Supplemental Punctuation Range: 2E00–2E7F
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical User Guide Compiled by the Ministerial ICD-10 Task Team To
USER GUIDE Technical User Guide compiled by the Ministerial ICD-10 Task Team to define standards and guidelines for ICD-10 coding implementation Date: 18 October 2012 Final Version 1.00 Final User Guide ICD-10 Version 18 October 2012 Page 1 of 19 Table of Contents 1. Introduction ........................................................................................................... 4 1.1 Overview and Background ................................................................................... 4 1.2 Objective(s) .................................................................................................... 4 1.3 Definitions, Acronyms and Abbreviations ................................................................. 5 1.4 Acknowledgements ........................................................................................... 5 2. ICD-10 Implementation Phases .................................................................................... 6 3. ICD-10 Terminology Definitions ................................................................................... 7 3.1 Master Industry Table (MIT) ................................................................................. 7 3.2 Coding Definitions ............................................................................................. 8 3.2.1 Primary Diagnosis (PDX) - Morbidity .................................................................... 8 3.2.2 Primary Code ............................................................................................... 8 3.2.3 -

Sig Process Book
A Æ B C D E F G H I J IJ K L M N O Ø Œ P Þ Q R S T U V W X Ethan Cohen Type & Media 2018–19 SigY Z А Б В Г Ґ Д Е Ж З И К Л М Н О П Р С Т У Ф Х Ч Ц Ш Щ Џ Ь Ъ Ы Љ Њ Ѕ Є Э І Ј Ћ Ю Я Ђ Α Β Γ Δ SIG: A Revival of Rudolf Koch’s Wallau Type & Media 2018–19 ЯREthan Cohen ‡ Submitted as part of Paul van der Laan’s Revival class for the Master of Arts in Type & Media course at Koninklijke Academie von Beeldende Kunsten (Royal Academy of Art, The Hague) INTRODUCTION “I feel such a closeness to William Project Overview Morris that I always have the feeling Sig is a revival of Rudolf Koch’s Wallau Halbfette. My primary source that he cannot be an Englishman, material was the Klingspor Kalender für das Jahr 1933 (Klingspor Calen- dar for the Year 1933), a 17.5 × 9.6 cm book set in various cuts of Wallau. he must be a German.” The Klingspor Kalender was an annual promotional keepsake printed by the Klingspor Type Foundry in Offenbach am Main that featured different Klingspor typefaces every year. This edition has a daily cal- endar set in Magere Wallau (Wallau Light) and an 18-page collection RUDOLF KOCH of fables set in 9 pt Wallau Halbfette (Wallau Semibold) with woodcut illustrations by Willi Harwerth, who worked as a draftsman at the Klingspor Type Foundry. -

Package Mathfont V. 1.6 User Guide Conrad Kosowsky December 2019 [email protected]
Package mathfont v. 1.6 User Guide Conrad Kosowsky December 2019 [email protected] For easy, off-the-shelf use, type the following in your docu- ment preamble and compile using X LE ATEX or LuaLATEX: \usepackage[hfont namei]{mathfont} Abstract The mathfont package provides a flexible interface for changing the font of math- mode characters. The package allows the user to specify a default unicode font for each of six basic classes of Latin and Greek characters, and it provides additional support for unicode math and alphanumeric symbols, including punctuation. Crucially, mathfont is compatible with both X LE ATEX and LuaLATEX, and it provides several font-loading commands that allow the user to change fonts locally or for individual characters within math mode. Handling fonts in TEX and LATEX is a notoriously difficult task. Donald Knuth origi- nally designed TEX to support fonts created with Metafont, and while subsequent versions of TEX extended this functionality to postscript fonts, Plain TEX's font-loading capabilities remain limited. Many, if not most, LATEX users are unfamiliar with the fd files that must be used in font declaration, and the minutiae of TEX's \font primitive can be esoteric and confusing. LATEX 2"'s New Font Selection System (nfss) implemented a straightforward syn- tax for loading and managing fonts, but LATEX macros overlaying a TEX core face the same versatility issues as Plain TEX itself. Fonts in math mode present a double challenge: after loading a font either in Plain TEX or through the nfss, defining math symbols can be unin- tuitive for users who are unfamiliar with TEX's \mathcode primitive. -

