Legacy Character Sets & Encodings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tugboat, Volume 11 (1990), No
TUGboat, Volume 11 (1990), No. 2 G.A. Kubba. The Impact of Computers on Ara- to Computer Modern fonts-I strongly support the bic Writing, Character Processing, and Teach- principal idea, and I pursue it in the present paper. ing. Information Processing, 80:961-965, 1980. To organize the discussion in a systematic way, I Pierre Mackay. Typesetting Problem Scripts. will use the notions - borrowed from [2]-of text Byte, 11(2):201-218, February 1986. encoding, typing and rendering. J. Marshall Unger. The Fiflh Generation 2 Text encoding Fallacy- Why Japan is Betting its Future on Artificial Intelligence. Oxford University Press, In the context of w,encoding means the character 1987. sets of the fonts in question and their layouts. In the present section I will focus my attention on the X/Open Company, Ltd. X/Open Portability character sets, as the layouts should be influenced, Guide, Supplementary Definitions, volume 3. among others, by typing considerations. Prentice-Hall. 1989. In an attempt to obtain a general idea about the use of the latin alphabet worldwide, I looked up the o Nelson H.F. Beebe only relevant reference work I am aware of, namely Center for Scientific Computing and Department of Languages Identificatzon Guzde [7] (hereafter LIG). Mathematics Apart from the latin scripts used in the Soviet Union South Physics Building and later replaced by Cyrillic ones, it lists 82 lan- University of Utah guages using the latin alphabet with additional let- Salt Lake City, UT 84112 ters (I preserve the original spelling): USA Albanian, Aymara, Basque. Breton, Bui, Tel: (801) 581-5254 Catalan, Choctaw, Chuana, Cree, Czech, Internet: BeebeQscience .utah.edu Danish, Delaware, Dutch, Eskimo, Espe- ranto, Estonian, Ewe, Faroese (also spelled Faroeish), Fiji, Finnish, French, Frisian, Fulbe, German, Guarani, Hausa, Hun- garian, Icelandic, Irish, Italian, Javanese, Juang, Kasubian, Kurdish, Lahu, Lahuli, - Latin, Lettish, Lingala, Lithuanian, Lisu, On Standards Luba, Madura. -

Edit Bibliographic Records
OCLC Connexion Browser Guides Edit Bibliographic Records Last updated: May 2014 6565 Kilgour Place, Dublin, OH 43017-3395 www.oclc.org Revision History Date Section title Description of changes May 2014 All Updated information on how to open the diacritic window. The shortcut key is no longer available. May 2006 1. Edit record: basics Minor updates. 5. Insert diacritics Revised to update list of bar syntax character codes to reflect and special changes in character names and to add newly supported characters characters. November 2006 1. Edit record: basics Minor updates. 2. Editing Added information on guided editing for fields 541 and 583, techniques, template commonly used when cataloging archival materials. view December 2006 1. Edit record: basics Updated to add information about display of WorldCat records that contain non-Latin scripts.. May 2007 4. Validate record Revised to document change in default validation level from None to Structure. February 2012 2 Editing techniques, Series added entry fields 800, 810, 811, 830 can now be used to template view insert data from a “cited” record for a related series item. Removed “and DDC” from Control All commands. DDC numbers are no longer controlled in Connexion. April 2012 2. Editing New section on how to use the prototype OCLC Classify service. techniques, template view September 2012 All Removed all references to Pathfinder. February 2013 All Removed all references to Heritage Printed Book. April 2013 All Removed all references to Chinese Name Authority © 2014 OCLC Online Computer Library Center, Inc. 6565 Kilgour Place Dublin, OH 43017-3395 USA The following OCLC product, service and business names are trademarks or service marks of OCLC, Inc.: CatExpress, Connexion, DDC, Dewey, Dewey Decimal Classification, OCLC, WorldCat, WorldCat Resource Sharing and “The world’s libraries. -

