Consonant Characters and Inherent Vowels
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

International Code Council 2009/2010 Code Development Cycle Proposed Changes to the 2009 Editions Of
INTERNATIONAL CODE COUNCIL 2009/2010 CODE DEVELOPMENT CYCLE PROPOSED CHANGES TO THE 2009 EDITIONS OF THE INTERNATIONAL BUILDING CODE® INTERNATIONAL ENERGY CONSERVATION CODE® INTERNATIONAL EXISTING BUILDING CODE® INTERNATIONAL FIRE CODE® INTERNATIONAL FUEL GAS CODE® INTERNATIONAL MECHANICAL CODE® INTERNATIONAL PLUMBING CODE® INTERNATIONAL PRIVATE SEWAGE DISPOSAL CODE® INTERNATIONAL PROPERTY MAINTENANCE CODE® INTERNATIONAL RESIDENTIAL CODE® INTERNATIONAL WILDLAND-URBAN INTERFACE CODE® ® INTERNATIONAL ZONING CODE October 24 2009 – November 11, 2009 Hilton Baltimore Baltimore, MD First Printing Publication Date: August 2009 Copyright © 2009 By International Code Council, Inc. ALL RIGHTS RESERVED. This 2009/2010 Code Development Cycle Proposed Changes to the 2009 International Codes is a copyrighted work owned by the International Code Council, Inc. Without advanced written permission from the copyright owner, no part of this book may be reproduced, distributed, or transmitted in any form or by any means, including, without limitations, electronic, optical or mechanical means (by way of example and not limitation, photocopying, or recording by or in an information storage retrieval system). For information on permission to copy material exceeding fair use, please contact: Publications, 4051 West Flossmoor Road, Country Club Hills, IL 60478 (Phone 1-888-422-7233). Trademarks: “International Code Council,” the “International Code Council” logo are trademarks of the International Code Council, Inc. PRINTED IN THE U.S.A. TABLE OF CONTENTS PAGE -

SUPPORTING the CHINESE, JAPANESE, and KOREAN LANGUAGES in the OPENVMS OPERATING SYSTEM by Michael M. T. Yau ABSTRACT the Asian L
SUPPORTING THE CHINESE, JAPANESE, AND KOREAN LANGUAGES IN THE OPENVMS OPERATING SYSTEM By Michael M. T. Yau ABSTRACT The Asian language versions of the OpenVMS operating system allow Asian-speaking users to interact with the OpenVMS system in their native languages and provide a platform for developing Asian applications. Since the OpenVMS variants must be able to handle multibyte character sets, the requirements for the internal representation, input, and output differ considerably from those for the standard English version. A review of the Japanese, Chinese, and Korean writing systems and character set standards provides the context for a discussion of the features of the Asian OpenVMS variants. The localization approach adopted in developing these Asian variants was shaped by business and engineering constraints; issues related to this approach are presented. INTRODUCTION The OpenVMS operating system was designed in an era when English was the only language supported in computer systems. The Digital Command Language (DCL) commands and utilities, system help and message texts, run-time libraries and system services, and names of system objects such as file names and user names all assume English text encoded in the 7-bit American Standard Code for Information Interchange (ASCII) character set. As Digital's business began to expand into markets where common end users are non-English speaking, the requirement for the OpenVMS system to support languages other than English became inevitable. In contrast to the migration to support single-byte, 8-bit European characters, OpenVMS localization efforts to support the Asian languages, namely Japanese, Chinese, and Korean, must deal with a more complex issue, i.e., the handling of multibyte character sets. -

