Character Properties 4
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

International Standard Iso/Iec 10646
This is a preview - click here to buy the full publication INTERNATIONAL ISO/IEC STANDARD 10646 Sixth edition 2020-12 Information technology — Universal coded character set (UCS) Technologies de l'information — Jeu universel de caractères codés (JUC) Reference number ISO/IEC 10646:2020(E) © ISO/IEC 2020 This is a preview - click here to buy the full publication ISO/IEC 10646:2020 (E) CONTENTS 1 Scope ..................................................................................................................................................1 2 Normative references .........................................................................................................................1 3 Terms and definitions .........................................................................................................................2 4 Conformance ......................................................................................................................................8 4.1 General ....................................................................................................................................8 4.2 Conformance of information interchange .................................................................................8 4.3 Conformance of devices............................................................................................................8 5 Electronic data attachments ...............................................................................................................9 6 General structure -

Package Mathfont V. 1.6 User Guide Conrad Kosowsky December 2019 [email protected]
Package mathfont v. 1.6 User Guide Conrad Kosowsky December 2019 [email protected] For easy, off-the-shelf use, type the following in your docu- ment preamble and compile using X LE ATEX or LuaLATEX: \usepackage[hfont namei]{mathfont} Abstract The mathfont package provides a flexible interface for changing the font of math- mode characters. The package allows the user to specify a default unicode font for each of six basic classes of Latin and Greek characters, and it provides additional support for unicode math and alphanumeric symbols, including punctuation. Crucially, mathfont is compatible with both X LE ATEX and LuaLATEX, and it provides several font-loading commands that allow the user to change fonts locally or for individual characters within math mode. Handling fonts in TEX and LATEX is a notoriously difficult task. Donald Knuth origi- nally designed TEX to support fonts created with Metafont, and while subsequent versions of TEX extended this functionality to postscript fonts, Plain TEX's font-loading capabilities remain limited. Many, if not most, LATEX users are unfamiliar with the fd files that must be used in font declaration, and the minutiae of TEX's \font primitive can be esoteric and confusing. LATEX 2"'s New Font Selection System (nfss) implemented a straightforward syn- tax for loading and managing fonts, but LATEX macros overlaying a TEX core face the same versatility issues as Plain TEX itself. Fonts in math mode present a double challenge: after loading a font either in Plain TEX or through the nfss, defining math symbols can be unin- tuitive for users who are unfamiliar with TEX's \mathcode primitive. -

