Proposal to Encode the TA Posal to Encode the TAKRI LETTER SSA In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Map by Steve Huffman; Data from World Language Mapping System
Svalbard Greenland Jan Mayen Norwegian Norwegian Icelandic Iceland Finland Norway Swedish Sweden Swedish Faroese FaroeseFaroese Faroese Faroese Norwegian Russia Swedish Swedish Swedish Estonia Scottish Gaelic Russian Scottish Gaelic Scottish Gaelic Latvia Latvian Scots Denmark Scottish Gaelic Danish Scottish Gaelic Scottish Gaelic Danish Danish Lithuania Lithuanian Standard German Swedish Irish Gaelic Northern Frisian English Danish Isle of Man Northern FrisianNorthern Frisian Irish Gaelic English United Kingdom Kashubian Irish Gaelic English Belarusan Irish Gaelic Belarus Welsh English Western FrisianGronings Ireland DrentsEastern Frisian Dutch Sallands Irish Gaelic VeluwsTwents Poland Polish Irish Gaelic Welsh Achterhoeks Irish Gaelic Zeeuws Dutch Upper Sorbian Russian Zeeuws Netherlands Vlaams Upper Sorbian Vlaams Dutch Germany Standard German Vlaams Limburgish Limburgish PicardBelgium Standard German Standard German WalloonFrench Standard German Picard Picard Polish FrenchLuxembourgeois Russian French Czech Republic Czech Ukrainian Polish French Luxembourgeois Polish Polish Luxembourgeois Polish Ukrainian French Rusyn Ukraine Swiss German Czech Slovakia Slovak Ukrainian Slovak Rusyn Breton Croatian Romanian Carpathian Romani Kazakhstan Balkan Romani Ukrainian Croatian Moldova Standard German Hungary Switzerland Standard German Romanian Austria Greek Swiss GermanWalser CroatianStandard German Mongolia RomanschWalser Standard German Bulgarian Russian France French Slovene Bulgarian Russian French LombardRomansch Ladin Slovene Standard -

Neo-Vernacularization of South Asian Languages
LLanguageanguage EEndangermentndangerment andand PPreservationreservation inin SSouthouth AAsiasia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 Language Endangerment and Preservation in South Asia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 PUBLISHED AS A SPECIAL PUBLICATION OF LANGUAGE DOCUMENTATION & CONSERVATION LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA Special Publication No. 7 (January 2014) ed. by Hugo C. Cardoso LANGUAGE DOCUMENTATION & CONSERVATION Department of Linguistics, UHM Moore Hall 569 1890 East-West Road Honolulu, Hawai’i 96822 USA http:/nflrc.hawaii.edu/ldc UNIVERSITY OF HAWAI’I PRESS 2840 Kolowalu Street Honolulu, Hawai’i 96822-1888 USA © All text and images are copyright to the authors, 2014 Licensed under Creative Commons Attribution Non-Commercial No Derivatives License ISBN 978-0-9856211-4-8 http://hdl.handle.net/10125/4607 Contents Contributors iii Foreword 1 Hugo C. Cardoso 1 Death by other means: Neo-vernacularization of South Asian 3 languages E. Annamalai 2 Majority language death 19 Liudmila V. Khokhlova 3 Ahom and Tangsa: Case studies of language maintenance and 46 loss in North East India Stephen Morey 4 Script as a potential demarcator and stabilizer of languages in 78 South Asia Carmen Brandt 5 The lifecycle of Sri Lanka Malay 100 Umberto Ansaldo & Lisa Lim LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA iii CONTRIBUTORS E. ANNAMALAI ([email protected]) is director emeritus of the Central Institute of Indian Languages, Mysore (India). He was chair of Terralingua, a non-profit organization to promote bi-cultural diversity and a panel member of the Endangered Languages Documentation Project, London. -

