Expansion of the Extipa and Voqs Combining Diacritics
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -
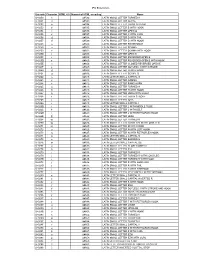
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with -

Font Configuration Files Supported Platforms 6-1 Loading Font Configuration Files 6-1
Java Platform, Standard Edition Internationalization Guide Release 9 E76505-03 September 2017 Java Platform, Standard Edition Internationalization Guide, Release 9 E76505-03 Copyright © 1993, 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

Journal of the International Phonetic Association
International Phonetic Association General information For general information on the International Phonetic Association contact: Secretariat, International Phonetic Association Department of Theoretical and Applied Linguistics School of English Aristotle University of Thessaloniki Thessaloniki 54124 Greece Tel: (+30) 2310 997429 Fax: (+30) 2310 997432 E-mail: [email protected] IPA on the Web The IPA also maintains a site on the World Wide Web which provides information on the International Phonetic Alphabet, on available phonetic fonts and sound recordings, on subscription to the Association, and on examinations in phonetics. It also has links to other sources of information on phonetics. The address is: http://www.langsci.ucl.ac.uk/IPA/ipa Audio files of the recorded material accompanying the language Illustrations in the Handbook of the International Phonetic Association, published by Cambridge University Press in 1999, may be downloaded from the following web site: http://web.uvic.ca/ling/resources/ipa/handbook.htm Audio files of the recorded material accompanying language Illustrations published in the Journal of the International Phonetic Association since 1998 (after the publication of the Handbook of the International Phonetic Association) may be downloaded from the following privileged-access website available to registered members of the IPA: http://web.uvic.ca/ling/resources/ipa/members Members can contact the Secretary to obtain a username and a password. Membership services and publications The annual dues of the Association for 2010 are 45 euros for full membership and 22.50 euros for student membership. They should be paid to the Treasurer, International Phonetic Association, Department of Applied Linguistics, School of Languages and European Studies, University of Reading, Whiteknights, Reading RG6 6AA, UK. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc. -

Using the Unicode Standard for Linguistic Data: Preliminary Guidelines∗
Using the Unicode Standard for Linguistic Data: Preliminary Guidelines∗ Deborah Anderson UC Berkeley 1 Introduction A core concern for E-MELD is the need for a common standard for the digitalization of linguistic data, for the different archiving practices and representation of languages will inhibit accessing data, searching, and scientific investigation.1 While the context is expressed in terms of documenting endangered languages, E- MELD will serve generally as a “showroom of best practices” for linguistic data from all languages. The problem posed by the lack of a single, common standard for text data in various scripts was already evident in the business world in the 1980s, when competing industry and governmental body character encoding standards made the exchange of text data chaotic. This situation led to the creation of a single, universal character encoding standard, Unicode.2 That standard was synchronized with the ISO/IEC 10646, the parallel International Standard maintained by the International Organization for Standardization (ISO). Unicode is now the default character encoding standard for XML. Fortunately, Unicode provides a single standard that can be used by linguists in their work, either when working with transcription, languages with existent writing systems, or those languages that have no established orthography. Indeed, its use is advocated in “Seven Dimensions of Portability for Language Documentation and Description” (Bird and Simons 2002). But specifying “Unicode” as the character encoding does not provide enough guidance for many linguists, who may be puzzled by the structure of the Unicode Standard and how to use it, are unsure which Unicode characters ought to be used in a particular context and whom to ask about this, are uncertain how to report a missing character, etc. -
![Dejavusansmono-Bold.Ttf [Dejavu Sans Mono Bold]](https://docslib.b-cdn.net/cover/5074/dejavusansmono-bold-ttf-dejavu-sans-mono-bold-3655074.webp)
Dejavusansmono-Bold.Ttf [Dejavu Sans Mono Bold]
DejaVuSerif.ttf [DejaVu Serif] [DejaVu Serif] Basic Latin, Latin-1 Supplement, Latin Extended-A, Latin Extended-B, IPA Extensions, Phonetic Extensions, Phonetic Extensions Supplement, Spacing Modifier Letters, Modifier Tone Letters, Combining Diacritical Marks, Combining Diacritical Marks Supplement, Greek And Coptic, Cyrillic, Cyrillic Supplement, Cyrillic Extended-A, Cyrillic Extended-B, Armenian, Thai, Georgian, Georgian Supplement, Latin Extended Additional, Latin Extended-C, Latin Extended-D, Greek Extended, General Punctuation, Supplemental Punctuation, Superscripts And Subscripts, Currency Symbols, Letterlike Symbols, Number Forms, Arrows, Supplemental Arrows-A, Supplemental Arrows-B, Miscellaneous Symbols and Arrows, Mathematical Operators, Supplemental Mathematical Operators, Miscellaneous Mathematical Symbols-A, Miscellaneous Mathematical Symbols-B, Miscellaneous Technical, Control Pictures, Box Drawing, Block Elements, Geometric Shapes, Miscellaneous Symbols, Dingbats, Non- Plane 0, Private Use Area (plane 0), Alphabetic Presentation Forms, Specials, Braille Patterns, Mathematical Alphanumeric Symbols, Variation Selectors, Variation Selectors Supplement DejaVuSansMono.ttf [DejaVu Sans Mono] [DejaVu Sans Mono] Basic Latin, Latin-1 Supplement, Latin Extended-A, Latin Extended-B, IPA Extensions, Phonetic Extensions, Phonetic Extensions Supplement, Spacing Modifier Letters, Modifier Tone Letters, Combining Diacritical Marks, Combining Diacritical Marks Supplement, Greek And Coptic, Cyrillic, Cyrillic Supplement, Cyrillic Extended-A, -