A Decision Procedure for String to Code Point Conversion‹
A Decision Procedure for String to Code Point Conversion‹ Andrew Reynolds1, Andres Notzli¨ 2, Clark Barrett2, and Cesare Tinelli1 1 Department of Computer Science, The University of Iowa, Iowa City, USA 2 Department of Computer Science, Stanford University, Stanford, USA Abstract. In text encoding standards such as Unicode, text strings are sequences of code points, each of which can be represented as a natural number. We present a decision procedure for a concatenation-free theory of strings that includes length and a conversion function from strings to integer code points. Furthermore, we show how many common string operations, such as conversions between lowercase and uppercase, can be naturally encoded using this conversion function. We describe our implementation of this approach in the SMT solver CVC4, which contains a high-performance string subsolver, and show that the use of a native procedure for code points significantly improves its performance with respect to other state-of-the-art string solvers. 1 Introduction String processing is an important part of many kinds of software. In particular, strings often serve as a common representation for the exchange of data at interfaces between different programs, between different programming languages, and between programs and users. At such interfaces, strings often represent values of types other than strings, and developers have to be careful to sanitize and parse those strings correctly. This is a challenging task, making the ability to automatically reason about such software and interfaces appealing. Applications of automated reasoning about strings include finding or proving the absence of SQL injections and XSS vulnerabilities in web applications [28, 25, 31], reasoning about access policies in cloud infrastructure [7], and generating database tables from SQL queries for unit testing [29]. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Arabic Alphabet - Wikipedia, the Free Encyclopedia Arabic Alphabet from Wikipedia, the Free Encyclopedia
2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia Arabic alphabet From Wikipedia, the free encyclopedia َأﺑْ َﺠ ِﺪﯾﱠﺔ َﻋ َﺮﺑِﯿﱠﺔ :The Arabic alphabet (Arabic ’abjadiyyah ‘arabiyyah) or Arabic abjad is Arabic abjad the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[1] stand for consonants, it is classified as an abjad. Type Abjad Languages Arabic Time 400 to the present period Parent Proto-Sinaitic systems Phoenician Aramaic Syriac Nabataean Arabic abjad Child N'Ko alphabet systems ISO 15924 Arab, 160 Direction Right-to-left Unicode Arabic alias Unicode U+0600 to U+06FF range (http://www.unicode.org/charts/PDF/U0600.pdf) U+0750 to U+077F (http://www.unicode.org/charts/PDF/U0750.pdf) U+08A0 to U+08FF (http://www.unicode.org/charts/PDF/U08A0.pdf) U+FB50 to U+FDFF (http://www.unicode.org/charts/PDF/UFB50.pdf) U+FE70 to U+FEFF (http://www.unicode.org/charts/PDF/UFE70.pdf) U+1EE00 to U+1EEFF (http://www.unicode.org/charts/PDF/U1EE00.pdf) Note: This page may contain IPA phonetic symbols. Arabic alphabet ا ب ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع en.wikipedia.org/wiki/Arabic_alphabet 1/20 2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia غ ف ق ك ل م ن ه و ي History · Transliteration ء Diacritics · Hamza Numerals · Numeration V · T · E (//en.wikipedia.org/w/index.php?title=Template:Arabic_alphabet&action=edit) Contents 1 Consonants 1.1 Alphabetical order 1.2 Letter forms 1.2.1 Table of basic letters 1.2.2 Further notes -

How to Speak Emoji : a Guide to Decoding Digital Language Pdf, Epub, Ebook
HOW TO SPEAK EMOJI : A GUIDE TO DECODING DIGITAL LANGUAGE PDF, EPUB, EBOOK National Geographic Kids | 176 pages | 05 Apr 2018 | HarperCollins Publishers | 9780007965014 | English | London, United Kingdom How to Speak Emoji : A Guide to Decoding Digital Language PDF Book Secondary Col 2. Primary Col 1. Emojis are everywhere on your phone and computer — from winky faces to frowns, cats to footballs. They might combine a certain face with a particular arrow and the skull emoji, and it means something specific to them. Get Updates. Using a winking face emoji might mean nothing to us, but our new text partner interprets it as flirty. And yet, once he Parenting in the digital age is no walk in the park, but keep this in mind: children and teens have long used secret languages and symbols. However, not all users gave a favourable response to emojis. Black musicians, particularly many hip-hop artists, have contributed greatly to the evolution of language over time. A collection of poems weaving together astrology, motherhood, music, and literary history. Here begins the new dawn in the evolution the language of love: emoji. She starts planning how they will knock down the wall between them to spend more time together. Irrespective of one's political standpoint, one thing was beyond dispute: this was a landmark verdict, one that deserved to be reported and analysed with intelligence - and without bias. Though somewhat If a guy likes you, he's going to make sure that any opportunity he has to see you, he will. Here and Now Here are 10 emoticons guys use only when they really like you! So why do they do it? The iOS 6 software. -

