Health Classification Systems - ICD-10 Morbidity Coding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical User Guide Compiled by the Ministerial ICD-10 Task Team To
USER GUIDE Technical User Guide compiled by the Ministerial ICD-10 Task Team to define standards and guidelines for ICD-10 coding implementation Date: 18 October 2012 Final Version 1.00 Final User Guide ICD-10 Version 18 October 2012 Page 1 of 19 Table of Contents 1. Introduction ........................................................................................................... 4 1.1 Overview and Background ................................................................................... 4 1.2 Objective(s) .................................................................................................... 4 1.3 Definitions, Acronyms and Abbreviations ................................................................. 5 1.4 Acknowledgements ........................................................................................... 5 2. ICD-10 Implementation Phases .................................................................................... 6 3. ICD-10 Terminology Definitions ................................................................................... 7 3.1 Master Industry Table (MIT) ................................................................................. 7 3.2 Coding Definitions ............................................................................................. 8 3.2.1 Primary Diagnosis (PDX) - Morbidity .................................................................... 8 3.2.2 Primary Code ............................................................................................... 8 3.2.3 -

Supplemental Punctuation Range: 2E00–2E7F
Supplemental Punctuation Range: 2E00–2E7F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Characters for Classical Latin
Characters for Classical Latin David J. Perry version 13, 2 July 2020 Introduction The purpose of this document is to identify all characters of interest to those who work with Classical Latin, no matter how rare. Epigraphers will want many of these, but I want to collect any character that is needed in any context. Those that are already available in Unicode will be so identified; those that may be available can be debated; and those that are clearly absent and should be proposed can be proposed; and those that are so rare as to be unencodable will be known. If you have any suggestions for additional characters or reactions to the suggestions made here, please email me at [email protected] . No matter how rare, let’s get all possible characters on this list. Version 6 of this document has been updated to reflect the many characters of interest to Latinists encoded as of Unicode version 13.0. Characters are indicated by their Unicode value, a hexadecimal number, and their name printed IN SMALL CAPITALS. Unicode values may be preceded by U+ to set them off from surrounding text. Combining diacritics are printed over a dotted cir- cle ◌ to show that they are intended to be used over a base character. For more basic information about Unicode, see the website of The Unicode Consortium, http://www.unicode.org/ or my book cited below. Please note that abbreviations constructed with lines above or through existing let- ters are not considered separate characters except in unusual circumstances, nor are the space-saving ligatures found in Latin inscriptions unless they have a unique grammatical or phonemic function (which they normally don’t). -

