Implementing Cross-Locale CJKV Code Conversion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Introduction 1
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Download the Specification
Internationalizing and Localizing Applications in Oracle Solaris Part No: E61053 November 2020 Internationalizing and Localizing Applications in Oracle Solaris Part No: E61053 Copyright © 2014, 2020, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial -

Man'yogana.Pdf (574.0Kb)
Bulletin of the School of Oriental and African Studies http://journals.cambridge.org/BSO Additional services for Bulletin of the School of Oriental and African Studies: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here The origin of man'yogana John R. BENTLEY Bulletin of the School of Oriental and African Studies / Volume 64 / Issue 01 / February 2001, pp 59 73 DOI: 10.1017/S0041977X01000040, Published online: 18 April 2001 Link to this article: http://journals.cambridge.org/abstract_S0041977X01000040 How to cite this article: John R. BENTLEY (2001). The origin of man'yogana. Bulletin of the School of Oriental and African Studies, 64, pp 5973 doi:10.1017/S0041977X01000040 Request Permissions : Click here Downloaded from http://journals.cambridge.org/BSO, IP address: 131.156.159.213 on 05 Mar 2013 The origin of man'yo:gana1 . Northern Illinois University 1. Introduction2 The origin of man'yo:gana, the phonetic writing system used by the Japanese who originally had no script, is shrouded in mystery and myth. There is even a tradition that prior to the importation of Chinese script, the Japanese had a native script of their own, known as jindai moji ( , age of the gods script). Christopher Seeley (1991: 3) suggests that by the late thirteenth century, Shoku nihongi, a compilation of various earlier commentaries on Nihon shoki (Japan's first official historical record, 720 ..), circulated the idea that Yamato3 had written script from the age of the gods, a mythical period when the deity Susanoo was believed by the Japanese court to have composed Japan's first poem, and the Sun goddess declared her son would rule the land below. -

Consonant Characters and Inherent Vowels
Global Design: Characters, Language, and More Richard Ishida W3C Internationalization Activity Lead Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 1 Getting more information W3C Internationalization Activity http://www.w3.org/International/ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 2 Outline Character encoding: What's that all about? Characters: What do I need to do? Characters: Using escapes Language: Two types of declaration Language: The new language tag values Text size Navigating to localized pages Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 3 Character encoding Character encoding: What's that all about? Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 4 Character encoding The Enigma Photo by David Blaikie Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 5 Character encoding Berber 4,000 BC Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 6 Character encoding Tifinagh http://www.dailymotion.com/video/x1rh6m_tifinagh_creation Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 7 Character encoding Character set Character set ⴰ ⴱ ⴲ ⴳ ⴴ ⴵ ⴶ ⴷ ⴸ ⴹ ⴺ ⴻ ⴼ ⴽ ⴾ ⴿ ⵀ ⵁ ⵂ ⵃ ⵄ ⵅ ⵆ ⵇ ⵈ ⵉ ⵊ ⵋ ⵌ ⵍ ⵎ ⵏ ⵐ ⵑ ⵒ ⵓ ⵔ ⵕ ⵖ ⵗ ⵘ ⵙ ⵚ ⵛ ⵜ ⵝ ⵞ ⵟ ⵠ ⵢ ⵣ ⵤ ⵥ ⵯ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 8 Character encoding Coded character set 0 1 2 3 0 1 Coded character set 2 3 4 5 6 7 8 9 33 (hexadecimal) A B 52 (decimal) C D E F Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 9 Character encoding Code pages ASCII Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 10 Character encoding Code pages ISO 8859-1 (Latin 1) Western Europe ç (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 11 Character encoding Code pages ISO 8859-7 Greek η (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 12 Character encoding Double-byte characters Standard Country No. -

SUPPORTING the CHINESE, JAPANESE, and KOREAN LANGUAGES in the OPENVMS OPERATING SYSTEM by Michael M. T. Yau ABSTRACT the Asian L
SUPPORTING THE CHINESE, JAPANESE, AND KOREAN LANGUAGES IN THE OPENVMS OPERATING SYSTEM By Michael M. T. Yau ABSTRACT The Asian language versions of the OpenVMS operating system allow Asian-speaking users to interact with the OpenVMS system in their native languages and provide a platform for developing Asian applications. Since the OpenVMS variants must be able to handle multibyte character sets, the requirements for the internal representation, input, and output differ considerably from those for the standard English version. A review of the Japanese, Chinese, and Korean writing systems and character set standards provides the context for a discussion of the features of the Asian OpenVMS variants. The localization approach adopted in developing these Asian variants was shaped by business and engineering constraints; issues related to this approach are presented. INTRODUCTION The OpenVMS operating system was designed in an era when English was the only language supported in computer systems. The Digital Command Language (DCL) commands and utilities, system help and message texts, run-time libraries and system services, and names of system objects such as file names and user names all assume English text encoded in the 7-bit American Standard Code for Information Interchange (ASCII) character set. As Digital's business began to expand into markets where common end users are non-English speaking, the requirement for the OpenVMS system to support languages other than English became inevitable. In contrast to the migration to support single-byte, 8-bit European characters, OpenVMS localization efforts to support the Asian languages, namely Japanese, Chinese, and Korean, must deal with a more complex issue, i.e., the handling of multibyte character sets. -