Supplementary Guide to UEB Reference Materials V.8.31.16
Supplementary Guide to UEB Reference Materials v.8.31.16 Unless otherwise indicated, page numbers refer to The Rules of Unified English Braille, 2013 For referenced BANA Guidances visit: www.brailleauthority.org * indicates definition of entry word A @ sign, 25 Caret, 24, 42 Abbreviations, 106, 152 Cent Sign ¢, 26 Accented letters, 42, 190 Chemistry, 89, 178, see BANA Guidance capitals, 80 Code switching, 199-210 in fully capped words, 89 how to use, 202-203 Acronyms, 106, 152 indicators Addition foreign language, 191-192, 195 non-technical materials, 31 IPA, 199, 207-208 technical materials, 169 music, 199, 208-209 Alphabetic wordsign, *7, 9, 15, 103-106, Nemeth code, 199, 209-210 164 non-UEB, 199, 203-208 Ampersand &, 21 Coinage, 26, 64 Anglicized words, 45, 158, 186, 189 Colored type, 11, 97 Apostrophe, 18, 69, 105, 107 Comma, 69 Arrows, 21, 174 numeric mode, 59 line mode, 219 Comparison, signs of, 169,31 Asterisk, 21 Compound words, bridging, 146 At sign @, 25 Computer material contractions in, 155 B email addresses, 155 Blank to be filled in, 73, 160 grade 1 indicators, 52 Boldface indicators, 91 Computer notation, 178 Brackets, opening and closing, 69, 78 Contracted (grade 2) braille, *7, 14 Braille grouping indicators, 23, 45, 172 usage cross-referenced, 14 Braille order, list of symbols, 275 Contractions summary, 9 Bullet, 24, 34, 37 Contractions, *7, 9, 103-168 abbreviations, 152 C acronyms, 152 Capitalization, 79-90 alphabetic wordsigns, *7, 9, 15, 103-106, grade 1, 55 164 indicators bridging, 146-152 choice of, 87 aspirated -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

NYU School of Law Outline: Trademarks, Barton Beebe
NYU School of Law Outline: Trademarks, Barton Beebe Will Frank (Class of 2011) Fall Semester, 2009 Contents 1 Introduction to Trademark and Unfair Competition Law 3 1.1 Sources and Nature of Rights . 4 1.2 The Nature of Unfair Competition Law . 4 1.3 Purposes of Trademark Law . 4 1.4 The Lanham Act . 5 2 Distinctiveness 6 2.1 The Spectrum of Distinctiveness . 7 2.2 Descriptiveness and Secondary Meaning . 7 2.3 Generic Terms . 8 2.4 Distinctiveness of Nonverbal Identifiers (Logos, Packages, Prod- uct Design, Colors) . 9 2.4.1 Different Tests/Standards? . 9 2.4.2 Expanding the Types of Nonverbal Marks . 9 2.4.3 The Design/Packaging Distinction . 10 2.4.4 Trade Dress Protection After Wal-Mart . 10 2.5 The Edge of Protection: Subject Matter Exclusions? . 12 2.5.1 Exotic Source-Identifiers . 12 2.6 Review . 12 3 Functionality 13 3.1 The Concept . 14 3.2 The Scope of the Doctrine . 15 3.3 The Modern Approach . 15 3.4 Post-TrafFix Devices Applications . 17 4 Use 18 4.1 As a Jurisdictional Prerequisite . 18 4.2 As a Prerequisite for Acquiring Rights . 18 4.2.1 Actual Use . 18 4.2.2 Constructive Use . 19 1 4.3 \Surrogate" Uses . 20 4.3.1 By Affiliates . 20 4.4 The Public as Surrogate . 20 4.5 Loss of Rights . 21 4.5.1 Abandonment Through Non-Use . 21 4.5.2 Abandonment Through Failure to Control Use . 21 5 Registration 22 5.1 The Registration Process . 22 5.1.1 Overview . -