Unified English Braille (UEB) General Symbols and Indicators
Unified English Braille (UEB) General Symbols and Indicators UEB Rulebook Section 3 Published by International Council on English Braille (ICEB) space (see 3.23) ⠣ opening braille grouping indicator (see 3.4) ⠹ first transcriber‐defined print symbol (see 3.26) ⠫ shape indicator (see 3.22) ⠳ arrow indicator (see 3.2) ⠳⠕ → simple right pointing arrow (east) (see 3.2) ⠳⠩ ↓ simple down pointing arrow (south) (see 3.2) ⠳⠪ ← simple left pointing arrow (west) (see 3.2) ⠳⠬ ↑ simple up pointing arrow (north) (see 3.2) ⠒ ∶ ratio (see 3.17) ⠒⠒ ∷ proportion (see 3.17) ⠢ subscript indicator (see 3.24) ⠶ ′ prime (see 3.11 and 3.15) ⠶⠶ ″ double prime (see 3.11 and 3.15) ⠔ superscript indicator (see 3.24) ⠼⠡ ♮ natural (see 3.18) ⠼⠣ ♭ flat (see 3.18) ⠼⠩ ♯ sharp (see 3.18) ⠼⠹ second transcriber‐defined print symbol (see 3.26) ⠜ closing braille grouping indicator (see 3.4) ⠈⠁ @ commercial at sign (see 3.7) ⠈⠉ ¢ cent sign (see 3.10) ⠈⠑ € euro sign (see 3.10) ⠈⠋ ₣ French franc sign (see 3.10) ⠈⠇ £ pound sign (pound sterling) (see 3.10) ⠈⠝ ₦ naira sign (see 3.10) ⠈⠎ $ dollar sign (see 3.10) ⠈⠽ ¥ yen sign (Yuan sign) (see 3.10) ⠈⠯ & ampersand (see 3.1) ⠈⠣ < less‐than sign (see 3.17) ⠈⠢ ^ caret (3.6) ⠈⠔ ~ tilde (swung dash) (see 3.25) ⠈⠼⠹ third transcriber‐defined print symbol (see 3.26) ⠈⠜ > greater‐than sign (see 3.17) ⠈⠨⠣ opening transcriber’s note indicator (see 3.27) ⠈⠨⠜ closing transcriber’s note indicator (see 3.27) ⠈⠠⠹ † dagger (see 3.3) ⠈⠠⠻ ‡ double dagger (see 3.3) ⠘⠉ © copyright sign (see 3.8) ⠘⠚ ° degree sign (see 3.11) ⠘⠏ ¶ paragraph sign (see 3.20) -
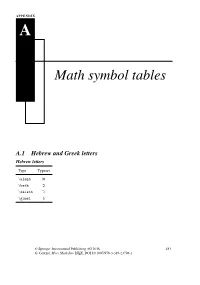
Math Symbol Tables
APPENDIX A Math symbol tables A.1 Hebrew and Greek letters Hebrew letters Type Typeset \aleph ℵ \beth ℶ \daleth ℸ \gimel ℷ © Springer International Publishing AG 2016 481 G. Grätzer, More Math Into LATEX, DOI 10.1007/978-3-319-23796-1 482 Appendix A Math symbol tables Greek letters Lowercase Type Typeset Type Typeset Type Typeset \alpha \iota \sigma \beta \kappa \tau \gamma \lambda \upsilon \delta \mu \phi \epsilon \nu \chi \zeta \xi \psi \eta \pi \omega \theta \rho \varepsilon \varpi \varsigma \vartheta \varrho \varphi \digamma ϝ \varkappa Uppercase Type Typeset Type Typeset Type Typeset \Gamma Γ \Xi Ξ \Phi Φ \Delta Δ \Pi Π \Psi Ψ \Theta Θ \Sigma Σ \Omega Ω \Lambda Λ \Upsilon Υ \varGamma \varXi \varPhi \varDelta \varPi \varPsi \varTheta \varSigma \varOmega \varLambda \varUpsilon A.2 Binary relations 483 A.2 Binary relations Type Typeset Type Typeset < < > > = = : ∶ \in ∈ \ni or \owns ∋ \leq or \le ≤ \geq or \ge ≥ \ll ≪ \gg ≫ \prec ≺ \succ ≻ \preceq ⪯ \succeq ⪰ \sim ∼ \approx ≈ \simeq ≃ \cong ≅ \equiv ≡ \doteq ≐ \subset ⊂ \supset ⊃ \subseteq ⊆ \supseteq ⊇ \sqsubseteq ⊑ \sqsupseteq ⊒ \smile ⌣ \frown ⌢ \perp ⟂ \models ⊧ \mid ∣ \parallel ∥ \vdash ⊢ \dashv ⊣ \propto ∝ \asymp ≍ \bowtie ⋈ \sqsubset ⊏ \sqsupset ⊐ \Join ⨝ Note the \colon command used in ∶ → 2, typed as f \colon x \to x^2 484 Appendix A Math symbol tables More binary relations Type Typeset Type Typeset \leqq ≦ \geqq ≧ \leqslant ⩽ \geqslant ⩾ \eqslantless ⪕ \eqslantgtr ⪖ \lesssim ≲ \gtrsim ≳ \lessapprox ⪅ \gtrapprox ⪆ \approxeq ≊ \lessdot -

Special Symbols in Graphs: Multiple Solutions Abhinav Srivastva, Gilead Sciences
PharmaSUG 2017 - Paper TT05 Special Symbols in Graphs: Multiple Solutions Abhinav Srivastva, Gilead Sciences ABSTRACT It is not uncommon in Graphs to include special symbols at various places like axes, legends, titles and footnotes, and practically anywhere in the plot area. The paper discusses multiple ways how special symbols can be inserted as applicable in SAS/GRAPH®, Graph Annotations, ODS Graphics® - SG Procedures, SG Annotations and Graph Template Language (GTL). There will be some examples presented which leverage the power of Formats to put these into action. The techniques will vary depending on the version of SAS® and the type of procedure (PROC) used. INTRODUCTION Graphs are a routine part of FDA submission like Clinical Study Report (CSR), NDA/BLA in depicting key efficacy and safety measures. With the increased need and complexity, there often present challenges to display information in a way that facilitates readability to the consumer. SAS enables adding special symbols in graphs through traditional to more advanced ways as presented in the paper. The techniques include – copy/paste from Character map, keystroke sequences (Alt+ XXXX), changing font style, incorporating hexadecimal characters, using byte function, with move= <option>, In-line formatting, unicode characters in combination with escape character and attribute mapping in ODS Graphics. In addition, SYMBOLCHAR and SYMBOLIMAGE in SG allows symbols and images to be inserted in a unique way. OVERVIEW OF SOLUTIONS A brief discussion along with a collection of examples -