Braj Bhasha Mayank Jain1, Yogesh Dawer2, Nandini Chauhan2, Anjali Gupta2 1Jawaharlal Nehru University, 2Dr
Developing Resources for a Less-Resourced Language: Braj Bhasha Mayank Jain1, Yogesh Dawer2, Nandini Chauhan2, Anjali Gupta2 1Jawaharlal Nehru University, 2Dr. Bhim Rao Ambedkar University Delhi, Agra {jnu.mayank, yogeshdawer, nandinipinki850, anjalisoniyagupta89}@gmail.com Abstract This paper gives the overview of the language resources developed for a less-resourced western Indo-Aryan language of India - Braj Bhasha. There is no language resource available for Braj Bhasha. The paper gives the detail of first-ever language resources developed for Braj Bhasha which are text corpus, BIS based POS tagset and annotation, Universal Dependency (UD) based morphological and dependency annotation. UD is a framework for cross-linguistically consistent grammatical annotation and an open community effort with contributors working on over 60 languages. The methodology used to develop corpus, tagset, and annotation can help in creating resources for other less-resourced languages. These resources would provide the opportunity for Braj Bhasha to develop NLP applications and to do research on various areas of linguistics - cognitive linguistics, comparative linguistics, typological and theoretical linguistics. Keywords: Language Resources, Corpus, Tagset, Universal Dependency, Annotation, Braj Bhasha 1. Introduction Hindi texts written in Devanagari. Since the script of Braj Braj or Braj Bhasha1 is a Western Indo-Aryan language Bhasha is Devanagari, the OCR tool gave quite a spoken mainly in the adjoining region spread over Uttar satisfactory result for Braj data. The process of Pradesh and Rajasthan. In present times, when major digitization is a two-step procedure. First, the individual developments in the field of computational linguistics and pages of books and magazines were scanned using a high- natural language processing are playing an integral role in resolution scanner. -

Map by Steve Huffman Data from World Language Mapping System 16
Tajiki Tajiki Tajiki Shughni Southern Pashto Shughni Tajiki Wakhi Wakhi Wakhi Mandarin Chinese Sanglechi-Ishkashimi Sanglechi-Ishkashimi Wakhi Domaaki Sanglechi-Ishkashimi Khowar Khowar Khowar Kati Yidgha Eastern Farsi Munji Kalasha Kati KatiKati Phalura Kalami Indus Kohistani Shina Kati Prasuni Kamviri Dameli Kalami Languages of the Gawar-Bati To rw al i Chilisso Waigali Gawar-Bati Ushojo Kohistani Shina Balti Parachi Ashkun Tregami Gowro Northwest Pashayi Southwest Pashayi Grangali Bateri Ladakhi Northeast Pashayi Southeast Pashayi Shina Purik Shina Brokskat Aimaq Parya Northern Hindko Kashmiri Northern Pashto Purik Hazaragi Ladakhi Indian Subcontinent Changthang Ormuri Gujari Kashmiri Pahari-Potwari Gujari Bhadrawahi Zangskari Southern Hindko Kashmiri Ladakhi Pangwali Churahi Dogri Pattani Gahri Ormuri Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Southern Pashto Ladakhi Central Pashto Khams Tibetan Kullu Pahari KinnauriBhoti Kinnauri Sunam Majhi Western Panjabi Mandeali Jangshung Tukpa Bilaspuri Chitkuli Kinnauri Mahasu Pahari Eastern Panjabi Panang Jaunsari Western Balochi Southern Pashto Garhwali Khetrani Hazaragi Humla Rawat Central Tibetan Waneci Rawat Brahui Seraiki DarmiyaByangsi ChaudangsiDarmiya Western Balochi Kumaoni Chaudangsi Mugom Dehwari Bagri Nepali Dolpo Haryanvi Jumli Urdu Buksa Lowa Raute Eastern Balochi Tichurong Seke Sholaga Kaike Raji Rana Tharu Sonha Nar Phu ChantyalThakali Seraiki Raji Western Parbate Kham Manangba Tibetan Kathoriya Tharu Tibetan Eastern Parbate Kham Nubri Marwari Ts um Gamale Kham Eastern -

Prabháta Sam'giita
Prabháta Sam'giita Songs of the New Dawn A brief introduction Renaissance Artists & Writers Association A New Dawn • Prabhata Samgiita – music of a new dawn • 5018 songs • From Indian classical to folk music • Written and composed by: – Shri Prabhata Rainjana Sarkar • Between 1982 and 1990 Variety of Themes • Devotional • Mystical love • Seasons • Ecology • Social consciousness • Marching songs • Stages, feelings & experiences in spiritual meditation • Krs'n'a •Shiva Languages Used • Most songs are in Bengali • Over 40 songs are composed in other languages, including: –English –Sanskrit (language for literary & spiritual uses) –Hindi (vocabulary borrows from Sanskrit, non-Persian & non-Arabic) –Urdu (similar to elementary Hindi, vocabulary borrows from Persian & Arabic) –Angika (spoken in in Bihar, Jharkhand & West Bengal) –Maithili (spoken in North-East Bihar & Nepal) Northern-Central India Some Genres of Prabhata Samgiita • Kiirtan songs • Tappa songs • Thumri songs • Gazal songs • Kawali songs • Baul songs • Jhumur songs Kiirtan Songs • Kiirtan is a special type of devotional song style • Centres around singing about the Supreme Entity (God) • Developed towards the end of the 12th century through Jayadeva’s composition of the Gita Govinda (around 1178 AD) • These are Sanskrit love poems saturated with madhura bhava (high state of devotional sentiment and Divine Love) Kiirtan Songs • During the 15th century Dwija Chandidas (1390 -1450) advocated Krishna kiirtans • These are songs in praise of Lord Krishna as the incarnation of the Supreme -

Brief Notes on Mother Tongues , Punjab
CIENSlJJS Of DNDIA 1971 PUNJAB BRIEF NOTES ON MOTHER TONGUES (Based on 1961 Returns) By 315.455 R. C. NIGAM 1971 ~NT REGISTRAR GENERAL, INDIA IF THE REGISTRAR GENERAL, INDIA Mot Ton (LANGUAGE DIVISION) LIST OF MOTHER-TONGUES (1961) PUNJAB SI. Name of Mother Name in Local Comments, if any No. tongues with Script variant spellings in brackets 1 2 3 4 Adivasi ( Adibasi, Could be helpful if ~J(.ci Adiwasi) fic tribal/community name could be linked up with mother-tongue name. '2 AfghanijKabuli/ ~GorTol t~T~:81 jU'tl"3.' Pakhto/Pashto/ u;:;i'a!uo Tol Pathani 3 African Return is after the name of the continent. Spe cificmother-tongue names will have to be as certained. 4 Aia Alam Unclassified in 1961 Census. Will need further scrutiny. 5 Almori 6 Anal "POC3 7 Arabic/Arbi »{CI~l In 1961 Census some Urdu speakers also had returned Arabic/ Arbi as their mother- tongue. S Assamese ( Assami) WF[ll-il 9 Awadhi { Avadi) »{~l 10 Baghelkhandi ~ti18ci~1 (Bhugelkhud) 2 SI. Name of Mother Name in Local Comments, if any No. tongues with Script variant spellings in brackets 1 2 3 4 11 Bagri ( Bagari, Bagria, Bahgri ) 12 Bagri-Rajasthani ~TaJ~l-'aTtlRe: T'()l 13 Bahawalpuri ~T~'Sy''al 14 Baliai ( BaHam) e 81",,1 E1 15 Balochi/Baluchi ri~l 16 Bangaru ( Bangru, ~taJil. If returned again in Banger, Bangri) 1971, then location of speakers at the village level need be specified. 17 Baori (Bawria, ~l){a1 The name of at least Bawaria, Boari, one village of their Boria) concentration from the state will be required to be noted. -

