Addendum 135-2008K-1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Migration 13 CHS
Tudun mun tsira: Shiga ciyawa DEUTSCHE WELLE JI KA ƘARU Tudun mun tsira – Mai bayani a kan ’yan Afirka da ke yin ƙaura zuwa Turai Kashi na goma sha uku: Shiga ciyawa Wadda ta rubuta: Chrispin Mwakideu Wanda ya fassara: Ɗanlami Bala Gwammaja Wadda ta tace: Halima C. Schmaling ’Yan Wasa: Magaji: ɗan shekara 22 Jami’in shige da fice: ɗan shekara 40 Lami: ’yar shekara 20 Sa’adatu: ’yar shekara 35 Charles: ɗan shekara 45 Ɗan sanda: ɗan shekara 35 Faisal: ɗan shekara 19 Roda: ’yar shekara 25 1/9 Tudun mun tsira: Shiga ciyawa Mai gabatarwa: Masu saurarenmu, barkanmu da sake saduwa a cikin shirinmu na “Ji Ka Ƙaru”. Wannan shi ne kashi na goma sha uku a shirinmu na wasan kwaikwayo a kan ƙaura da matasa daga Afirka ke yi zuwa Turai, mai taken “Tudun mun tsira”. Idan ba mu manta ba, wannan wasa ne a kan rayuwar waɗansu matasa, wato Lami, da Faisal, da kuma Magaji. Mun ji kuma cewa ko da yake akwai damammakin karatu da kuma ci gaban ɗan Adam a Turai, akwai kuma waɗansu abubuwan ƙi, musamman ma dai idan mutum ba bisa ƙa’ida ya shiga Turai ɗin ba. Sai ku biyo mu cikin shirin namu na yau mai taken “Shiga ciyawa” don jin yadda za ta kasance. Yanzu dai ga mu a ofishin jami’an shige da fice a lokacin da suke ganawa da Magaji. Fitowa ta 1: Magaji yana yi wa jami’in shige da fice bayani Jami’in shige da fice: Wato dai kai ne sabon akarambanar da muka samu ko? Magaji: Akarambana? Ban gane ba, Yallaɓai, me kake nufi da haka? Jami’i: To, ba ga shi ka kurɗaɗo ta cikin jirgin da muke ta fama jigilar kai abinci Afirka ba don ya kawo ka Turai? Ni na kwana biyu ma ban ga abin mamaki irin haka ba, sai kai. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -
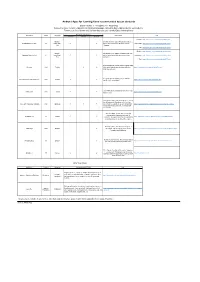
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Machine Transliteration (Knight & Graehl, ACL
Machine Transliteration (Knight & Graehl, ACL 97) Kevin Duh UW Machine Translation Reading Group, 11/30/2005 Transliteration & Back-transliteration • Transliteration: • Translating proper names, technical terms, etc. based on phonetic equivalents • Complicated for language pairs with different alphabets & sound inventories • E.g. “computer” --> “konpyuutaa” 䜷䝷䝗䝩䜪䝃䞀 • Back-transliteration • E.g. “konpyuuta” --> “computer” • Inversion of a lossy process Japanese/English Examples • Some notes about Japanese: • Katakana phonetic system for foreign names/loan words • Syllabary writing: • e.g. one symbol for “ga”䚭䜰, one for “gi”䚭䜲 • Consonant-vowel (CV) structure • Less distinction of L/R and H/F sounds • Examples: • Golfbag --> goruhubaggu 䜸䝯䝙䝔䝇䜴 • New York Times --> nyuuyooku taimuzu䚭䝏䝩䞀䝬䞀䜳䚭䝃䜨䝤䜾 • Ice cream --> aisukuriimu 䜦䜨䜽䜳䝮䞀䝤 The Challenge of Machine Back-transliteration • Back-transliteration is an important component for MT systems • For J/E: Katakana phrases are the largest source of phrases that do not appear in bilingual dictionary or training corpora • Claims: • Back-transliteration is less forgiving than transliteration • Back-transliteration is harder than romanization • For J/E, not all katakana phrases can be “sounded out” by back-transliteration • word processing --> waapuro • personal computer --> pasokon Modular WSA and WFSTs • P(w) - generates English words • P(e|w) - English words to English pronounciation • P(j|e) - English to Japanese sound conversion • P(k|j) - Japanese sound to katakana • P(o|k) - katakana to OCR • Given a katana string observed by OCR, find the English word sequence w that maximizes !!!P(w)P(e | w)P( j | e)P(k | j)P(o | k) e j k Two Potential Solutions • Learn from bilingual dictionaries, then generalize • Pro: Simple supervised learning problem • Con: finding direct correspondence between English alphabets and Japanese katakana may be too tenuous • Build a generative model of transliteration, then invert (Knight & Graehl’s approach): 1. -