Etsi En 300 468 V1.16.1 (2019-08)
ETSI EN 300 468 V1.16.1 (2019-08) EUROPEAN STANDARD Digital Video Broadcasting (DVB); Specification for Service Information (SI) in DVB systems 2 ETSI EN 300 468 V1.16.1 (2019-08) Reference REN/JTC-DVB-376 Keywords broadcasting, digital, DVB, MPEG, service, TV, video ETSI 650 Route des Lucioles F-06921 Sophia Antipolis Cedex - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 Important notice The present document can be downloaded from: http://www.etsi.org/standards-search The present document may be made available in electronic versions and/or in print. The content of any electronic and/or print versions of the present document shall not be modified without the prior written authorization of ETSI. In case of any existing or perceived difference in contents between such versions and/or in print, the prevailing version of an ETSI deliverable is the one made publicly available in PDF format at www.etsi.org/deliver. Users of the present document should be aware that the document may be subject to revision or change of status. Information on the current status of this and other ETSI documents is available at https://portal.etsi.org/TB/ETSIDeliverableStatus.aspx If you find errors in the present document, please send your comment to one of the following services: https://portal.etsi.org/People/CommiteeSupportStaff.aspx Copyright Notification No part may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm except as authorized by written permission of ETSI. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -
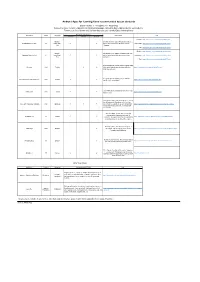
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Na Kana Magiti Kei Na Lotu
1 NA KANA MAGITI KEI NA LOTU (Vola Tabu : Maciu 22:1-10; Luke 14:12-24) Vola ko Rev. Dr. Ilaitia S. Tuwere. Sa inaki ni vunau oqo me taroga ka sauma talega na taro : A cava na Lotu? Ni da tekivu edaidai ena noda solevu vakalotu, sa na yaga meda taroga ka tovolea talega me sauma na taro oqori. Ia, ena levu na kena isau eda na solia, me vaka na: gumatuataki ni masu kei na vulici ni Vola Tabu, bula vakayalo, muria na ivakarau se lawa ni lotu ka vuqa tale. Na veika oqori era ka dina ka tu kina eso na isau ni taro : A Cava na Lotu. Na i Vola Tabu e sega ni tuvalaka vakavosa vei keda na ibalebale ni lotu. E vakavuqa me boroya vei keda na iyaloyalo me vakadewataka kina na veika eso e vinakata me tukuna. E sega talega ni solia e duabulu ga na iyaloyalo me baleta na lotu. E vuqa sara e solia vei keda. Oqori me vaka na Qele ni Sipi kei na i Vakatawa Vinaka; na Vuni Vaini kei na Tabana; na i Vakavuvuli kei iratou na nona Gonevuli se Tisaipeli, na Masima se Rarama kei Vuravura, na Ulu kei na Vo ni Yago taucoko, ka vuqa tale. Ena mataka edaidai, meda raica vata yani na iyaloyalo ni kana magiti. E rua na kena ivakamacala eda rogoca, mai na Kosipeli i Maciu kei na nei Luke. Na kana magiti se na solevu edua na ivakarau vakaitaukei. Eda soqoni vata kina vakaveiwekani ena noda veikidavaki kei na marau, kena veitalanoa, kena sere kei na meke, kena salusalu kei na kumuni iyau. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

