Font Configuration Files Supported Platforms 6-1 Loading Font Configuration Files 6-1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Yiddish Diction in Singing
UNLV Theses, Dissertations, Professional Papers, and Capstones May 2016 Yiddish Diction in Singing Carrie Suzanne Schuster-Wachsberger University of Nevada, Las Vegas Follow this and additional works at: https://digitalscholarship.unlv.edu/thesesdissertations Part of the Language Description and Documentation Commons, Music Commons, Other Languages, Societies, and Cultures Commons, and the Theatre and Performance Studies Commons Repository Citation Schuster-Wachsberger, Carrie Suzanne, "Yiddish Diction in Singing" (2016). UNLV Theses, Dissertations, Professional Papers, and Capstones. 2733. http://dx.doi.org/10.34917/9112178 This Dissertation is protected by copyright and/or related rights. It has been brought to you by Digital Scholarship@UNLV with permission from the rights-holder(s). You are free to use this Dissertation in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you need to obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/or on the work itself. This Dissertation has been accepted for inclusion in UNLV Theses, Dissertations, Professional Papers, and Capstones by an authorized administrator of Digital Scholarship@UNLV. For more information, please contact [email protected]. YIDDISH DICTION IN SINGING By Carrie Schuster-Wachsberger Bachelor of Music in Vocal Performance Syracuse University 2010 Master of Music in Vocal Performance Western Michigan University 2012 -
The Ogham-Runes and El-Mushajjar
c L ite atu e Vo l x a t n t r n o . o R So . u P R e i t ed m he T a s . 1 1 87 " p r f ro y f r r , , r , THE OGHAM - RUNES AND EL - MUSHAJJAR A D STU Y . BY RICH A R D B URTO N F . , e ad J an uar 22 (R y , PART I . The O ham-Run es g . e n u IN tr ating this first portio of my s bj ect, the - I of i Ogham Runes , have made free use the mater als r John collected by Dr . Cha les Graves , Prof. Rhys , and other students, ending it with my own work in the Orkney Islands . i The Ogham character, the fair wr ting of ' Babel - loth ancient Irish literature , is called the , ’ Bethluis Bethlm snion e or , from its initial lett rs, like “ ” Gree co- oe Al hab e t a an d the Ph nician p , the Arabo “ ” Ab ad fl d H ebrew j . It may brie y be describe as f b ormed y straight or curved strokes , of various lengths , disposed either perpendicularly or obliquely to an angle of the substa nce upon which the letters n . were i cised , punched, or rubbed In monuments supposed to be more modern , the letters were traced , b T - N E E - A HE OGHAM RU S AND L M USH JJ A R . n not on the edge , but upon the face of the recipie t f n l o t sur ace ; the latter was origi al y wo d , s aves and tablets ; then stone, rude or worked ; and , lastly, metal , Th . -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

The Gentics of Civilization: an Empirical Classification of Civilizations Based on Writing Systems
Comparative Civilizations Review Volume 49 Number 49 Fall 2003 Article 3 10-1-2003 The Gentics of Civilization: An Empirical Classification of Civilizations Based on Writing Systems Bosworth, Andrew Bosworth Universidad Jose Vasconcelos, Oaxaca, Mexico Follow this and additional works at: https://scholarsarchive.byu.edu/ccr Recommended Citation Bosworth, Bosworth, Andrew (2003) "The Gentics of Civilization: An Empirical Classification of Civilizations Based on Writing Systems," Comparative Civilizations Review: Vol. 49 : No. 49 , Article 3. Available at: https://scholarsarchive.byu.edu/ccr/vol49/iss49/3 This Article is brought to you for free and open access by the Journals at BYU ScholarsArchive. It has been accepted for inclusion in Comparative Civilizations Review by an authorized editor of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Bosworth: The Gentics of Civilization: An Empirical Classification of Civil 9 THE GENETICS OF CIVILIZATION: AN EMPIRICAL CLASSIFICATION OF CIVILIZATIONS BASED ON WRITING SYSTEMS ANDREW BOSWORTH UNIVERSIDAD JOSE VASCONCELOS OAXACA, MEXICO Part I: Cultural DNA Introduction Writing is the DNA of civilization. Writing permits for the organi- zation of large populations, professional armies, and the passing of complex information across generations. Just as DNA transmits biolog- ical memory, so does writing transmit cultural memory. DNA and writ- ing project information into the future and contain, in their physical structure, imprinted knowledge. -
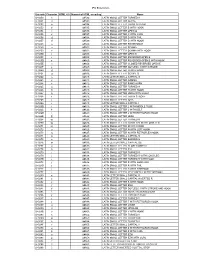
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with -

