The Use of Unicode™ in MARC 21 Records What Is MARC?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Introduction 1
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Package Mathfont V. 1.6 User Guide Conrad Kosowsky December 2019 [email protected]
Package mathfont v. 1.6 User Guide Conrad Kosowsky December 2019 [email protected] For easy, off-the-shelf use, type the following in your docu- ment preamble and compile using X LE ATEX or LuaLATEX: \usepackage[hfont namei]{mathfont} Abstract The mathfont package provides a flexible interface for changing the font of math- mode characters. The package allows the user to specify a default unicode font for each of six basic classes of Latin and Greek characters, and it provides additional support for unicode math and alphanumeric symbols, including punctuation. Crucially, mathfont is compatible with both X LE ATEX and LuaLATEX, and it provides several font-loading commands that allow the user to change fonts locally or for individual characters within math mode. Handling fonts in TEX and LATEX is a notoriously difficult task. Donald Knuth origi- nally designed TEX to support fonts created with Metafont, and while subsequent versions of TEX extended this functionality to postscript fonts, Plain TEX's font-loading capabilities remain limited. Many, if not most, LATEX users are unfamiliar with the fd files that must be used in font declaration, and the minutiae of TEX's \font primitive can be esoteric and confusing. LATEX 2"'s New Font Selection System (nfss) implemented a straightforward syn- tax for loading and managing fonts, but LATEX macros overlaying a TEX core face the same versatility issues as Plain TEX itself. Fonts in math mode present a double challenge: after loading a font either in Plain TEX or through the nfss, defining math symbols can be unin- tuitive for users who are unfamiliar with TEX's \mathcode primitive. -

A Ruse Secluded Character Set for the Source
Mukt Shabd Journal Issn No : 2347-3150 A Ruse Secluded character set for the Source Mr. J Purna Prakash1, Assistant Professor Mr. M. Rama Raju 2, Assistant Professor Christu Jyothi Institute of Technology & Science Abstract We are rich in data, but information is poor, typically world wide web and data streams. The effective and efficient analysis of data in which is different forms becomes a challenging task. Searching for knowledge to match the exact keyword is big task in Internet such as search engine. Now a days using Unicode Transform Format (UTF) is extended to UTF-16 and UTF-32. With helps to create more special characters how we want. China has GB 18030-character set. Less number of website are using ASCII format in china, recently. While searching some keyword we are unable get the exact webpage in search engine in top place. Issues in certain we face this problem in results announcement, notifications, latest news, latest products released. Mainly on government websites are not shown in the front page. To avoid this trap from common people, we require special character set to match the exact unique keyword. Most of the keywords are encoded with the ASCII format. While searching keyword called cbse net results thousands of websites will have the common keyword as cbse net results. Matching the keyword, it is already encoded in all website as ASCII format. Most of the government websites will not offer search engine optimization. Match a unique keyword in government, banking, Institutes, Online exam purpose. Proposals is to create a character set from A to Z and a to z, for the purpose of data cleaning. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437
PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437 PCL Symbol Set: 10U Unicode glyph correspondence tables. Contact:[email protected] http://pcl.to -- -- -- -- $90 U00C9 Ê Uppercase e acute $21 U0021 Ë Exclamation $91 U00E6 Ì Lowercase ae diphthong $22 U0022 Í Neutral double quote $92 U00C6 Î Uppercase ae diphthong $23 U0023 Ï Number $93 U00F4 & Lowercase o circumflex $24 U0024 ' Dollar $94 U00F6 ( Lowercase o dieresis $25 U0025 ) Per cent $95 U00F2 * Lowercase o grave $26 U0026 + Ampersand $96 U00FB , Lowercase u circumflex $27 U0027 - Neutral single quote $97 U00F9 . Lowercase u grave $28 U0028 / Left parenthesis $98 U00FF 0 Lowercase y dieresis $29 U0029 1 Right parenthesis $99 U00D6 2 Uppercase o dieresis $2A U002A 3 Asterisk $9A U00DC 4 Uppercase u dieresis $2B U002B 5 Plus $9B U00A2 6 Cent sign $2C U002C 7 Comma, decimal separator $9C U00A3 8 Pound sterling $2D U002D 9 Hyphen $9D U00A5 : Yen sign $2E U002E ; Period, full stop $9E U20A7 < Pesetas $2F U002F = Solidus, slash $9F U0192 > Florin sign $30 U0030 ? Numeral zero $A0 U00E1 ê Lowercase a acute $31 U0031 A Numeral one $A1 U00ED B Lowercase i acute $32 U0032 C Numeral two $A2 U00F3 D Lowercase o acute $33 U0033 E Numeral three $A3 U00FA F Lowercase u acute $34 U0034 G Numeral four $A4 U00F1 H Lowercase n tilde $35 U0035 I Numeral five $A5 U00D1 J Uppercase n tilde $36 U0036 K Numeral six $A6 U00AA L Female ordinal (a) http://www.pclviewer.com (c) RedTitan Technology 2005 PCL PC-8, Code Page 437 Page 2 of 5 $37 U0037 M Numeral seven $A7 U00BA N Male ordinal (o) $38 U0038 -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding A
Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding Adobe-Symbol-Encoding csHPPSMath Adobe-Zapf-Dingbats-Encoding csZapfDingbats Arabic ISO-8859-6, csISOLatinArabic, iso-ir-127, ECMA-114, ASMO-708 ASCII US-ASCII, ANSI_X3.4-1968, iso-ir-6, ANSI_X3.4-1986, ISO646-US, us, IBM367, csASCI big-endian ISO-10646-UCS-2, BigEndian, 68k, PowerPC, Mac, Macintosh Big5 csBig5, cn-big5, x-x-big5 Big5Plus Big5+, csBig5Plus BMP ISO-10646-UCS-2, BMPstring CCSID-1027 csCCSID1027, IBM1027 CCSID-1047 csCCSID1047, IBM1047 CCSID-290 csCCSID290, CCSID290, IBM290 CCSID-300 csCCSID300, CCSID300, IBM300 CCSID-930 csCCSID930, CCSID930, IBM930 CCSID-935 csCCSID935, CCSID935, IBM935 CCSID-937 csCCSID937, CCSID937, IBM937 CCSID-939 csCCSID939, CCSID939, IBM939 CCSID-942 csCCSID942, CCSID942, IBM942 ChineseAutoDetect csChineseAutoDetect: Candidate encodings: GB2312, Big5, GB18030, UTF32:UTF8, UCS2, UTF32 EUC-H, csCNS11643EUC, EUC-TW, TW-EUC, H-EUC, CNS-11643-1992, EUC-H-1992, csCNS11643-1992-EUC, EUC-TW-1992, CNS-11643 TW-EUC-1992, H-EUC-1992 CNS-11643-1986 EUC-H-1986, csCNS11643_1986_EUC, EUC-TW-1986, TW-EUC-1986, H-EUC-1986 CP10000 csCP10000, windows-10000 CP10001 csCP10001, windows-10001 CP10002 csCP10002, windows-10002 CP10003 csCP10003, windows-10003 CP10004 csCP10004, windows-10004 CP10005 csCP10005, windows-10005 CP10006 csCP10006, windows-10006 CP10007 csCP10007, windows-10007 CP10008 csCP10008, windows-10008 CP10010 csCP10010, windows-10010 CP10017 csCP10017, windows-10017 CP10029 csCP10029, windows-10029 CP10079 csCP10079, windows-10079 -

