Katakana Range: 30A0–30FF
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SUPPORTING the CHINESE, JAPANESE, and KOREAN LANGUAGES in the OPENVMS OPERATING SYSTEM by Michael M. T. Yau ABSTRACT the Asian L
SUPPORTING THE CHINESE, JAPANESE, AND KOREAN LANGUAGES IN THE OPENVMS OPERATING SYSTEM By Michael M. T. Yau ABSTRACT The Asian language versions of the OpenVMS operating system allow Asian-speaking users to interact with the OpenVMS system in their native languages and provide a platform for developing Asian applications. Since the OpenVMS variants must be able to handle multibyte character sets, the requirements for the internal representation, input, and output differ considerably from those for the standard English version. A review of the Japanese, Chinese, and Korean writing systems and character set standards provides the context for a discussion of the features of the Asian OpenVMS variants. The localization approach adopted in developing these Asian variants was shaped by business and engineering constraints; issues related to this approach are presented. INTRODUCTION The OpenVMS operating system was designed in an era when English was the only language supported in computer systems. The Digital Command Language (DCL) commands and utilities, system help and message texts, run-time libraries and system services, and names of system objects such as file names and user names all assume English text encoded in the 7-bit American Standard Code for Information Interchange (ASCII) character set. As Digital's business began to expand into markets where common end users are non-English speaking, the requirement for the OpenVMS system to support languages other than English became inevitable. In contrast to the migration to support single-byte, 8-bit European characters, OpenVMS localization efforts to support the Asian languages, namely Japanese, Chinese, and Korean, must deal with a more complex issue, i.e., the handling of multibyte character sets. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Hiragana Chart
ひらがな Hiragana Chart W R Y M H N T S K VOWEL ん わ ら や ま は な た さ か あ A り み ひ に ち し き い I る ゆ む ふ ぬ つ す く う U れ め へ ね て せ け え E を ろ よ も ほ の と そ こ お O © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 1 Beginning Japanese 名前: ________________________ 1-1 Hiragana Activity Book 日付: ___月 ___日 一、 Practice: あいうえお かきくけこ がぎぐげご O E U I A お え う い あ あ お え う い あ お う あ え い あ お え う い お う い あ お え あ KO KE KU KI KA こ け く き か か こ け く き か こ け く く き か か こ き き か こ こ け か け く く き き こ け か © 2010 Michael L. Kluemper et al. Beginning Japanese, Tuttle Publishing, an imprint of Periplus Editions (HK) Ltd. All rights reserved. www.TimeForJapanese.com. 2 GO GE GU GI GA ご げ ぐ ぎ が が ご げ ぐ ぎ が ご ご げ ぐ ぐ ぎ ぎ が が ご げ ぎ が ご ご げ が げ ぐ ぐ ぎ ぎ ご げ が 二、 Fill in each blank with the correct HIRAGANA. SE N SE I KI A RA NA MA E 1. -

Automatic Labeling of Voiced Consonants for Morphological Analysis of Modern Japanese Literature
Automatic Labeling of Voiced Consonants for Morphological Analysis of Modern Japanese Literature Teruaki Oka† Mamoru Komachi† [email protected] [email protected] Toshinobu Ogiso‡ Yuji Matsumoto† [email protected] [email protected] Nara Institute of Science and Technology National† Institute for Japanese Language and Linguistics ‡ Abstract literary text,2 which achieves high performance on analysis for existing electronic text (e.g. Aozora- Since the present-day Japanese use of bunko, an online digital library of freely available voiced consonant mark had established books and work mainly from out-of-copyright ma- in the Meiji Era, modern Japanese lit- terials). erary text written in the Meiji Era of- However, the performance of morphological an- ten lacks compulsory voiced consonant alyzers using the dictionary deteriorates if the text marks. This deteriorates the performance is not normalized, because these dictionaries often of morphological analyzers using ordi- lack orthographic variations such as Okuri-gana,3 nary dictionary. In this paper, we pro- accompanying characters following Kanji stems pose an approach for automatic labeling of in Japanese written words. This is problematic voiced consonant marks for modern liter- because not all historical texts are manually cor- ary Japanese. We formulate the task into a rected with orthography, and it is time-consuming binary classification problem. Our point- to annotate by hand. It is one of the major issues wise prediction method uses as its feature in applying NLP tools to Japanese Linguistics be- set only surface information about the sur- cause ancient materials often contain a wide vari- rounding character strings. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -
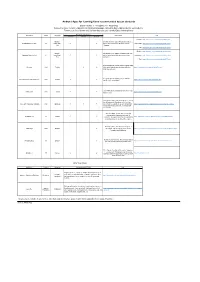
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Machine Transliteration (Knight & Graehl, ACL