A STUDY of WRITING Oi.Uchicago.Edu Oi.Uchicago.Edu /MAAM^MA
oi.uchicago.edu A STUDY OF WRITING oi.uchicago.edu oi.uchicago.edu /MAAM^MA. A STUDY OF "*?• ,fii WRITING REVISED EDITION I. J. GELB Phoenix Books THE UNIVERSITY OF CHICAGO PRESS oi.uchicago.edu This book is also available in a clothbound edition from THE UNIVERSITY OF CHICAGO PRESS TO THE MOKSTADS THE UNIVERSITY OF CHICAGO PRESS, CHICAGO & LONDON The University of Toronto Press, Toronto 5, Canada Copyright 1952 in the International Copyright Union. All rights reserved. Published 1952. Second Edition 1963. First Phoenix Impression 1963. Printed in the United States of America oi.uchicago.edu PREFACE HE book contains twelve chapters, but it can be broken up structurally into five parts. First, the place of writing among the various systems of human inter communication is discussed. This is followed by four Tchapters devoted to the descriptive and comparative treatment of the various types of writing in the world. The sixth chapter deals with the evolution of writing from the earliest stages of picture writing to a full alphabet. The next four chapters deal with general problems, such as the future of writing and the relationship of writing to speech, art, and religion. Of the two final chapters, one contains the first attempt to establish a full terminology of writing, the other an extensive bibliography. The aim of this study is to lay a foundation for a new science of writing which might be called grammatology. While the general histories of writing treat individual writings mainly from a descriptive-historical point of view, the new science attempts to establish general principles governing the use and evolution of writing on a comparative-typological basis. -

Section 9.2, Arabic, Section 9.3, Syriac and Section 9.5, Man- Daic
The Unicode® Standard Version 12.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2019 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 12.0. Includes index. ISBN 978-1-936213-22-1 (http://www.unicode.org/versions/Unicode12.0.0/) 1. -

The Unicode Standard, Version 6.2 Copyright © 1991–2012 Unicode, Inc
The Unicode Standard Version 6.2 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Copyright © 1991–2012 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium ; edited by Julie D. Allen ... [et al.]. — Version 6.2. -

C=<16/+4/116/64 CHARACTER GENERATOR and UNICODE
C=<16/+4/116/64 CHARACTER GENERATOR AND UNICODE by Vladimir Lidovski The character generator of the C16/116/+4 consists of 256 symbols, but only 153 are unique — 90 symbols are duplicated, two are triplicated and three even quadruplicated. 124 characters of the 153 are mapped to Unicode, the remaining 29 however are UNMAPPED! This may produce impossibility of using our well known Commodore symbols with modern and FUTURE computer systems. This problem has naturally appeared in the situation of conversion of Commodore texts to the other systems — some symbols become LOST. Without unicodes they will be lost FOREVER... So we need to register them at the Unicode Consortium (www.unicode.org). The Unicode structure is not perfect. It’s missed some obvious characters. They were sacrificed to this structure. For example, the chapter “Form and charts components” contains places only for 128 symbols — all these places are occupied, the chapter “Block elements” has 32 places and all are occupied, etc. Eleven (73–75, 77, 78, 85, 86, 103, 118, 119, 120) of the 29 unregistered characters can simply get Unicode names. They are probably the victims of the mentioned structure. Their obvious names (prefixed by question mark) are presented in the next big chart. Two characters (223, 233) have pictures very similar to some presented in Unicode. Their registration may not be necessary. The remaining 16 (68–72, 76, 79, 80, 82, 84, 89, 92, 102, 104, 122, 222) require NAMES acceptable to ALL. 23 of the unmapped characters (68–80, 82, 84–86, 89, 103, 118–120, 122) can be placed in the extension to the above mentioned chapter “Form and charts components”. -

Journal of the International Phonetic Association
International Phonetic Association General information For general information on the International Phonetic Association contact: Secretariat, International Phonetic Association Department of Theoretical and Applied Linguistics School of English Aristotle University of Thessaloniki Thessaloniki 54124 Greece Tel: (+30) 2310 997429 Fax: (+30) 2310 997432 E-mail: [email protected] IPA on the Web The IPA also maintains a site on the World Wide Web which provides information on the International Phonetic Alphabet, on available phonetic fonts and sound recordings, on subscription to the Association, and on examinations in phonetics. It also has links to other sources of information on phonetics. The address is: http://www.langsci.ucl.ac.uk/IPA/ipa Audio files of the recorded material accompanying the language Illustrations in the Handbook of the International Phonetic Association, published by Cambridge University Press in 1999, may be downloaded from the following web site: http://web.uvic.ca/ling/resources/ipa/handbook.htm Audio files of the recorded material accompanying language Illustrations published in the Journal of the International Phonetic Association since 1998 (after the publication of the Handbook of the International Phonetic Association) may be downloaded from the following privileged-access website available to registered members of the IPA: http://web.uvic.ca/ling/resources/ipa/members Members can contact the Secretary to obtain a username and a password. Membership services and publications The annual dues of the Association for 2010 are 45 euros for full membership and 22.50 euros for student membership. They should be paid to the Treasurer, International Phonetic Association, Department of Applied Linguistics, School of Languages and European Studies, University of Reading, Whiteknights, Reading RG6 6AA, UK.