Implementing Cross-Locale CJKV Code Conversion
Implementing Cross-Locale CJKV Code Conversion Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-paper.pdf ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-slides.pdf Code Conversion Basics dc • Algorithmic code conversion — Within a single locale: Shift-JIS, EUC-JP, and ISO-2022-JP — A purely mathematical process • Table-driven code conversion — Required across locales: Chinese ↔ Japanese — Required when dealing with Unicode — Mapping tables are required — Can sometimes be faster than algorithmic code conversion— depends on the implementation September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Code Conversion Basics (Cont’d) dc • CJKV character set differences — Different number of characters — Different ordering of characters — Different characters September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Character Sets Versus Encodings dc • Common CJKV character set standards — China: GB 1988-89, GB 2312-80; GB 1988-89, GBK — Taiwan: ASCII, Big Five; CNS 5205-1989, CNS 11643-1992 — Hong Kong: ASCII, Big Five with Hong Kong extension — Japan: JIS X 0201-1997, JIS X 0208:1997, JIS X 0212-1990 — South Korea: KS X 1003:1993, KS X 1001:1992, KS X 1002:1991 — North Korea: ASCII (?), KPS 9566-97 — Vietnam: TCVN 5712:1993, TCVN 5773:1993, TCVN 6056:1995 • Common CJKV encodings — Locale-independent: EUC-*, ISO-2022-* — Locale-specific: GBK, Big Five, Big Five Plus, Shift-JIS, Johab, Unified Hangul Code — Other: UCS-2, UCS-4, UTF-7, UTF-8, -

San José, October 2, 2000 Feel Free to Distribute This Text
San José, October 2, 2000 Feel free to distribute this text (version 1.2) including the author’s email address ([email protected]) and to contact him for corrections and additions. Please do not take this text as a literal translation, but as a help to understand the standard GB 18030-2000. Insertions in brackets [] are used throughout the text to indicate corresponding sections of the published Chinese standard. Thanks to Markus Scherer (IBM) and Ken Lunde (Adobe Systems) for initial critical reviews of the text. SUMMARY, EXPLANATIONS, AND REMARKS: CHINESE NATIONAL STANDARD GB 18030-2000: INFORMATION TECHNOLOGY – CHINESE IDEOGRAMS CODED CHARACTER SET FOR INFORMATION INTERCHANGE – EXTENSION FOR THE BASIC SET (信息技术-信息交换用汉字编码字符集 Xinxi Jishu – Xinxi Jiaohuan Yong Hanzi Bianma Zifuji – Jibenji De Kuochong) March 17, 2000, was the publishing date of the Chinese national standard (国家标准 guojia biaozhun) GB 18030-2000 (hereafter: GBK2K). This standard tries to resolve issues resulting from the advent of Unicode, version 3.0. More specific, it attempts the combination of Uni- code's extended character repertoire, namely the Unihan Extension A, with the character cov- erage of earlier Chinese national standards. HISTORY The People’s Republic of China had already expressed her fundamental consent to support the combined efforts of the ISO/IEC and the Unicode Consortium through publishing a Chinese National Standard that was code- and character-compatible with ISO 10646-1/ Unicode 2.1. This standard was named GB 13000.1. Whenever the ISO and the Unicode Consortium changed or revised their “common” standard, GB 13000.1 adopted these changes subsequently. In order to remain compatible with GB 2312, however, which at the time of publishing Unicode/GB 13000.1 was an already existing national standard widely used to represent the Chinese “simplified” characters, the “specification” GBK was created. -
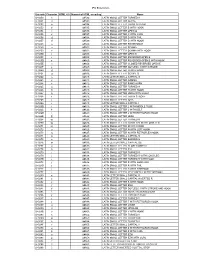
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with