus tetratricopeptide repeat proteins are complex superhelical 2 nanosprings 1, ∗ 1 1 2 2 3 Marie Synakewicz, Rohan S. Eapen, Albert Perez-Riba, Daniela Bauer, Andreas Weißl, 3 3 2 1, ∗ 4, ∗ 4 Gerhard Fischer, Marko Hyv¨onen, Matthias Rief, Laura S. Itzhaki, and Johannes Stigler 1 5 Department of Pharmacology, University of Cambridge, 6 Tennis Court Road, Cambridge, CB2 1PD, United Kingdom 2 7 Physik-Department, Technische Universit¨atM¨unchen, 8 James-Franck-Straße 1, 85748 Garching, Germany 3 9 Department of Biochemistry, University of Cambridge, 10 Tennis Court Road, Cambridge, CB2 1GA, United Kingdom 4 11 Gene Center Munich, Ludwig-Maximilians-Universit¨atM¨unchen, 12 Feodor-Lynen-Straße 25, 81377 M¨unchen,Germany 13 (Dated: August 20, 2021) Abstract. Tandem-repeat proteins comprise small secondary structure motifs that stack to form one- dimensional arrays with distinctive mechanical properties that are proposed to direct their cellular functions. Here, we use single-molecule optical tweezers to study the folding of consensus-designed tetratricopeptide repeats (CTPRs) | superhelical arrays of short helix-turn-helix motifs. We find that CTPRs display a spring-like mechanical response in which individual repeats undergo rapid equilibrium fluctuations between folded and unfolded conformations. We rationalise the force response using Ising models and dissect the folding pathway of CTPRs under mechanical load, revealing how the repeat arrays form from the centre towards both termini simultaneously. -

Small Glutamine-Rich Tetratricopeptide Repeat
www.nature.com/scientificreports OPEN Small Glutamine-Rich Tetratricopeptide Repeat- Containing Protein Alpha (SGTA) Received: 04 January 2016 Accepted: 07 June 2016 Ablation Limits Offspring Viability Published: 30 June 2016 and Growth in Mice Lisa K. Philp1, Tanya K. Day1, Miriam S. Butler1, Geraldine Laven-Law1, Shalini Jindal1, Theresa E. Hickey1, Howard I. Scher2, Lisa M. Butler1,3,* & Wayne D. Tilley1,3,* Small glutamine-rich tetratricopeptide repeat-containing protein α (SGTA) has been implicated as a co-chaperone and regulator of androgen and growth hormone receptor (AR, GHR) signalling. We investigated the functional consequences of partial and full Sgta ablation in vivo using Cre-lox Sgta- null mice. Sgta+/− breeders generated viable Sgta−/− offspring, but at less than Mendelian expectancy. Sgta−/− breeders were subfertile with small litters and higher neonatal death (P < 0.02). Body size was significantly and proportionately smaller in male and femaleSgta −/− (vs WT, Sgta+/− P < 0.001) from d19. Serum IGF-1 levels were genotype- and sex-dependent. Food intake, muscle and bone mass and adiposity were unchanged in Sgta−/−. Vital and sex organs had normal relative weight, morphology and histology, although certain androgen-sensitive measures such as penis and preputial size, and testis descent, were greater in Sgta−/−. Expression of AR and its targets remained largely unchanged, although AR localisation was genotype- and tissue-dependent. Generally expression of other TPR- containing proteins was unchanged. In conclusion, this thorough investigation of SGTA-null mutation reports a mild phenotype of reduced body size. The model’s full potential likely will be realised by genetic crosses with other models to interrogate the role of SGTA in the many diseases in which it has been implicated. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Eukaryotic Genome Annotation
Comparative Features of Multicellular Eukaryotic Genomes (2017) (First three statistics from www.ensembl.org; other from original papers) C. elegans A. thaliana D. melanogaster M. musculus H. sapiens Species name Nematode Thale Cress Fruit Fly Mouse Human Size (Mb) 103 136 143 3,482 3,555 # Protein-coding genes 20,362 27,655 13,918 22,598 20,338 (25,498 (13,601 original (30,000 (30,000 original est.) original est.) original est.) est.) Transcripts 58,941 55,157 34,749 131,195 200,310 Gene density (#/kb) 1/5 1/4.5 1/8.8 1/83 1/97 LINE/SINE (%) 0.4 0.5 0.7 27.4 33.6 LTR (%) 0.0 4.8 1.5 9.9 8.6 DNA Elements 5.3 5.1 0.7 0.9 3.1 Total repeats 6.5 10.5 3.1 38.6 46.4 Exons % genome size 27 28.8 24.0 per gene 4.0 5.4 4.1 8.4 8.7 average size (bp) 250 506 Introns % genome size 15.6 average size (bp) 168 Arabidopsis Chromosome Structures Sorghum Whole Genome Details Characterizing the Proteome The Protein World • Sequencing has defined o Many, many proteins • How can we use this data to: o Define genes in new genomes o Look for evolutionarily related genes o Follow evolution of genes ▪ Mixing of domains to create new proteins o Uncover important subsets of genes that ▪ That deep phylogenies • Plants vs. animals • Placental vs. non-placental animals • Monocots vs. dicots plants • Common nomenclature needed o Ensure consistency of interpretations InterPro (http://www.ebi.ac.uk/interpro/) Classification of Protein Families • Intergrated documentation resource for protein super families, families, domains and functional sites o Mitchell AL, Attwood TK, Babbitt PC, et al.