KANA Response Live Organization Administration Tool Guide
This is the most recent version of this document provided by KANA Software, Inc. to Genesys, for the version of the KANA software products licensed for use with the Genesys eServices (Multimedia) products. Click here to access this document. KANA Response Live Organization Administration KANA Response Live Version 10 R2 February 2008 KANA Response Live Organization Administration All contents of this documentation are the property of KANA Software, Inc. (“KANA”) (and if relevant its third party licensors) and protected by United States and international copyright laws. All Rights Reserved. © 2008 KANA Software, Inc. Terms of Use: This software and documentation are provided solely pursuant to the terms of a license agreement between the user and KANA (the “Agreement”) and any use in violation of, or not pursuant to any such Agreement shall be deemed copyright infringement and a violation of KANA's rights in the software and documentation and the user consents to KANA's obtaining of injunctive relief precluding any further such use. KANA assumes no responsibility for any damage that may occur either directly or indirectly, or any consequential damages that may result from the use of this documentation or any KANA software product except as expressly provided in the Agreement, any use hereunder is on an as-is basis, without warranty of any kind, including without limitation the warranties of merchantability, fitness for a particular purpose, and non-infringement. Use, duplication, or disclosure by licensee of any materials provided by KANA is subject to restrictions as set forth in the Agreement. Information contained in this document is subject to change without notice and does not represent a commitment on the part of KANA. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Legacy Character Sets & Encodings
Legacy & Not-So-Legacy Character Sets & Encodings Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/cjkv/unicode/iuc15-tb1-slides.pdf Tutorial Overview dc • What is a character set? What is an encoding? • How are character sets and encodings different? • Legacy character sets. • Non-legacy character sets. • Legacy encodings. • How does Unicode fit it? • Code conversion issues. • Disclaimer: The focus of this tutorial is primarily on Asian (CJKV) issues, which tend to be complex from a character set and encoding standpoint. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations dc • GB (China) — Stands for “Guo Biao” (国标 guóbiâo ). — Short for “Guojia Biaozhun” (国家标准 guójiâ biâozhün). — Means “National Standard.” • GB/T (China) — “T” stands for “Tui” (推 tuî ). — Short for “Tuijian” (推荐 tuîjiàn ). — “T” means “Recommended.” • CNS (Taiwan) — 中國國家標準 ( zhôngguó guójiâ biâozhün) in Chinese. — Abbreviation for “Chinese National Standard.” 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • GCCS (Hong Kong) — Abbreviation for “Government Chinese Character Set.” • JIS (Japan) — 日本工業規格 ( nihon kôgyô kikaku) in Japanese. — Abbreviation for “Japanese Industrial Standard.” — 〄 • KS (Korea) — 한국 공업 규격 (韓國工業規格 hangug gongeob gyugyeog) in Korean. — Abbreviation for “Korean Standard.” — ㉿ — Designation change from “C” to “X” on August 20, 1997. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated Terminology & Abbreviations (Cont’d) dc • TCVN (Vietnam) — Tiu Chun Vit Nam in Vietnamese. — Means “Vietnamese Standard.” • CJKV — Chinese, Japanese, Korean, and Vietnamese. 15th International Unicode Conference Copyright © 1999 Adobe Systems Incorporated What Is A Character Set? dc • A collection of characters that are intended to be used together to create meaningful text. -

