Machine Transliteration (Knight & Graehl, ACL
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -
Android Apps for Learning Kana Recommended by Our Students
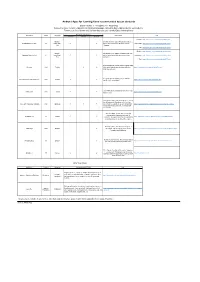
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

KANA Response Live Organization Administration Tool Guide
This is the most recent version of this document provided by KANA Software, Inc. to Genesys, for the version of the KANA software products licensed for use with the Genesys eServices (Multimedia) products. Click here to access this document. KANA Response Live Organization Administration KANA Response Live Version 10 R2 February 2008 KANA Response Live Organization Administration All contents of this documentation are the property of KANA Software, Inc. (“KANA”) (and if relevant its third party licensors) and protected by United States and international copyright laws. All Rights Reserved. © 2008 KANA Software, Inc. Terms of Use: This software and documentation are provided solely pursuant to the terms of a license agreement between the user and KANA (the “Agreement”) and any use in violation of, or not pursuant to any such Agreement shall be deemed copyright infringement and a violation of KANA's rights in the software and documentation and the user consents to KANA's obtaining of injunctive relief precluding any further such use. KANA assumes no responsibility for any damage that may occur either directly or indirectly, or any consequential damages that may result from the use of this documentation or any KANA software product except as expressly provided in the Agreement, any use hereunder is on an as-is basis, without warranty of any kind, including without limitation the warranties of merchantability, fitness for a particular purpose, and non-infringement. Use, duplication, or disclosure by licensee of any materials provided by KANA is subject to restrictions as set forth in the Agreement. Information contained in this document is subject to change without notice and does not represent a commitment on the part of KANA. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Implementing Cross-Locale CJKV Code Conversion
Implementing Cross-Locale CJKV Code Conversion Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-paper.pdf ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-slides.pdf Code Conversion Basics dc • Algorithmic code conversion — Within a single locale: Shift-JIS, EUC-JP, and ISO-2022-JP — A purely mathematical process • Table-driven code conversion — Required across locales: Chinese ↔ Japanese — Required when dealing with Unicode — Mapping tables are required — Can sometimes be faster than algorithmic code conversion— depends on the implementation September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Code Conversion Basics (Cont’d) dc • CJKV character set differences — Different number of characters — Different ordering of characters — Different characters September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Character Sets Versus Encodings dc • Common CJKV character set standards — China: GB 1988-89, GB 2312-80; GB 1988-89, GBK — Taiwan: ASCII, Big Five; CNS 5205-1989, CNS 11643-1992 — Hong Kong: ASCII, Big Five with Hong Kong extension — Japan: JIS X 0201-1997, JIS X 0208:1997, JIS X 0212-1990 — South Korea: KS X 1003:1993, KS X 1001:1992, KS X 1002:1991 — North Korea: ASCII (?), KPS 9566-97 — Vietnam: TCVN 5712:1993, TCVN 5773:1993, TCVN 6056:1995 • Common CJKV encodings — Locale-independent: EUC-*, ISO-2022-* — Locale-specific: GBK, Big Five, Big Five Plus, Shift-JIS, Johab, Unified Hangul Code — Other: UCS-2, UCS-4, UTF-7, UTF-8, -