Machine Transliteration (Knight & Graehl, ACL 97) Kevin Duh UW Machine Translation Reading Group, 11/30/2005 Transliteration & Back-transliteration • Transliteration: • Translating proper names, technical terms, etc. based on phonetic equivalents • Complicated for language pairs with different alphabets & sound inventories • E.g. “computer” --> “konpyuutaa” 䜷䝷䝗䝩䜪䝃䞀 • Back-transliteration • E.g. “konpyuuta” --> “computer” • Inversion of a lossy process Japanese/English Examples • Some notes about Japanese: • Katakana phonetic system for foreign names/loan words • Syllabary writing: • e.g. one symbol for “ga”䚭䜰, one for “gi”䚭䜲 • Consonant-vowel (CV) structure • Less distinction of L/R and H/F sounds • Examples: • Golfbag --> goruhubaggu 䜸䝯䝙䝔䝇䜴 • New York Times --> nyuuyooku taimuzu䚭䝏䝩䞀䝬䞀䜳䚭䝃䜨䝤䜾 • Ice cream --> aisukuriimu 䜦䜨䜽䜳䝮䞀䝤 The Challenge of Machine Back-transliteration • Back-transliteration is an important component for MT systems • For J/E: Katakana phrases are the largest source of phrases that do not appear in bilingual dictionary or training corpora • Claims: • Back-transliteration is less forgiving than transliteration • Back-transliteration is harder than romanization • For J/E, not all katakana phrases can be “sounded out” by back-transliteration • word processing --> waapuro • personal computer --> pasokon Modular WSA and WFSTs • P(w) - generates English words • P(e|w) - English words to English pronounciation • P(j|e) - English to Japanese sound conversion • P(k|j) - Japanese sound to katakana • P(o|k) - katakana to OCR • Given a katana string observed by OCR, find the English word sequence w that maximizes !!!P(w)P(e | w)P( j | e)P(k | j)P(o | k) e j k Two Potential Solutions • Learn from bilingual dictionaries, then generalize • Pro: Simple supervised learning problem • Con: finding direct correspondence between English alphabets and Japanese katakana may be too tenuous • Build a generative model of transliteration, then invert (Knight & Graehl’s approach): 1. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Characteristics of Developmental Dyslexia in Japanese Kana: From
al Ab gic no lo rm o a h l i c t y i e s s Ogawa et al., J Psychol Abnorm Child 2014, 3:3 P i Journal of Psychological Abnormalities n f o C l DOI: 10.4172/2329-9525.1000126 h a i n l d ISSN:r 2329-9525 r u e o n J in Children Research Article Open Access Characteristics of Developmental Dyslexia in Japanese Kana: from the Viewpoint of the Japanese Feature Shino Ogawa1*, Miwa Fukushima-Murata2, Namiko Kubo-Kawai3, Tomoko Asai4, Hiroko Taniai5 and Nobuo Masataka6 1Graduate School of Medicine, Kyoto University, Kyoto, Japan 2Research Center for Advanced Science and Technology, the University of Tokyo, Tokyo, Japan 3Faculty of Psychology, Aichi Shukutoku University, Aichi, Japan 4Nagoya City Child Welfare Center, Aichi, Japan 5Department of Pediatrics, Nagoya Central Care Center for Disabled Children, Aichi, Japan 6Section of Cognition and Learning, Primate Research Institute, Kyoto University, Aichi, Japan Abstract This study identified the individual differences in the effects of Japanese Dyslexia. The participants consisted of 12 Japanese children who had difficulties in reading and writing Japanese and were suspected of having developmental disorders. A test battery was created on the basis of the characteristics of the Japanese language to examine Kana’s orthography-to-phonology mapping and target four cognitive skills: analysis of phonological structure, letter-to-sound conversion, visual information processing, and eye–hand coordination. An examination of the individual ability levels for these four elements revealed that reading and writing difficulties are not caused by a single disability, but by a combination of factors. -

Does Romaji Help Beginners Learn More Words?
Yoshiko Okuyama 355 CALL Vocabulary Learning in Japanese: Does Romaji Help Beginners Learn More Words? YOSHIKO OKUYAMA University of Hawaii at Hilo ABSTRACT This study investigated the effects of using Romanized spellings on beginner- level Japanese vocabulary learning. Sixty-one first-semester students at two uni- versities in Arizona were both taught and tested on 40 Japanese content words in a computer-assisted language learning (CALL) program. The primary goal of the study was to examine whether the use of Romaji—Roman alphabetic spellings of Japanese—facilitates Japanese beginners’ learning of the L2 vocabulary. The study also investigated whether certain CALL strategies positively correlate with a greater gain in L2 vocabulary. Vocabulary items were presented to students in both experimental and control groups. The items included Hiragana spellings, colored illustrations for meaning, and audio recordings for pronunciation. Only the experimental group was given the extra assistance of Romaji. The scores of the vocabulary pretests and posttests, the types of online learning strategies and questionnaire responses were collected for statistical analyses. The results of the project indicated that the use of Romaji did not facilitate the beginners’ L2 vocabulary intake. However, the more intensive use of audio recordings was found to be strongly related to a higher number of words recalled, regardless of the presence or absence of Romaji. KEYWORDS CALL, Vocabulary Learning, Japanese as a Foreign Language (JFL), Romaji Script, CALL Strategies INTRODUCTION Learning a second language (L2) requires the acquisition of its lexicon. How do American college students learn basic L2 vocabulary in a CALL program? If the vocabulary is written in a nonalphabetic L2 script, such as Japanese, is it more efficient to learn the words with the assistance of more familiar Roman-alphabetic symbols? This experimental study explored these questions in the context of Japa- nese CALL vocabulary learning.