Implementing Cross-Locale CJKV Code Conversion
Implementing Cross-Locale CJKV Code Conversion Ken Lunde CJKV Type Development Adobe Systems Incorporated bc ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-paper.pdf ftp://ftp.oreilly.com/pub/examples/nutshell/ujip/unicode/iuc13-c2-slides.pdf Code Conversion Basics dc • Algorithmic code conversion — Within a single locale: Shift-JIS, EUC-JP, and ISO-2022-JP — A purely mathematical process • Table-driven code conversion — Required across locales: Chinese ↔ Japanese — Required when dealing with Unicode — Mapping tables are required — Can sometimes be faster than algorithmic code conversion— depends on the implementation September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Code Conversion Basics (Cont’d) dc • CJKV character set differences — Different number of characters — Different ordering of characters — Different characters September 10, 1998 Copyright © 1998 Adobe Systems Incorporated Character Sets Versus Encodings dc • Common CJKV character set standards — China: GB 1988-89, GB 2312-80; GB 1988-89, GBK — Taiwan: ASCII, Big Five; CNS 5205-1989, CNS 11643-1992 — Hong Kong: ASCII, Big Five with Hong Kong extension — Japan: JIS X 0201-1997, JIS X 0208:1997, JIS X 0212-1990 — South Korea: KS X 1003:1993, KS X 1001:1992, KS X 1002:1991 — North Korea: ASCII (?), KPS 9566-97 — Vietnam: TCVN 5712:1993, TCVN 5773:1993, TCVN 6056:1995 • Common CJKV encodings — Locale-independent: EUC-*, ISO-2022-* — Locale-specific: GBK, Big Five, Big Five Plus, Shift-JIS, Johab, Unified Hangul Code — Other: UCS-2, UCS-4, UTF-7, UTF-8, -

Data Encoding: All Characters for All Countries
PhUSE 2015 Paper DH03 Data Encoding: All Characters for All Countries Donna Dutton, SAS Institute Inc., Cary, NC, USA ABSTRACT The internal representation of data, formats, indexes, programs and catalogs collected for clinical studies is typically defined by the country(ies) in which the study is conducted. When data from multiple languages must be combined, the internal encoding must support all characters present, to prevent truncation and misinterpretation of characters. Migration to different operating systems with or without an encoding change make it impossible to use catalogs and existing data features such as indexes and constraints, unless the new operating system’s internal representation is adopted. UTF-8 encoding on the Linux OS is used by SAS® Drug Development and SAS® Clinical Trial Data Transparency Solutions to support these requirements. UTF-8 encoding correctly represents all characters found in all languages by using multiple bytes to represent some characters. This paper explains transcoding data into UTF-8 without data loss, writing programs which work correctly with MBCS data, and handling format catalogs and programs. INTRODUCTION The internal representation of data, formats, indexes, programs and catalogs collected for clinical studies is typically defined by the country or countries in which the study is conducted. The operating system on which the data was entered defines the internal data representation, such as Windows_64, HP_UX_64, Solaris_64, and Linux_X86_64.1 Although SAS Software can read SAS data sets copied from one operating system to another, it impossible to use existing data features such as indexes and constraints, or SAS catalogs without converting them to the new operating system’s data representation. -

International Language Environments Guide
International Language Environments Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 806–6642–10 May, 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, Java, XView, ToolTalk, Solstice AdminTools, SunVideo and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. SunOS, Solaris, X11, SPARC, UNIX, PostScript, OpenWindows, AnswerBook, SunExpress, SPARCprinter, JumpStart, Xlib The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

JFP Reference Manual 5 : Standards, Environments, and Macros
JFP Reference Manual 5 : Standards, Environments, and Macros Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 817–0648–10 December 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements.