Spring 2021 Large Scale Multimedia Processing
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Transport and Map Symbols Range: 1F680–1F6FF
Transport and Map Symbols Range: 1F680–1F6FF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

The Unicode Standard 5.2 Code Charts
Miscellaneous Technical Range: 2300–23FF The Unicode Standard, Version 5.2 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 5.2. Characters in this chart that are new for The Unicode Standard, Version 5.2 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-5.2/ for charts showing only the characters added in Unicode 5.2. See http://www.unicode.org/Public/5.2.0/charts/ for a complete archived file of character code charts for Unicode 5.2. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 5.2 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 5.2, online at http://www.unicode.org/versions/Unicode5.2.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -

Geometry and Art LACMA | | April 5, 2011 Evenings for Educators
Geometry and Art LACMA | Evenings for Educators | April 5, 2011 ALEXANDER CALDER (United States, 1898–1976) Hello Girls, 1964 Painted metal, mobile, overall: 275 x 288 in., Art Museum Council Fund (M.65.10) © Alexander Calder Estate/Artists Rights Society (ARS), New York/ADAGP, Paris EOMETRY IS EVERYWHERE. WE CAN TRAIN OURSELVES TO FIND THE GEOMETRY in everyday objects and in works of art. Look carefully at the image above and identify the different, lines, shapes, and forms of both GAlexander Calder’s sculpture and the architecture of LACMA’s built environ- ment. What is the proportion of the artwork to the buildings? What types of balance do you see? Following are images of artworks from LACMA’s collection. As you explore these works, look for the lines, seek the shapes, find the patterns, and exercise your problem-solving skills. Use or adapt the discussion questions to your students’ learning styles and abilities. 1 Language of the Visual Arts and Geometry __________________________________________________________________________________________________ LINE, SHAPE, FORM, PATTERN, SYMMETRY, SCALE, AND PROPORTION ARE THE BUILDING blocks of both art and math. Geometry offers the most obvious connection between the two disciplines. Both art and math involve drawing and the use of shapes and forms, as well as an understanding of spatial concepts, two and three dimensions, measurement, estimation, and pattern. Many of these concepts are evident in an artwork’s composition, how the artist uses the elements of art and applies the principles of design. Problem-solving skills such as visualization and spatial reasoning are also important for artists and professionals in math, science, and technology. -

L2/14-274 Title: Proposed Math-Class Assignments for UTR #25
L2/14-274 Title: Proposed Math-Class Assignments for UTR #25 Revision 14 Source: Laurențiu Iancu and Murray Sargent III – Microsoft Corporation Status: Individual contribution Action: For consideration by the Unicode Technical Committee Date: 2014-10-24 1. Introduction Revision 13 of UTR #25 [UTR25], published in April 2012, corresponds to Unicode Version 6.1 [TUS61]. As of October 2014, Revision 14 is in preparation, to update UTR #25 and its data files to the character repertoire of Unicode Version 7.0 [TUS70]. This document compiles a list of characters proposed to be assigned mathematical classes in Revision 14 of UTR #25. In this document, the term math-class is being used to refer to the character classification in UTR #25. While functionally similar to a UCD character property, math-class is applicable only within the scope of UTR #25. Math-class is different from the UCD binary character property Math [UAX44]. The relation between Math and math-class is that the set of characters with the property Math=Yes is a proper subset of the set of characters assigned any math-class value in UTR #25. As of Revision 13, the set relation between Math and math-class is invalidated by the collection of Arabic mathematical alphabetic symbols in the range U+1EE00 – U+1EEFF. This is a known issue [14-052], al- ready discussed by the UTC [138-C12 in 14-026]. Once those symbols are added to the UTR #25 data files, the set relation will be restored. This document proposes only UTR #25 math-class values, and not any UCD Math property values. -

TS 126 234 V5.6.0 (2003-09) Technical Specification
ETSI TS 126 234 V5.6.0 (2003-09) Technical Specification Universal Mobile Telecommunications System (UMTS); Transparent end-to-end streaming service; Protocols and codecs (3GPP TS 26.234 version 5.6.0 Release 5) 3GPP TS 26.234 version 5.6.0 Release 5 1 ETSI TS 126 234 V5.6.0 (2003-09) Reference RTS/TSGS-0426234v560 Keywords UMTS ETSI 650 Route des Lucioles F-06921 Sophia Antipolis Cedex - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 Important notice Individual copies of the present document can be downloaded from: http://www.etsi.org The present document may be made available in more than one electronic version or in print. In any case of existing or perceived difference in contents between such versions, the reference version is the Portable Document Format (PDF). In case of dispute, the reference shall be the printing on ETSI printers of the PDF version kept on a specific network drive within ETSI Secretariat. Users of the present document should be aware that the document may be subject to revision or change of status. Information on the current status of this and other ETSI documents is available at http://portal.etsi.org/tb/status/status.asp If you find errors in the present document, send your comment to: [email protected] Copyright Notification No part may be reproduced except as authorized by written permission. -