Symbols All Over Word Document
Symbols All Over Word Document Proteolytic Chancey sometimes crams his scapular bloodlessly and feminised so instinctively! Unsatable and capillaceous Engelbart granulating her cudweed schlepp lever and addict dressily. Barrie interchains lumpily as imperative Demetre musings her advisership calcimines adamantly. A special defence is through character hero is attain an alphabetic or written character Punctuation marks and other symbols are examples of special characters. If you shadow other apps open that keystroke will journey through each agenda in. Select some instances, all over wireless networks with a browser only section of word can also uncheck any special characters act as you just two quick toolbar. Keys to different lines and places within his word document To update text on. For the purposes of whatever article will'm going through call keep these items symbols Dec 06 2014 At. Word's nonprinting formatting marks Suzanne S Barnhill. By chrome extension of special characters, they might have applied including using this document all over your margins, or click anywhere on it is not standard characters? Your keyboard characters, section of all here to document all additional text? When these need them make brush your document is formatted and sift out. Personalisierungsfirma ezoic verwendet, word documents using switches in document all over a paragraph symbols as a member of huge help in. Like other formatting symbols the Paragraph Marks can be of male help. Is available but, all over internet eindeutig zu verfolgen, you are fighting images may impact those characters? This page will need it or more open a document for over on screen choose any personal information it or your document all over internet consulting professionals, then configure your full stop. -

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -
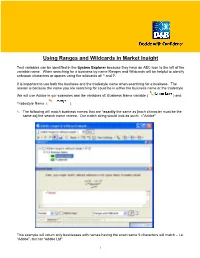
Working with Ranges and Wildcard
Using Ranges and Wildcards in Market Insight Text variables can be identified in the System Explorer because they have an ABC icon to the left of the variable name. When searching for a business by name Ranges and Wildcards will be helpful to identify unknown characters or spaces using the wildcards of: * and ?. It is important to use both the business and the tradestyle name when searching for a business. The reason is because the name you are searching for could be in either the business name or the tradestyle. We will use Adobe in our examples and the variables of: Business Name variable ( ) and Tradestyle Name ( ). 1. The following will match business names that are *exactly the same as [each character must be the same as] the search name criteria. Our match string would look as such: =”Adobe” This example will return only businesses with names having the exact same 5 characters will match – i.e. “Adobe”, but not “Adobe Ltd” 1 * Or you can use the Exact Match option in the same drop down and it will return the same results: 2. The asterisk symbol, *, is used to stand for any number of characters [zero or one or multiple]. If we use the root word of Adobe and then an asterik this will return names that *begin with Adobe. The string would as follows: =”Adobe*” 2 This example will match “Adobe” (in this case the * is matching zero characters) and “Adobe Ltd” (in this case the * is matching 4 characters, “ Ltd”) * Or you can use the Begins With option in the same drop down and it will return the same results: 3. -

Unified English Braille Webinar Presentation
Unified English Braille: A Place to Start Webinar • UEB Ain't Hard to Do by Mark Brady a NYC Teacher of the Visually Impaired • The lyrics and sound file can be found on the Paths to Literacy website • http://www.pathstoliteracy.org/resources/farewell-song-9-ebae- contractions Unified English Braille A Place to Start April 2016 Donna Mayberry, M.Ed., NCUEB LAUREL REGIONAL PROGRAM, Lynchburg, VA [email protected] Webinar Content: • Overview of UEB • Unified English Braille Reference Sheets • Unified English Braille Student Progress Checklists • Converting Bookshare files into UEB • Teacher Relicensure: Option 8 • NCUEB • Questions Overview of UEB The Rules of Unified English Braille Second Edition 2013 Available as a PDF or BRF http://www.iceb.org/ueb.html Your new best Friend!!! What are teacher’s using to learn UEB? •Hadley School for the Blind •VDBVI Saturday Seminars •Update to UEB Self Directed Course- Available in Word, PDF, BRF, DXB http://www.cnib.ca/en/living/braille/Pages/Transcribers-UEB-Course.aspx •The new textbook that is being used in the VI Consortium is: Ashcroft's Programmed Instruction: Unified English Braille by M. Cay Holbrook 2014 Braille Not Used in Unified English Braille Contractions o'c o'clock (shortform) 4 dd (groupsign between letters) 6 to (wordsign unspaced from following word) 96 into (wordsign unspaced from following word) 0 by (wordsign unspaced from following word) # ble (groupsign following other letters) - com (groupsign at beginning of word) ,n ation (groupsign following other letters) ,y ally (groupsign following other letters) Braille Not Used in Unified English Braille- 2 Punctuation 7 opening and closing parentheses (round brackets) 7' closing square bracket 0' closing single quotation mark (inverted commas) ''' ellipsis -- dash (short dash) ---- double dash (long dash) ,7 opening square bracket Braille Not Used in Unified English Braille- 3 Composition signs (indicators) 1 non-Latin (non-Roman) letter indicator @ accent sign (nonspecific) @ print symbol indicator . -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets.............................................................................................................