The Not So Short Introduction to Latex2ε
The Not So Short Introduction to LATEX 2ε Or LATEX 2ε in 139 minutes by Tobias Oetiker Hubert Partl, Irene Hyna and Elisabeth Schlegl Version 4.20, May 31, 2006 ii Copyright ©1995-2005 Tobias Oetiker and Contributers. All rights reserved. This document is free; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this document; if not, write to the Free Software Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA. Thank you! Much of the material used in this introduction comes from an Austrian introduction to LATEX 2.09 written in German by: Hubert Partl <[email protected]> Zentraler Informatikdienst der Universität für Bodenkultur Wien Irene Hyna <[email protected]> Bundesministerium für Wissenschaft und Forschung Wien Elisabeth Schlegl <noemail> in Graz If you are interested in the German document, you can find a version updated for LATEX 2ε by Jörg Knappen at CTAN:/tex-archive/info/lshort/german iv Thank you! The following individuals helped with corrections, suggestions and material to improve this paper. They put in a big effort to help me get this document into its present shape. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding A
Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding Adobe-Symbol-Encoding csHPPSMath Adobe-Zapf-Dingbats-Encoding csZapfDingbats Arabic ISO-8859-6, csISOLatinArabic, iso-ir-127, ECMA-114, ASMO-708 ASCII US-ASCII, ANSI_X3.4-1968, iso-ir-6, ANSI_X3.4-1986, ISO646-US, us, IBM367, csASCI big-endian ISO-10646-UCS-2, BigEndian, 68k, PowerPC, Mac, Macintosh Big5 csBig5, cn-big5, x-x-big5 Big5Plus Big5+, csBig5Plus BMP ISO-10646-UCS-2, BMPstring CCSID-1027 csCCSID1027, IBM1027 CCSID-1047 csCCSID1047, IBM1047 CCSID-290 csCCSID290, CCSID290, IBM290 CCSID-300 csCCSID300, CCSID300, IBM300 CCSID-930 csCCSID930, CCSID930, IBM930 CCSID-935 csCCSID935, CCSID935, IBM935 CCSID-937 csCCSID937, CCSID937, IBM937 CCSID-939 csCCSID939, CCSID939, IBM939 CCSID-942 csCCSID942, CCSID942, IBM942 ChineseAutoDetect csChineseAutoDetect: Candidate encodings: GB2312, Big5, GB18030, UTF32:UTF8, UCS2, UTF32 EUC-H, csCNS11643EUC, EUC-TW, TW-EUC, H-EUC, CNS-11643-1992, EUC-H-1992, csCNS11643-1992-EUC, EUC-TW-1992, CNS-11643 TW-EUC-1992, H-EUC-1992 CNS-11643-1986 EUC-H-1986, csCNS11643_1986_EUC, EUC-TW-1986, TW-EUC-1986, H-EUC-1986 CP10000 csCP10000, windows-10000 CP10001 csCP10001, windows-10001 CP10002 csCP10002, windows-10002 CP10003 csCP10003, windows-10003 CP10004 csCP10004, windows-10004 CP10005 csCP10005, windows-10005 CP10006 csCP10006, windows-10006 CP10007 csCP10007, windows-10007 CP10008 csCP10008, windows-10008 CP10010 csCP10010, windows-10010 CP10017 csCP10017, windows-10017 CP10029 csCP10029, windows-10029 CP10079 csCP10079, windows-10079 -

Implementing Cross-Locale CJKV Code Conversion
Implementing Cross-Locale CJKV Code Conversion Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-paper.pdf ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-slides.pdf Code Conversion Basics dc • Algorithmic code conversion — Within a single locale: Shift-JIS, EUC-JP, and ISO-2022-JP — A purely mathematical process • Table-driven code conversion — Required across locales: Chinese ↔ Japanese — Required when dealing with Unicode — Mapping tables are required — Can sometimes be faster than algorithmic code conversion— depends on the implementation September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Code Conversion Basics (Cont’d) dc • CJKV character set differences — Different number of characters — Different ordering of characters — Different characters September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Character Sets Versus Encodings dc • Common CJKV character set standards — China: GB 1988-89, GB 2312-80; GB 1988-89, GBK — Taiwan: ASCII, Big Five; CNS 5205-1989, CNS 11643-1992 — Hong Kong: ASCII, Big Five with Hong Kong extension — Japan: JIS X 0201-1997, JIS X 0208:1997, JIS X 0212-1990 — South Korea: KS X 1003:1993, KS X 1001:1992, KS X 1002:1991 — North Korea: ASCII (?), KPS 9566-97 — Vietnam: TCVN 5712:1993, TCVN 5773:1993, TCVN 6056:1995 • Common CJKV encodings — Locale-independent: EUC-*, ISO-2022-* — Locale-specific: GBK, Big Five, Big Five Plus, Shift-JIS, Johab, Unified Hangul Code — Other: UCS-2, UCS-4, UTF-7, UTF-8,