Urdu Alphabet 1 Urdu Alphabet
Urdu alphabet 1 Urdu alphabet Urdu alphabet ﺍﺭﺩﻭ ﺗﮩﺠﯽ Example of writing in the Urdu alphabet: Urdu Type Abjad Languages Urdu, Balti, Burushaski, others Parent systems Proto-Sinaitic • Phoenician • Aramaic • Nabataean • Arabic • Perso-Arabic • Urdu alphabet ﺍﺭﺩﻭ ﺗﮩﺠﯽ [1] Unicode range U+0600 to U+06FF [2] U+0750 to U+077F [3] U+FB50 to U+FDFF [4] U+FE70 to U+FEFF Urdu alphabet ﮮ ﯼ ء ﮪ ﻩ ﻭ ﻥ ﻡ ﻝ ﮒ ﮎ ﻕ ﻑ ﻍ ﻉ ﻅ ﻁ ﺽ ﺹ ﺵ ﺱ ﮊ ﺯ ﮌ ﺭ ﺫ ﮈ ﺩ ﺥ ﺡ ﭺ ﺝ ﺙ ﭦ ﺕ ﭖ ﺏ ﺍ Extended Perso-Arabic script • History • Diacritics • Hamza • Numerals • Numeration The Urdu alphabet is the right-to-left alphabet used for the Urdu language. It is a modification of the Persian alphabet, which is itself a derivative of the Arabic alphabet. With 38 letters and no distinct letter cases, the Urdu alphabet is typically written in the calligraphic Nasta'liq script, whereas Arabic is more commonly in the Naskh style. Usually, bare transliterations of Urdu into Roman letters (called Roman Urdu) omit many phonemic elements that have no equivalent in English or other languages commonly written in the Latin script. The National Language Authority of Pakistan has developed a number of systems with specific notations to signify non-English sounds, but ﺥ ﻍ ﻁ these can only be properly read by someone already familiar with Urdu, Persian, or Arabic for letters such as Urdu alphabet 2 [citation needed].ﮌ and Hindi for letters such as ﻕ or ﺹ ﺡ ﻉ ﻅ ﺽ History The Urdu language emerged as a distinct register of Hindustani well before the Partition of India, and it is distinguished most by its extensive Persian influences (Persian having been the official language of the Mughal government and the most prominent lingua franca of the Indian subcontinent for several centuries prior to the solidification of British colonial rule during the 19th century). -