Adobe Framemaker 9 Character Sets
ADOBE®® FRAMEMAKER 9 Character Sets © 2008 Adobe Systems Incorporated. All rights reserved. Adobe® FrameMaker® 9 Character Sets for Windows® If this guide is distributed with software that includes an end-user agreement, this guide, as well as the software described in it, is furnished under license and may be used or copied only in accordance with the terms of such license. Except as permitted by any such license, no part of this guide may be reproduced, stored in a retrieval system, or trans- mitted, in any form or by any means, electronic, mechanical, recording, or otherwise, without the prior written permission of Adobe Systems Incorporated. Please note that the content in this guide is protected under copyright law even if it is not distributed with software that includes an end-user license agreement. The content of this guide is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Adobe Systems Incorpo- rated. Adobe Systems Incorporated assumes no responsibility or liability for any errors or inaccuracies that may appear in the informational content contained in this guide. Please remember that existing artwork or images that you may want to include in your project may be protected under copyright law. The unauthorized incorporation of such material into your new work could be a violation of the rights of the copyright owner. Please be sure to obtain any permission required from the copyright owner. Any references to company names in sample templates are for demonstration purposes only and are not intended to refer to any actual organization. -

TEX Reference Card
TEX Reference Card Relations Accents (for Plain TEX) · \leq or \le ¸ \geq or \ge ´ \equiv Type Example In Math In Text Á \prec  \succ » \sim hata ^ \hat \^ Greek Letters ¹ \preceq º \succeq ' \simeq expanding hat abcc \widehat none ® \alpha ¶ \iota % \varrho ¿ \ll À \gg ³ \asymp checka · \check \v ¯ \beta · \kappa σ \sigma ½ \subset ⊃ \supset ¼ \approx tildea ~ \tilde \~ γ \gamma ¸ \lambda & \varsigma ⊆ \subseteq ¶ \supseteq =» \cong expanding tilde abcf \widetilde none ± \delta ¹ \mu ¿ \tau v \sqsubseteq w \sqsupseteq ./ \bowtie acutea ¶ \acute \' ² \epsilon º \nu υ \upsilon 2 \in 2= \notin 3 \ni or \owns gravea ` \grave \` ` \vdash a \dashv j= \models dota _ \dot \. " \varepsilon » \xi Á \phi : ³ \zeta o \o ' \varphi ^ \smile j \mid = \doteq double dota Ä \ddot \" ´ \eta ¼ \pi  \chi _ \frown k \parallel ? \perp brevea ¸ \breve \u θ \theta $ \varpi à \psi / \propto bara ¹ \bar \= # \vartheta ½ \rho ! \omega Most relations can be negated by pre¯xing them with \not. vector ~a \vec none ¡ \Gamma ¥ \Xi © \Phi 6´ \not\equiv 2= \notin 6= \ne The \skewhnumberi command shifts accents for proper posi- ¢ \Delta ¦ \Pi ª \Psi tioning, the larger the hnumberi, the more right the shift. Com- £ \Theta § \Sigma \Omega Arrows pare ¤ \Lambda ¨ \Upsilon ^ ^ à \leftarrow or \gets á \longleftarrow \hat{\hat A} gives A^ , \skew6\hat{\hat A} gives A^ . Symbols of Type Ord ( \Leftarrow (= \Longleftarrow ! \rightarrow or \to ¡! \longrightarrow Elementary Math Control Sequences @ \aleph 0 \prime 8 \forall ) \Rightarrow =) \Longrightarrow overline a formula -