Consonant Characters and Inherent Vowels
Global Design: Characters, Language, and More Richard Ishida W3C Internationalization Activity Lead Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 1 Getting more information W3C Internationalization Activity http://www.w3.org/International/ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 2 Outline Character encoding: What's that all about? Characters: What do I need to do? Characters: Using escapes Language: Two types of declaration Language: The new language tag values Text size Navigating to localized pages Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 3 Character encoding Character encoding: What's that all about? Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 4 Character encoding The Enigma Photo by David Blaikie Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 5 Character encoding Berber 4,000 BC Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 6 Character encoding Tifinagh http://www.dailymotion.com/video/x1rh6m_tifinagh_creation Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 7 Character encoding Character set Character set ⴰ ⴱ ⴲ ⴳ ⴴ ⴵ ⴶ ⴷ ⴸ ⴹ ⴺ ⴻ ⴼ ⴽ ⴾ ⴿ ⵀ ⵁ ⵂ ⵃ ⵄ ⵅ ⵆ ⵇ ⵈ ⵉ ⵊ ⵋ ⵌ ⵍ ⵎ ⵏ ⵐ ⵑ ⵒ ⵓ ⵔ ⵕ ⵖ ⵗ ⵘ ⵙ ⵚ ⵛ ⵜ ⵝ ⵞ ⵟ ⵠ ⵢ ⵣ ⵤ ⵥ ⵯ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 8 Character encoding Coded character set 0 1 2 3 0 1 Coded character set 2 3 4 5 6 7 8 9 33 (hexadecimal) A B 52 (decimal) C D E F Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 9 Character encoding Code pages ASCII Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 10 Character encoding Code pages ISO 8859-1 (Latin 1) Western Europe ç (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 11 Character encoding Code pages ISO 8859-7 Greek η (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 12 Character encoding Double-byte characters Standard Country No. -

File Formats
man pages section 4: File Formats Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 817–3945–10 September 2004 Copyright 2004 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

SUPPORTING the CHINESE, JAPANESE, and KOREAN LANGUAGES in the OPENVMS OPERATING SYSTEM by Michael M. T. Yau ABSTRACT the Asian L
SUPPORTING THE CHINESE, JAPANESE, AND KOREAN LANGUAGES IN THE OPENVMS OPERATING SYSTEM By Michael M. T. Yau ABSTRACT The Asian language versions of the OpenVMS operating system allow Asian-speaking users to interact with the OpenVMS system in their native languages and provide a platform for developing Asian applications. Since the OpenVMS variants must be able to handle multibyte character sets, the requirements for the internal representation, input, and output differ considerably from those for the standard English version. A review of the Japanese, Chinese, and Korean writing systems and character set standards provides the context for a discussion of the features of the Asian OpenVMS variants. The localization approach adopted in developing these Asian variants was shaped by business and engineering constraints; issues related to this approach are presented. INTRODUCTION The OpenVMS operating system was designed in an era when English was the only language supported in computer systems. The Digital Command Language (DCL) commands and utilities, system help and message texts, run-time libraries and system services, and names of system objects such as file names and user names all assume English text encoded in the 7-bit American Standard Code for Information Interchange (ASCII) character set. As Digital's business began to expand into markets where common end users are non-English speaking, the requirement for the OpenVMS system to support languages other than English became inevitable. In contrast to the migration to support single-byte, 8-bit European characters, OpenVMS localization efforts to support the Asian languages, namely Japanese, Chinese, and Korean, must deal with a more complex issue, i.e., the handling of multibyte character sets. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

DDS for Printer Files
IBM i 7.2 Programming DDS for printer files IBM Note Before using this information and the product it supports, read the information in “Notices” on page 149. This edition applies to IBM i 7.2 (product number 5770-SS1) and to all subsequent releases and modifications until otherwise indicated in new editions. This version does not run on all reduced instruction set computer (RISC) models nor does it run on CISC models. This document may contain references to Licensed Internal Code. Licensed Internal Code is Machine Code and is licensed to you under the terms of the IBM License Agreement for Machine Code. © Copyright International Business Machines Corporation 2001, 2013. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents DDS for printer files............................................................................................... 1 What's new for IBM i 7.2..............................................................................................................................1 PDF file for DDS for printer files...................................................................................................................1 Defining a printer file....................................................................................................................................2 Conventions and terminology for DDS information............................................................................... 3 Positional entries for printer files (positions -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -
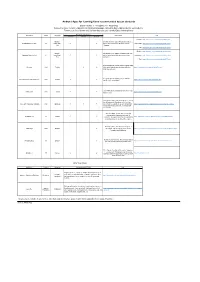
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Machine Transliteration (Knight & Graehl, ACL
Machine Transliteration (Knight & Graehl, ACL 97) Kevin Duh UW Machine Translation Reading Group, 11/30/2005 Transliteration & Back-transliteration • Transliteration: • Translating proper names, technical terms, etc. based on phonetic equivalents • Complicated for language pairs with different alphabets & sound inventories • E.g. “computer” --> “konpyuutaa” 䜷䝷䝗䝩䜪䝃䞀 • Back-transliteration • E.g. “konpyuuta” --> “computer” • Inversion of a lossy process Japanese/English Examples • Some notes about Japanese: • Katakana phonetic system for foreign names/loan words • Syllabary writing: • e.g. one symbol for “ga”䚭䜰, one for “gi”䚭䜲 • Consonant-vowel (CV) structure • Less distinction of L/R and H/F sounds • Examples: • Golfbag --> goruhubaggu 䜸䝯䝙䝔䝇䜴 • New York Times --> nyuuyooku taimuzu䚭䝏䝩䞀䝬䞀䜳䚭䝃䜨䝤䜾 • Ice cream --> aisukuriimu 䜦䜨䜽䜳䝮䞀䝤 The Challenge of Machine Back-transliteration • Back-transliteration is an important component for MT systems • For J/E: Katakana phrases are the largest source of phrases that do not appear in bilingual dictionary or training corpora • Claims: • Back-transliteration is less forgiving than transliteration • Back-transliteration is harder than romanization • For J/E, not all katakana phrases can be “sounded out” by back-transliteration • word processing --> waapuro • personal computer --> pasokon Modular WSA and WFSTs • P(w) - generates English words • P(e|w) - English words to English pronounciation • P(j|e) - English to Japanese sound conversion • P(k|j) - Japanese sound to katakana • P(o|k) - katakana to OCR • Given a katana string observed by OCR, find the English word sequence w that maximizes !!!P(w)P(e | w)P( j | e)P(k | j)P(o | k) e j k Two Potential Solutions • Learn from bilingual dictionaries, then generalize • Pro: Simple supervised learning problem • Con: finding direct correspondence between English alphabets and Japanese katakana may be too tenuous • Build a generative model of transliteration, then invert (Knight & Graehl’s approach): 1. -