Chapter One: Social, Cultural and Linguistic Landscape of India
Chapter one: Social, Cultural and Linguistic Landscape of India 1.1 Introduction: India also known as Bharat is the seventh largest country covering a land area of 32, 87,263 sq.km. It stretches 3,214 km. from North to South between the extreme latitudes and 2,933 km from East to West between the extreme longitudes. On this 2.4 % of earth‟s surface, lives 16% of world‟s population. With a population of 1,028,737,436 variations is there at every step of life. India is a land of bewildering diversity. India is bounded by the Indian Ocean on the Figure 1.1: India in World Population south, the Arabian Sea on the west and the Bay of Bengal on the east. Many outsiders explored India via these routes. The whole of India is divided into twenty eight states and seven union territories. Each state has its own cultural and linguistic peculiarities and diversities. This diversity can be seen in every aspect of Indian life. Whether it is culture, language, script, religion, food, clothing etc. makes ones identity multi-dimensional. Ones identity lies in his language, his culture, caste, state, village etc. So one can say India is a multi-centered nation. Indian multilingualism is unique in itself. It has been rightly said, “Each part of India is a kind of replica of the bigger cultural space called India.” (Singh U. N, 2009). Also multilingualism in India is not considered a barrier but a boon. 17 Chapter One: Social, Cultural and Linguistic Landscape of India Languages act as bridges because it enables us to know about others. -

Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo Iouo
Asia No. Language [ISO 639-3 Code] Country (Region) 1 A’ou [aou] Iouo China 2 Abai Sungai [abf] Iouo Malaysia 3 Abaza [abq] Iouo Russia, Turkey 4 Abinomn [bsa] Iouo Indonesia 5 Abkhaz [abk] Iouo Georgia, Turkey 6 Abui [abz] Iouo Indonesia 7 Abun [kgr] Iouo Indonesia 8 Aceh [ace] Iouo Indonesia 9 Achang [acn] Iouo China, Myanmar 10 Ache [yif] Iouo China 11 Adabe [adb] Iouo East Timor 12 Adang [adn] Iouo Indonesia 13 Adasen [tiu] Iouo Philippines 14 Adi [adi] Iouo India 15 Adi, Galo [adl] Iouo India 16 Adonara [adr] Iouo Indonesia Iraq, Israel, Jordan, Russia, Syria, 17 Adyghe [ady] Iouo Turkey 18 Aer [aeq] Iouo Pakistan 19 Agariya [agi] Iouo India 20 Aghu [ahh] Iouo Indonesia 21 Aghul [agx] Iouo Russia 22 Agta, Alabat Island [dul] Iouo Philippines 23 Agta, Casiguran Dumagat [dgc] Iouo Philippines 24 Agta, Central Cagayan [agt] Iouo Philippines 25 Agta, Dupaninan [duo] Iouo Philippines 26 Agta, Isarog [agk] Iouo Philippines 27 Agta, Mt. Iraya [atl] Iouo Philippines 28 Agta, Mt. Iriga [agz] Iouo Philippines 29 Agta, Pahanan [apf] Iouo Philippines 30 Agta, Umiray Dumaget [due] Iouo Philippines 31 Agutaynen [agn] Iouo Philippines 32 Aheu [thm] Iouo Laos, Thailand 33 Ahirani [ahr] Iouo India 34 Ahom [aho] Iouo India 35 Ai-Cham [aih] Iouo China 36 Aimaq [aiq] Iouo Afghanistan, Iran 37 Aimol [aim] Iouo India 38 Ainu [aib] Iouo China 39 Ainu [ain] Iouo Japan 40 Airoran [air] Iouo Indonesia 1 Asia No. Language [ISO 639-3 Code] Country (Region) 41 Aiton [aio] Iouo India 42 Akeu [aeu] Iouo China, Laos, Myanmar, Thailand China, Laos, Myanmar, Thailand, -

Rājasthānī Features in Medieval Braj Prose Texts the Case of Differential Object Marking and Verbal Agreement in Perfective Clauses
Annali di Ca’ Foscari. Serie orientale [online] ISSN 2385-3042 Vol. 53 – Giugno 2017 [print] ISSN 1125-3789 Rājasthānī Features in Medieval Braj Prose Texts The Case of Differential Object Marking and Verbal Agreement in Perfective Clauses Andrea Drocco (Università Ca’ Foscari Venezia, Italia) Abstract One of the few scholars who paid attention to the ‘dark’ period of the evolution of NIA from late MIA was Luigi Pio Tessitori. The studies of this scholar resulted in his well-known Grammar of the Old Western Rajasthani. In the introduction of his Grammar, Tessitori advanced the hypothesis that probably in this first period of NIA there was an intermediate form of speech that surely sepa- rated Old Western Rājasthānī from what he called an Old form of Western Hindī, but in which these two linguistic varieties of Western NIA merged together. Tessitori called Old Eastern Rājasthānī this old intermediate form of speech. As stated by himself, one of Tessitori’s future objectives would be to find some proof to demonstrate or to invalidate this hypothesis. However, due to his untimely death, he was not able to do this. Due to the fact that at the present there’s lack of specific studies on this topic, the present study intend to pursue Tessitori’s hypothesis using some medieval published texts in Braj-bhāṣā prose. Even if the language of this kind of texts could be classified as a form of Braj, we will see that these texts show a language different from classical Braj, where many examples of a typical characteristic of Māravāṛī (i.e. -