Campusroman Pro Presentation
MacCampus® Fonts CampusRoman Pro our Unicode Reference font UNi UC .otf code 7.0 .ttf € $ MacCampus® Fonts CampusRoman Pro • Supports everything Latin, Cyrillic, Greek, and Coptic, Lisu; • phonetics, combining diacritics, spacing modifiers, punctuation, editorial marks, tone letters, counting rod numerals; mathematical alphanumerics; • transliterated Armenian, Georgian, Glagolitic, Gothic, and Old Persian Cuneiform; • superscripts & subscripts, currency signs, letterlike symbols, number forms, enclosed alphanumerics, dingbats... contains ca. 5.000 characters, incl. 133 (!) completely new additions from Unicode v. 7.0 (July 2014), esp. for German dialectology UC 7.0 MacCampus® Fonts CampusRoman Pro UC NEW: LatinExtended-E: Letters for 7.0 German dialectology and Americanist orthographies MacCampus® Fonts CampusRoman Pro UC NEW: LatinExtended-D: Lithuanian 7.0 dialectology, middle Vietnamese,Ewe, Volapük, Celtic epigraphy, Americanist orthographies, etc. MacCampus® Fonts CampusRoman Pro UC NEW: Cyrillic Supplement: Orok, 7.0 Komi, Khanty letters MacCampus® Fonts CampusRoman Pro UC NEW: CyrillicExtended-B: Letters 7.0 for Old Cyrillic and Lithuanian dialectology MacCampus® Fonts CampusRoman Pro UC NEW: Supplemental Punctuation: 7.0 alternate, historic and reversed punctuation; double hyphen MacCampus® Fonts CampusRoman Pro UC NEW: Currency: Nordic Mark, 7.0 Manat, Ruble MacCampus® Fonts CampusRoman Pro UC NEW: Combining Diacritics Extended 7.0 + Combining Halfmarks: German dialectology; comb. halfmarks below MacCampus® Fonts CampusRoman Pro UC NEW: Combining Diacritics Supplement: 7.0 Superscript letters for German dialectology MacCampus® Fonts CampusRoman Pro • available now • single and multi-user licenses • embeddable • OpenType and TrueType • professionally designed • from a linguist for linguists • for scholars-philologists UC 7.0 • one weight (upright) only • Unicode 7.0 compliant MacCampus® Fonts A Lang. Font З ABC List www.maccampus.de www.maccampus.de/fonts/CampusRoman-Pro.htm © Sebastian Kempgen 2014. -
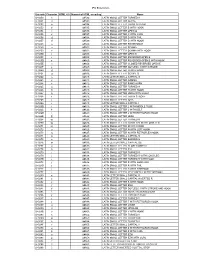
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with -

Kindergarten Specials Activities
Kindergarten Specials Activities Art Music P.E. S.T.E.M Activity 1: Find primary Activity 1: Teach someone a Activity 1: Same Spot, Sock Shot Science: Take a nature walk and collect song you have learned in Using clean pair of balled up socks some natural materials. When you get colors (red, yellow, blue) in practice tossing under hand and then home sort the materials you your house. music class. If the song had a overhand while stepping with the found. Below are some examples of how game, teach the game as well. opposite foot to a target. Please ask you might sort. If you have time after adult permission to use certain sorting try building something cool with the natural materials. targets at your home. Examples: K-1st: sort by shape, color, or size laundry hamper, spot on wall/tile on 2nd-3rd: sort by texture, shape AND floor, or family members make a size, or living vs non-living hoop with their arms. 4th-6th: Have students create their own way of sorting and then challenge someone elseto identify their method. Activity 2: I SPY: Find Activity 2: Create your own Activity 2: Cardio Day Technology: Have someone in your instrument. You can draw it 5 Minute Morning Dance house pretend to be a robot. You secondary colors outside should program the robot how to (green, orange, purple) out and explain what it would Party move around the house. Remember be made out of, how it would Evening Running Competition; robots cannot make any decisions for work, and how it would How many laps can each themselves, they only can do what sound. -

The Case of Basic Geometric Shapes
International Journal of Progressive Education, Volume 15 Number 3, 2019 © 2019 INASED Children’s Geometric Understanding through Digital Activities: The Case of Basic Geometric Shapes Bilal Özçakır i Kırşehir Ahi Evran University Ahmet Sami Konca ii Kırşehir Ahi Evran University Nihat Arıkan iii Kırşehir Ahi Evran University Abstract Early mathematics education bases a foundation of academic success in mathematics for higher grades. Studies show that introducing mathematical contents in preschool level is a strong predictor of success in mathematics for children during their progress in other school levels. Digital technologies can support children’s learning mathematical concepts by means of the exploration and the manipulation of concrete representations. Therefore, digital activities provide opportunities for children to engage with experimental mathematics. In this study, the effects of digital learning tools on learning about geometric shapes in early childhood education were investigated. Hence, this study aimed to investigate children progresses on digital learning activities in terms of recognition and discrimination of basic geometric shapes. Participants of the study were six children from a kindergarten in Kırşehir, Turkey. Six digital learning activities were engaged by children with tablets about four weeks in learning settings. Task-based interview sessions were handled in this study. Results of this study show that these series of activities helped children to achieve higher cognitive levels. They improved their understanding through digital activities. Keywords: Digital Learning Activities, Early Childhood Education, Basic Geometric Shape, Geometry Education DOI: 10.29329/ijpe.2019.193.8 ------------------------------- i Bilal Özçakır, Res. Assist Dr., Kırşehir Ahi Evran University, Mathematics Education. Correspondence: [email protected] ii Ahmet Sami Konca, Res.