14 * (Asterisk), 169 \ (Backslash) in Smb.Conf File, 85
,sambaIX.fm.28352 Page 385 Friday, November 19, 1999 3:40 PM Index <> (angled brackets), 14 archive files, 137 * (asterisk), 169 authentication, 19, 164–171 \ (backslash) in smb.conf file, 85 mechanisms for, 35 \\ (backslashes, two) in directories, 5 NT domain, 170 : (colon), 6 share-level option for, 192 \ (continuation character), 85 auto services option, 124 . (dot), 128, 134 automounter, support for, 35 # (hash mark), 85 awk script, 176 % (percent sign), 86 . (period), 128 B ? (question mark), 135 backup browsers ; (semicolon), 85 local master browser, 22 / (slash character), 129, 134–135 per local master browser, 23 / (slash) in shares, 116 maximum number per workgroup, 22 _ (underscore) 116 backup domain controllers (BDCs), 20 * wildcard, 177 backups, with smbtar program, 245–248 backwards compatibility elections and, 23 for filenames, 143 A Windows domains and, 20 access-control options (shares), 160–162 base directory, 40 accessing Samba server, 61 .BAT scripts, 192 accounts, 51–53 BDCs (backup domain controllers), 20 active connections, option for, 244 binary vs. source files, 32 addresses, networking option for, 106 bind interfaces only option, 106 addtosmbpass executable, 176 bindings, 71 admin users option, 161 Bindings tab, 60 AFS files, support for, 35 blocking locks option, 152 aliases b-node, 13 multiple, 29 boolean type, 90 for NetBIOS names, 107 bottlenecks, 320–328 alid users option, 161 reducing, 321–326 announce as option, 123 types of, 320 announce version option, 123 broadcast addresses, troubleshooting, 289 API -

KANA Response Live Organization Administration Tool Guide
This is the most recent version of this document provided by KANA Software, Inc. to Genesys, for the version of the KANA software products licensed for use with the Genesys eServices (Multimedia) products. Click here to access this document. KANA Response Live Organization Administration KANA Response Live Version 10 R2 February 2008 KANA Response Live Organization Administration All contents of this documentation are the property of KANA Software, Inc. (“KANA”) (and if relevant its third party licensors) and protected by United States and international copyright laws. All Rights Reserved. © 2008 KANA Software, Inc. Terms of Use: This software and documentation are provided solely pursuant to the terms of a license agreement between the user and KANA (the “Agreement”) and any use in violation of, or not pursuant to any such Agreement shall be deemed copyright infringement and a violation of KANA's rights in the software and documentation and the user consents to KANA's obtaining of injunctive relief precluding any further such use. KANA assumes no responsibility for any damage that may occur either directly or indirectly, or any consequential damages that may result from the use of this documentation or any KANA software product except as expressly provided in the Agreement, any use hereunder is on an as-is basis, without warranty of any kind, including without limitation the warranties of merchantability, fitness for a particular purpose, and non-infringement. Use, duplication, or disclosure by licensee of any materials provided by KANA is subject to restrictions as set forth in the Agreement. Information contained in this document is subject to change without notice and does not represent a commitment on the part of KANA.