APPENDIX 1 BRAILLE SYMBOLS and INDICATORS Line 1
Appendix 1 Page 1 APPENDIX 1 BRAILLE SYMBOLS AND INDICATORS Braille Characters Letters Numbers Contractions Indicators Punctuation and Symbols Within each group, the braille signs are listed in alphabetic order by name. Each braille sign is listed under all possible names. In the last three groups, references to The Rules of Unified English Braille appear in the right-hand column. Braille Characters [1.1.2] Line 1: a b c d e f g h i j Line 2: k l m n o p q r s t Line 3: u v x y z & = ( ! ) Line 4: * < % ? : $ ] \ [ w Line 5: 1 2 3 4 5 6 7 8 9 0 Line 6: / + # > ' - Line 7: @ ^ _ " . ; , Page 2 Appendix 1 Letters, Numbers Letters [4.1] a a h h o o v v b b i i p p w w c c j j q q x x d d k k r r y y e e l l s s z z f f m m t t g g n n u u Numbers [6] 1 #a 9 #i 2 #b 0 #j 3 #c 10 #aj 4 #d 1,000 #a1jjj 5 #e 100 000 #ajj"jjj 6 #f 3.14 #c4ad 7 #g ½ #a/b 8 #h Contractions Appendix 1 Page 3 Contractions [10] about ab 10.9 because 2c 10.9 above abv 10.9 before 2f 10.9 according ac 10.9 behind 2h 10.9 across acr 10.9 below 2l 10.9 after af 10.9 beneath 2n 10.9 afternoon afn 10.9 beside 2s 10.9 afterward afw 10.9 between 2t 10.9 again ag 10.9 beyond 2y 10.9 against ag/ 10.9 blind bl 10.9 almost alm 10.9 braille brl 10.9 already alr 10.9 but b 10.1 also al 10.9 can c 10.1 although al? 10.9 cannot _c 10.7 altogether alt 10.9 cc 3 10.6 always alw 10.9 ch * 10.4 ance .e 10.8 character "* 10.7 and & 10.3 child * 10.2 ar > 10.4 children *n 10.9 as z 10.1 con 3 10.6 bb 2 10.6 conceive 3cv 10.9 be 2 10.5, conceiving 3cvg 10.9 10.6 could cd 10.9 Page 4 Appendix -

Typingmath Formulas the Control Sequence \Prime Stands for The
130 Chapter 16: TypingMath Formulas The control sequence \prime stands for the symbol ‘0’, which is used prime tensor notation mostly in superscripts. In fact, ‘0’ is so big as it stands that you would never sqrt want to use it except in a subscript or superscript, where it occurs in a smaller underline overline size. Here are some typical examples: surds, see sqrt vinculum, see overline Input Output root 0 $y_1^\prime$ y1 00 $y_2^{\prime\prime}$ y2 000 $y_3^{\prime\prime\prime}$ y3 Since single and double primes occur rather frequently, plain TEX provides a convenient abbreviation: You can simply type ’ instead of ^\prime, and ’’ instead of ^{\prime\prime}, and so on. $f’[g(x)]g’(x)$ f 0[g(x)]g0(x) 0 00 $y_1’+y_2’’$ y1 + y2 0 00 $y’_1+y’’_2$ y1 + y2 000 02 $y’’’_3+g’^2$ y3 + g x EXERCISE 16.5 Why do you think TEX treats \prime as a large symbol that appears only in superscripts, instead of making it a smaller symbol that has already been shifted up into the superscript position? x EXERCISE 16.6 Mathematicians sometimes use “tensor notation” in which subscripts and su- jk perscripts are staggered, as in ‘Ri l’. Explain how to achieve such an effect. Another way to get complex formulas from simple ones is to use the con- trol sequences \sqrt, \underline, or \overline. Like ^ and _, these operations apply to the character or subformula that follows them: √ $\sqrt2$ 2 √ $\sqrt{x+2}$ x + 2 $\underline4$ 4 $\overline{x+y}$ x + y $\overline x+\overline y$ x + y $x^{\underline n}$ xn $x^{\overline{m+n}}$ xm+n p √ $\sqrt{x^3+\sqrt\alpha}$ x3 + α √ You can also get cube roots ‘ 3 ’ and similar things by using \root: √ $\root 3 \of 2$ 3 2 √ $\root n \of {x^n+y^n}$ n xn + yn √ $\root n+1 \of a$ n+1 a Chapter 16: TypingMath Formulas 133 Appendix F lists many more binary operations, for which you type control times sequences instead of single characters. -