A Ruse Secluded Character Set for the Source
Mukt Shabd Journal Issn No : 2347-3150 A Ruse Secluded character set for the Source Mr. J Purna Prakash1, Assistant Professor Mr. M. Rama Raju 2, Assistant Professor Christu Jyothi Institute of Technology & Science Abstract We are rich in data, but information is poor, typically world wide web and data streams. The effective and efficient analysis of data in which is different forms becomes a challenging task. Searching for knowledge to match the exact keyword is big task in Internet such as search engine. Now a days using Unicode Transform Format (UTF) is extended to UTF-16 and UTF-32. With helps to create more special characters how we want. China has GB 18030-character set. Less number of website are using ASCII format in china, recently. While searching some keyword we are unable get the exact webpage in search engine in top place. Issues in certain we face this problem in results announcement, notifications, latest news, latest products released. Mainly on government websites are not shown in the front page. To avoid this trap from common people, we require special character set to match the exact unique keyword. Most of the keywords are encoded with the ASCII format. While searching keyword called cbse net results thousands of websites will have the common keyword as cbse net results. Matching the keyword, it is already encoded in all website as ASCII format. Most of the government websites will not offer search engine optimization. Match a unique keyword in government, banking, Institutes, Online exam purpose. Proposals is to create a character set from A to Z and a to z, for the purpose of data cleaning. -

PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437
PCL PC-8, Code Page 437 Page 1 of 5 PCL PC-8, Code Page 437 PCL Symbol Set: 10U Unicode glyph correspondence tables. Contact:[email protected] http://pcl.to -- -- -- -- $90 U00C9 Ê Uppercase e acute $21 U0021 Ë Exclamation $91 U00E6 Ì Lowercase ae diphthong $22 U0022 Í Neutral double quote $92 U00C6 Î Uppercase ae diphthong $23 U0023 Ï Number $93 U00F4 & Lowercase o circumflex $24 U0024 ' Dollar $94 U00F6 ( Lowercase o dieresis $25 U0025 ) Per cent $95 U00F2 * Lowercase o grave $26 U0026 + Ampersand $96 U00FB , Lowercase u circumflex $27 U0027 - Neutral single quote $97 U00F9 . Lowercase u grave $28 U0028 / Left parenthesis $98 U00FF 0 Lowercase y dieresis $29 U0029 1 Right parenthesis $99 U00D6 2 Uppercase o dieresis $2A U002A 3 Asterisk $9A U00DC 4 Uppercase u dieresis $2B U002B 5 Plus $9B U00A2 6 Cent sign $2C U002C 7 Comma, decimal separator $9C U00A3 8 Pound sterling $2D U002D 9 Hyphen $9D U00A5 : Yen sign $2E U002E ; Period, full stop $9E U20A7 < Pesetas $2F U002F = Solidus, slash $9F U0192 > Florin sign $30 U0030 ? Numeral zero $A0 U00E1 ê Lowercase a acute $31 U0031 A Numeral one $A1 U00ED B Lowercase i acute $32 U0032 C Numeral two $A2 U00F3 D Lowercase o acute $33 U0033 E Numeral three $A3 U00FA F Lowercase u acute $34 U0034 G Numeral four $A4 U00F1 H Lowercase n tilde $35 U0035 I Numeral five $A5 U00D1 J Uppercase n tilde $36 U0036 K Numeral six $A6 U00AA L Female ordinal (a) http://www.pclviewer.com (c) RedTitan Technology 2005 PCL PC-8, Code Page 437 Page 2 of 5 $37 U0037 M Numeral seven $A7 U00BA N Male ordinal (o) $38 U0038 -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -
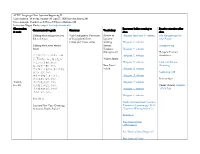
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding A
Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding Adobe-Symbol-Encoding csHPPSMath Adobe-Zapf-Dingbats-Encoding csZapfDingbats Arabic ISO-8859-6, csISOLatinArabic, iso-ir-127, ECMA-114, ASMO-708 ASCII US-ASCII, ANSI_X3.4-1968, iso-ir-6, ANSI_X3.4-1986, ISO646-US, us, IBM367, csASCI big-endian ISO-10646-UCS-2, BigEndian, 68k, PowerPC, Mac, Macintosh Big5 csBig5, cn-big5, x-x-big5 Big5Plus Big5+, csBig5Plus BMP ISO-10646-UCS-2, BMPstring CCSID-1027 csCCSID1027, IBM1027 CCSID-1047 csCCSID1047, IBM1047 CCSID-290 csCCSID290, CCSID290, IBM290 CCSID-300 csCCSID300, CCSID300, IBM300 CCSID-930 csCCSID930, CCSID930, IBM930 CCSID-935 csCCSID935, CCSID935, IBM935 CCSID-937 csCCSID937, CCSID937, IBM937 CCSID-939 csCCSID939, CCSID939, IBM939 CCSID-942 csCCSID942, CCSID942, IBM942 ChineseAutoDetect csChineseAutoDetect: Candidate encodings: GB2312, Big5, GB18030, UTF32:UTF8, UCS2, UTF32 EUC-H, csCNS11643EUC, EUC-TW, TW-EUC, H-EUC, CNS-11643-1992, EUC-H-1992, csCNS11643-1992-EUC, EUC-TW-1992, CNS-11643 TW-EUC-1992, H-EUC-1992 CNS-11643-1986 EUC-H-1986, csCNS11643_1986_EUC, EUC-TW-1986, TW-EUC-1986, H-EUC-1986 CP10000 csCP10000, windows-10000 CP10001 csCP10001, windows-10001 CP10002 csCP10002, windows-10002 CP10003 csCP10003, windows-10003 CP10004 csCP10004, windows-10004 CP10005 csCP10005, windows-10005 CP10006 csCP10006, windows-10006 CP10007 csCP10007, windows-10007 CP10008 csCP10008, windows-10008 CP10010 csCP10010, windows-10010 CP10017 csCP10017, windows-10017 CP10029 csCP10029, windows-10029 CP10079 csCP10079, windows-10079