CJKV Unified Ideographs Extension C
22nd International Unicode Conference (IUC22) Unicode and the Web: Evolution or Revolution? September 9 - 13, 2002, San Jose, California http://www.unicode.org/iuc/iuc22/ CJKV Unified Ideographs Extension C Richard S. COOK Linguistics Department University of California, Berkeley [email protected] http://stedt.berkeley.edu/ 2002-09-18-10:31 INTRODUCTION This presentation is concerned with introducing the audience to some of the issues surrounding Ideographic Rapporteur Group (ISO/IEC JTC1/SC2/WG2/IRG) work on “CJK Unified Ideographs Extension C” (Ext C), including the following: (1) The IRG methodology constraining glyph submissions for Ext C1 (why more Han characters and which?) (2) The method of preparing glyph submissions for the Unicode Technical Committee (UTC) (3) IRG member submissions for Ext C1, introducing some of the submitted glyphs, the print sources for the glyph submissions (4) The IRG process of submission evaluation (5) The impact of submitted glyphs on the “Han Variant” problem (see Cook, IUC-19) (6) Plans for Ext C2 UTC submissions 22nd International Unicode Conference1 San Jose, California, September 2002 CJKV Unified Ideographs Extension C BACKGROUND As many people already know, The Unicode Standard 3.2 is the best thing ever to happen to the digitization of Chinese texts. The immense work done to produce the CJKV1 part of this standard, undertaken by the Ideographic Rapporteur Group (IRG)2, has pushed CJKV computing to higher levels than many had ever thought possible. With the IRG’s creation of “Extension B”, 42,711 new characters were added to The Unicode Standard, so that it now encodes a total of 70,207 unique “ideographs”.3 The issue is somewhat complicated by things such as “compatibility characters which are not actually compatibility characters”. -
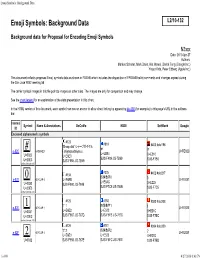
Emoji Symbols: Background Data
Emoji Symbols: Background Data Emoji Symbols: Background Data Background data for Proposal for Encoding Emoji Symbols N3xxx Date: 2010-Apr-27 Authors: Markus Scherer, Mark Davis, Kat Momoi, Darick Tong (Google Inc.) Yasuo Kida, Peter Edberg (Apple Inc.) This document reflects proposed Emoji symbols data as shown in FDAM8 which includes the disposition of FPDAM8 ballot comments and changes agreed during the San José WG2 meeting 56. The carrier symbol images in this file point to images on other sites. The images are only for comparison and may change. See the chart legend for an explanation of the data presentation in this chart. In the HTML version of this document, each symbol row has an anchor to allow direct linking by appending #e-4B0 (for example) to this page's URL in the address bar. Internal Symbol Name & Annotations DoCoMo KDDI SoftBank Google ID Enclosed alphanumeric symbols #123 #818 'Sharp dial' シャープダイヤル #403 #old196 # # # e-82C ⃣ HASH KEY 「shiyaapudaiyaru」 U+FE82C U+EB84 U+0023 U+E6E0 U+E210 SJIS-F489 JIS-7B69 U+20E3 SJIS-F985 JIS-7B69 SJIS-F7B0 unified (Unicode 3.0) #325 #134 #402 #old217 0 四角数字0 0 e-837 ⃣ KEYCAP 0 U+E6EB U+FE837 U+E5AC U+0030 SJIS-F990 JIS-784B U+E225 U+20E3 SJIS-F7C9 JIS-784B SJIS-F7C5 unified (Unicode 3.0) #125 #180 #393 #old208 1 '1' 1 四角数字1 1 e-82E ⃣ KEYCAP 1 U+FE82E U+0031 U+E6E2 U+E522 U+E21C U+20E3 SJIS-F987 JIS-767D SJIS-F6FB JIS-767D SJIS-F7BC unified (Unicode 3.0) #126 #181 #394 #old209 '2' 2 四角数字2 e-82F KEYCAP 2 2 U+FE82F 2⃣ U+E6E3 U+E523 U+E21D U+0032 SJIS-F988 JIS-767E SJIS-F6FC JIS-767E SJIS-F7BD -

The Impact of Arabic Orthography on Literacy and Economic Development in Afghanistan
International Journal of Education, Culture and Society 2019; 4(1): 1-12 http://www.sciencepublishinggroup.com/j/ijecs doi: 10.11648/j.ijecs.20190401.11 ISSN: 2575-3460 (Print); ISSN: 2575-3363 (Online) The Impact of Arabic Orthography on Literacy and Economic Development in Afghanistan Anwar Wafi Hayat Department of Economics, Kabul University, Kabul, Afghanistan Email address: To cite this article: Anwar Wafi Hayat. The Impact of Arabic Orthography on Literacy and Economic Development in Afghanistan. International Journal of Education, Culture and Society . Vol. 4, No. 1, 2019, pp. 1-12. doi: 10.11648/j.ijecs.20190401.11 Received : October 15, 2018; Accepted : November 8, 2018; Published : January 31, 2019 Abstract: Currently, Pashto and Dari (Afghan Persian), the two official languages, and other Afghan languages are written in modified Arabic alphabets. Persian adopted the Arabic alphabets in the ninth century, and Pashto, in sixteenth century CE. This article looks at how the Arabic Orthography has hindered Literacy and Economic development in Afghanistan. The article covers a comprehensive analysis of Arabic Orthography adopted for writing Dari and Pashto, a study of the proposed Arabic Language reforms, and research conducted about reading and writing difficulty in Arabic script by Arab intellectuals. The study shows how adopting modified Latin alphabets for a language can improve literacy level which further plays its part in the economic development of a country. The article dives into the history of Romanization of languages in the Islamic World and its impact on Literacy and economic development in those countries. Romanization of the Afghan Official languages and its possible impact on Literacy, Economy, and Peace in Afghanistan is discussed.