Redalyc.Kanji and Kana Agraphia in Mild Cognitive Impairment And
Dementia & Neuropsychologia ISSN: 1980-5764 [email protected] Associação Neurologia Cognitiva e do Comportamento Brasil Akanuma, Kyoko; Meguro, Kenichi; Meguro, Mitsue; Sato Chubaci, Rosa Yuka; Caramelli, Paulo; Nitrini, Ricardo Kanji and Kana agraphia in mild cognitive impairment and dementia. A trans-cultural comparison of elderly Japanese subjects living in Japan and Brazil Dementia & Neuropsychologia, vol. 4, núm. 4, octubre-diciembre, 2010, pp. 300-305 Associação Neurologia Cognitiva e do Comportamento São Paulo, Brasil Available in: http://www.redalyc.org/articulo.oa?id=339529019008 How to cite Complete issue Scientific Information System More information about this article Network of Scientific Journals from Latin America, the Caribbean, Spain and Portugal Journal's homepage in redalyc.org Non-profit academic project, developed under the open access initiative Dement Neuropsychol 2010 December;4(4):300-305 Original Article Kanji and Kana agraphia in mild cognitive impairment and dementia A trans-cultural comparison of elderly Japanese subjects living in Japan and Brazil Kyoko Akanuma1, Kenichi Meguro1, Mitsue Meguro1, Rosa Yuka Sato Chubaci2, Paulo Caramelli3, Ricardo Nitrini4 Abstract – This study verifies the environmental effects on agraphia in mild cognitive impairment and dementia. We compared elderly Japanese subjects living in Japan and Brazil. Methods: We retrospectively analyzed the database of the Prevalence Study 1998 in Tajiri (n=497, Miyagi, Japan) and the Prevalence Study 1997 of elderly Japanese immigrants living in Brazil (n=166, migrated from Japan and living in the São Paulo Metropolitan Area). In three Clinical Dementia Rating (CDR) groups, i.e., CDR 0 (healthy), CDR 0.5 (questionable dementia), and CDR 1+ (dementia) , the Mini-Mental State Examination (MMSE) item of spontaneous writing and the Cognitive Abilities Screening Instrument (CASI) domain of dictation were analyzed with regard to the number of Kanji and Kana characters. -

JFP Reference Manual 5 : Standards, Environments, and Macros
JFP Reference Manual 5 : Standards, Environments, and Macros Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 817–0648–10 December 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

Introduction to the Special Issue on Japanese Geminate Obstruents
J East Asian Linguist (2013) 22:303-306 DOI 10.1007/s10831-013-9109-z Introduction to the special issue on Japanese geminate obstruents Haruo Kubozono Received: 8 January 2013 / Accepted: 22 January 2013 / Published online: 6 July 2013 © Springer Science+Business Media Dordrecht 2013 Geminate obstruents (GOs) and so-called unaccented words are the two properties most characteristic of Japanese phonology and the two features that are most difficult to learn for foreign learners of Japanese, regardless of their native language. This special issue deals with the first of these features, discussing what makes GOs so difficult to master, what is so special about them, and what makes the research thereon so interesting. GOs are one of the two types of geminate consonant in Japanese1 which roughly corresponds to what is called ‘sokuon’ (促音). ‘Sokon’ is defined as a ‘one-mora- long silence’ (Sanseido Daijirin Dictionary), often symbolized as /Q/ in Japanese linguistics, and is transcribed with a small letter corresponding to /tu/ (っ or ッ)in Japanese orthography. Its presence or absence is distinctive in Japanese phonology as exemplified by many pairs of words, including the following (dots /. / indicate syllable boundaries). (1) sa.ki ‘point’ vs. sak.ki ‘a short time ago’ ka.ko ‘past’ vs. kak.ko ‘paranthesis’ ba.gu ‘bug (in computer)’ vs. bag.gu ‘bag’ ka.ta ‘type’ vs. kat.ta ‘bought (past tense of ‘buy’)’ to.sa ‘Tosa (place name)’ vs. tos.sa ‘in an instant’ More importantly, ‘sokuon’ is an important characteristic of Japanese speech rhythm known as mora-timing. It is one of the four elements that can form a mora 1 The other type of geminate consonant is geminate nasals, which phonologically consist of a coda nasal and the nasal onset of the following syllable, e.g., /am. -