Framemaker 9 Keyboard Shortcuts
Adobe FrameMaker 9 useful shortcuts and information FM ENTERING SPECIAL CHARACTERS Dash (en). –. \= Change settings to As Is in Find Character Bullet. • . Ctrl+q % Ellipsis. .…. \e Format and Change To Character Format Dagger. †. Ctrl+q space Florin. ƒ. \Shift+f dialog boxes. Shift+F8 Double Dagger. ‡. Ctrl+q ` Forced Return. \r Change settings to match selected text in Find Trademark. ™. Ctrl+q * Fraction . �. \/ Character Format and Change To Character Copyright. ©. .Ctrl+q ) Grave. ` . .\{ Format dialog boxes. Shift+F9 Registered trademark. ® . Ctrl+q ( Guilsingl left. ‹ . .\( Display Set Find/Change Parameters. Esc f i s Paragraph symbol. ¶. Ctrl+q & Guilsingl right. .› . .\) Tab symbol. \t Section symbol. §. Ctrl+q $ Hungarumlaut. ˝ . \& Forced return. \r Ellipsis. .…. .Ctrl+q Shift+i Hyphen (discretionary). - . .\- End-of-paragraph symbol. \p Em Dash. .—. Ctrl+q Shift+q Hyphen (nonbreaking). - . \+ Start of paragraph . \P En Dash. –. Ctrl+q Shift+p OE ligature. .Œ. Shift+o Shift+e Nonbreaking space. .\ (space) '. .Ctrl+' oe ligature. œ. .\oe Thin space. \i, \st ". Esc" Per thousand. ‰ . \% En space. \N, \sn ‘(Smart Quotes off). .Ctrl+q Shift+t Quote (base single). ' . \, Em space. \M, \sm ’(Smart Quotes off). Ctrl+q Shift+u Quote (base double). ". \g Numeric space. \#, \s# “(Smart Quotes off). Ctrl+q Shift+r, Alt+Ctrl+' Quote (double left). “. .\` End-of-flow symbol. \f ”(Smart Quotes off). Ctrl+q Shift+s, Alt+Ctrl+' Quote (double right). ”. \’ ` (grave) . .\{ Em space. Esc space m, Ctrl+ Shift+space Space (em). .\sm, \Shift+m \ (backslash). .\\ En space. Esc space n, Alt+Ctrl+space Space (en). \sn, \Shift+n Discretionary hyphen. \- (hyphen) Nonbreaking space. Esc space h, Ctrl+space Space (nonbreaking). -

Wiley AMA Manual of Style: a User's Guide
Version 1.3 Wiley Documentation Wiley AMA Manual of Style: A User’s Guide File name: Wiley AMA Manual of Style Version date: 31 January 2019 Version Date Distribution Status and Summary of Changes History Version 01 June Journal copyediting • Standardization of JSS conflicts with AMA 1.1 2018 level stakeholder manual group • Addition of deviation/exceptions allowed • Hyphenated given names in How to Cite section Version 25 June Journal copyediting • Degrees in Author Byline 1.2 2018 level stakeholder • Figure legend update group • FAQ update to use an abbreviation Version 31 Journal copyediting • 2.1 Article History: dates guideline 1.3 January level stakeholder • 2.4 Author Names: degree and job title update 2019 group • 2.5 Author Affiliation: China as country name not to be used for Taiwan • 2.6 Author Correspondence: placement update; email on new line • 2.7 Funding Information: placement update • 2.9 Abstract/Summary: updated instructions • 2.10 Keywords: to be included if journal style • 2.12 Title Page Footnotes: order update • 2.18.1 Figure Legends: label in all caps • 2.19.3 Table Footnotes: order update • 2.22 Equations: updated citation style • 2.25 Conflict of Interest: heading update • 2.26 Author Contributions: heading update • 2.28 Endnotes: heading update Page Footnotes: AMA symbols • 2.30 Author Biography: standard style for author names and headings • 2.31 Supporting Information: updated citation style and standard text • 3.2.18 Nomenclature (Equipment, Devices, and Reagents): manufacturer location not needed anymore • 3.2.23 Spelling out Numbers (Decimals): no leading zero before decimal point with probability values 1 © Wiley Version 1.3 Wiley Documentation Contents PREFACE .............................................................................................................................................................................