The Influence of English on the History of Hindi Relative Clauses
Journal of Language Contact 4 (2011) 250–268 brill.nl/jlc Th e Infl uence of English on the History of Hindi Relative Clauses Vandana Puri University of Illinois at Urbana-Champaign [email protected] Abstract Th e infl uence of Hindi on English has been well documented; however, little has been said about the infl uence of English on the structure of Hindi. In this paper I provide evidence that Hindi “embedded” (i.e. post-nominal) relative clauses result from English infl uence. Hindi originally had Relative-Correlative (RC-CC) constructions that could adjoin to the left or the right of the main clause. Since evidence from early Hindi is limited, I draw on Awadhi and Braj Bhakha to provide greater time depth for the earlier history of Hindi. In addition I examine early 19 th cen- tury grammars and texts. None of these provide unambiguous evidence for embedded relative clauses. By contrast, late 19 th century and early 20 th century Hindi texts translated from English exhibit many instances of central embedded relative clauses (besides the old adjoined relative- correlatives), thus supporting the argument that Hindi embedded relative clauses result from the infl uence of English. I argue that what may have helped in this developed is the occasional occur- rence of potentially ambiguous structures in earlier Hindi, which could be reinterpreted as involving embedding, rather than a relative-correlative construction with deleted correlative pronoun. Keywords Hindi ; English ; India ; language change ; syntax ; embedded relative clause 1. Introduction Th e infl uence of Hindi on English has been a topic of research for many years (Agnihotri 1991 , 1999 ; Agnihotri & Sahgal 1988 ; Bansal 1962 ; Bhatia 1978 ; Chaudhury 1985 ; Kachru, B. -
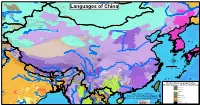
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Conceptions of Hindi
Hindi 1 Hindi Hindi (Devanāgarī: हिन्दी or हिंदी, IAST: Hindī, IPA: [ˈɦɪndiː] ( listen)) is the name given to various Indo-Aryan languages, dialects, and language registers spoken in northern and central India (the Hindi belt),[1] Pakistan, Fiji, Mauritius, and Suriname. Prototypically, Hindi is one of these varieties, called Hindustani or Hindi-Urdu, as spoken by Hindus. Standard Hindi, a standardized register of Hindustani, is one of the 22 scheduled languages of India, one of the official languages of the Indian Union Government and of many states in India. The traditional extent of Hindi in the broadest sense of the word. Conceptions of Hindi Hindi languages Geographic South Asia distribution: Genetic Indo-European classification: Indo-Iranian Indo-Aryan Hindi languages Subdivisions: Western Hindi Eastern Hindi Bihari Pahari Rajasthani The Hindi belt (left) and Eastern + Western Hindi (right) In the broadest sense of the word, "Hindi" refers to the Hindi languages, a culturally defined part of a dialect continuum that covers the "Hindi belt" of northern India. It includes Bhojpuri, an important language not only of India but, due to 19th and 20th century migrations, of Suriname, Guyana, Trinidad and Mauritius, where it is called Hindi or Hindustani; and Awadhi, a medieval literary standard in India and the Hindi of Fiji. Hindi 2 Rajasthani has been seen variously as a dialect of Hindi and as a separate language, though the lack of a dominant Rajasthani dialect as the basis for standardization has impeded its recognition as a language. Two other traditional varieties of Hindi, Chhattisgarhi and Dogri (a variety of Pahari), have recently been accorded status as official languages of their respective states, and so at times considered languages separate from Hindi.