Addendum 135-2008K-1
ANSI/ASHRAE Addendum k to ANSI/ASHRAE Standard 135-2008 ASHRAEASHRAE STANDARDSTANDARD BACnet®—A Data Communication Protocol for Building Automation and Control Networks Approved by the ASHRAE Standards Committee on January 23, 2010; by the ASHRAE Board of Directors on January 27, 2010; and by the American National Standards Institute on January 28, 2010. This standard is under continuous maintenance by a Standing Standard Project Committee (SSPC) for which the Standards Committee has established a documented program for regular publication of addenda or revi- sions, including procedures for timely, documented, consensus action on requests for change to any part of the standard. The change submittal form, instructions, and deadlines may be obtained in electronic form from the ASHRAE Web site, http://www.ashrae.org, or in paper form from the Manager of Standards. The latest edi- tion of an ASHRAE Standard may be purchased from ASHRAE Customer Service, 1791 Tullie Circle, NE, Atlanta, GA 30329-2305. E-mail: [email protected]. Fax: 404-321-5478. Telephone: 404-636-8400 (world- wide), or toll free 1-800-527-4723 (for orders in US and Canada). © Copyright 2010 American Society of Heating, Refrigerating and Air-Conditioning Engineers, Inc. ISSN 1041-2336 American Society of Heating, Refrigerating and Air-Conditioning Engineers, Inc. 1791 Tullie Circle NE, Atlanta, GA 30329 www.ashrae.org ASHRAE Standing Standard Project Committee 135 Cognizant TC: TC 1.4, Control Theory and Application SPLS Liaison: Douglas T. Reindl David Robin, Chair* Coleman L. Brumley, Jr.* John J. Lynch Carl Neilson, Vice-Chair Bernhard Isler* Ted Sunderland Sharon E. Dinges, Secretary* Stephen Karg* David B. -

Table of Hiragana Letters Pdf
Table of hiragana letters pdf Continue Hiragana is one of three sets of characters used in Japanese. Each letter of Hiragana is a special syllable. The letter itself doesn't make sense. Hiragan is widely used to form a sentence. You can download/print the Hiragan chart (PDF) of all Hiragana's letters. The origin of Hiragan あ か た ま や the original 安 加 太 末 也 of Hiragan was developed in the 8th-10th century by simplifying the shape of specific kanji symbols. Compared to Katakana, Hiragana's letters have more curved lines. Number of letters In modern Japanese 46 basic letters of Hiragana. In addition to these 46 main letters, called gojon, there are modified forms to describe more time - 20 dakun, 5 handakuon, 36 y'on, 1 sokuon and 6 additional letters. Frequently asked questions: What are the letters with the bar on top ( Yap.) ? Gojaon 【五⼗⾳】 Goyon-【五⼗⾳図】 In Japanese, syllables are organized as a table (5 x 10). This table is called goj'on-zu (literally means a table of 50 sounds). The alphabets of Hiragan and Katakana are used to describe these sounds. Letters い, う and え appear more than once in the table. These 5 duplicates (grey) are usually missed or ignored. It includes ん syllable. It does not belong to any row or column. In total, 46 letters (45'1) are considered goj'on (50 sounds). You can learn the goj'on letters on the Hiragan course: Part 1-10. The structure of table First row - あ, い, う, え and お - five vowels of Japanese. -

Sveučilište Josipa Jurja Strossmayera U Osijeku Filozofski Fakultet U Osijeku Odsjek Za Engleski Jezik I Književnost Uroš Ba
CORE Metadata, citation and similar papers at core.ac.uk Provided by Croatian Digital Thesis Repository Sveučilište Josipa Jurja Strossmayera u Osijeku Filozofski fakultet u Osijeku Odsjek za engleski jezik i književnost Uroš Barjaktarević Japanese-English Language Contact / Japansko-engleski jezični kontakt Diplomski rad Kolegij: Engleski jezik u kontaktu Mentor: doc. dr. sc. Dubravka Vidaković Erdeljić Osijek, 2015. 1 Summary JAPANESE-ENGLISH LANGUAGE CONTACT The paper examines the language contact between Japanese and English. The first section of the paper defines language contact and the most common contact-induced language phenomena with an emphasis on linguistic borrowing as the dominant contact-induced phenomenon. The classification of linguistic borrowing thereby follows Haugen's distinction between morphemic importation and substitution. The second section of the paper presents the features of the Japanese language in terms of origin, phonology, syntax, morphology, and writing. The third section looks at the history of language contact of the Japanese with the Europeans, starting with the Portuguese and Spaniards, followed by the Dutch, and finally the English. The same section examines three different borrowing routes from English, and contact-induced language phenomena other than linguistic borrowing – bilingualism , code alternation, code-switching, negotiation, and language shift – present in Japanese-English language contact to varying degrees. This section also includes a survey of the motivation and reasons for borrowing from English, as well as the attitudes of native Japanese speakers to these borrowings. The fourth and the central section of the paper looks at the phenomenon of linguistic borrowing, its scope and the various adaptations that occur upon morphemic importation on the phonological, morphological, orthographic, semantic and syntactic levels.