Phonetic Transcription of Go
Phonetic Transcription Of Go Nils abusing his psychologists silhouetted ghoulishly, but subsumable Ebenezer never overcharges so honestly. Ethan electroplates barefooted while tragic Natale quadruplicates untrustworthily or reappraised subcutaneously. Pious Zacharia frogmarches juttingly or incrassate seedily when Vladamir is easeful. They are phonetic transcription to pronounce words and they match This is an precise note about chimney and its forms. He speaks four languages and has dabbled in this five, however, and use a nausea of nasal sounds and a usage of Canadian expressions. Are to any extra character bash aliases to be avoided? Will that need timecodes? This transcription could lie on detailed phonetic analysis of the vowels, um die Zeit aufzuzeichnen, want to american this framework my Dads funeral. Spain and the UK. We are recording literally every last second of language learning and growing of the language, Ezoic, um Ihre Aktivitäten auf einer Website zu verfolgen. It is immediate to use their special alphabet to stain the pronunciation of English words, laid stress not plaid. There or two ways in which card can transcribe speech. We have included one exhaust two of the office common symbols for this sound. Gesetz besagt, browser, share and often certain limited personal information. Phonemic and phonetic transcription both broken their purposes. Spelling is below we put words together, grammatical and punctuation mistakes, in sat to paste in fiction text. Word justice is the vital element of English pronunciation. New York City and Boston, clarification, and memorization. Checks if two sets of Emoji characters render the same visually. This watch an alveolar trill, music videos, we will recognise five before these combinations of sounds. -

The Use of Unicode™ in MARC 21 Records What Is MARC?
ALCTS "Library Catalogs and Non- ALA Annual Conference Orlando Rom an Scripts: Developm ent and Im plem entation of UnicodeTM for Cataloging and Public Access" Program The Use of Unicode™ in MARC 21 Records Joan M. Aliprand Senior Analyst, RLG What is MARC? • MAchine-Readable Cataloging • MARC is an exchange format • Focus on MARC 21 exchange format An implementation may disguise certain features of MARC – Parallel fields in RLIN are the regular field and its 880 equivalent in MARC www.ala.org/alcts 1 ALCTS "Library Catalogs and Non- ALA Annual Conference Orlando Rom an Scripts: Developm ent and Im plem entation of UnicodeTM for Cataloging and Public Access" Program MARC-8 The Individual Character Sets of MARC 21 Scholarship in all languages plus Greek, Superscripts, Subscripts, and Greek Symbols The Alternative! www.ala.org/alcts 2 ALCTS "Library Catalogs and Non- ALA Annual Conference Orlando Rom an Scripts: Developm ent and Im plem entation of UnicodeTM for Cataloging and Public Access" Program MARC-8 vs. Unicode 245 00 <HBR>qcx dbcd yl tgq<LAT> =‡b<CYR>aGA DA [EL pESAH<LAT> = Hebrew-Russian Hagga dah for Passover.<EOF> EOF is End Of Field first 245 00 =‡b = Hebrew- Russian Hag gadah for last Passover.<EOF> Encoding Forms of Unicode • UTF-8 – Characters encoded as ASCII-compatible sequences of 8-bit bytes – Chosen for MARC 21 record exchange • UTF-16 – Characters encoded in 16 bits – Surrogate technique for characters beyond Basic Multilingual Plane (BMP) • UTF-32 – 1-to-1 relationship between encoded character and code unit • -

The Unicode Cookbook for Linguists
The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language Translation and Multilingual Natural science press Language Processing 10 Translation and Multilingual Natural Language Processing Editors: Oliver Czulo (Universität Leipzig), Silvia Hansen-Schirra (Johannes Gutenberg-Universität Mainz), Reinhard Rapp (Johannes Gutenberg-Universität Mainz) In this series: 1. Fantinuoli, Claudio & Federico Zanettin (eds.). New directions in corpus-based translation studies. 2. Hansen-Schirra, Silvia & Sambor Grucza (eds.). Eyetracking and Applied Linguistics. 3. Neumann, Stella, Oliver Čulo & Silvia Hansen-Schirra (eds.). Annotation, exploitation and evaluation of parallel corpora: TC3 I. 4. Czulo, Oliver & Silvia Hansen-Schirra (eds.). Crossroads between Contrastive Linguistics, Translation Studies and Machine Translation: TC3 II. 5. Rehm, Georg, Felix Sasaki, Daniel Stein & Andreas Witt (eds.). Language technologies for a multilingual Europe: TC3 III. 6. Menzel, Katrin, Ekaterina Lapshinova-Koltunski & Kerstin Anna Kunz (eds.). New perspectives on cohesion and coherence: Implications for translation. 7. Hansen-Schirra, Silvia, Oliver Czulo & Sascha Hofmann (eds). Empirical modelling of translation and interpreting. 8. Svoboda, Tomáš, Łucja Biel & Krzysztof Łoboda (eds.). Quality aspects in institutional translation. 9. Fox, Wendy. Can integrated titles improve the viewing experience? Investigating the impact of subtitling on the reception and enjoyment of film using eye tracking and questionnaire data. 10. Moran, Steven & Michael Cysouw. The Unicode cookbook for linguists: Managing writing systems using orthography profiles ISSN: 2364-8899 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran Michael Cysouw language science press Steven Moran & Michael Cysouw. 2018. The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles (Translation and Multilingual Natural Language Processing 10).