Revised to 2016
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

THE LANGUAGE OFTHE SALINAN INDIANS Nominalizing Suffixes
UNIVERSITY OF CALIFORNIA PUBLICATIONS IN AMERICAN ARCHAEOLOGY AND ETHNOLOGY Vol. 14, No. 1, pp. 1-154 January 10, 1918 THE LANGUAGE OF THE SALINAN INDIANS BY J. ALDEN MASON CONTENTS PAGE INTRODUCTION..--.--.......------------........-----...--..--.......------........------4 PART I. P'HONOLOGY ---------7 Phonetic system ----------------------------------------------------------------------------------------------- Vowels ------------------------------------------------------------------------------------- 7 Quality ----------------------------------------------------------------------------------------------------8 Nasalization ----------------------------------------------------------------------------------------8 Voiceless vowels.------------------......-------------.........-----------------......---8 Accent --------------------------------------------------9 Consonants ................---------.............--------------------...----------9 Semi-vowels ---------------------------------------------------------------------------------9 Nasals ---------- 10 Laterals -------------------------------------------------------------10 Spirants ---------------------------------------....-------------------------------------------10 Stops .--------......... --------------------------- 11 Affricatives .......................-.................-........-......... 12 Tableof phonetic system ---------------------------.-----------------13 Phonetic processes ---------------------------.-----.--............13 Vocalic assimilation ------------------..-.........------------------13 -

The Cambridge Handbook of Phonology
This page intentionally left blank The Cambridge Handbook of Phonology Phonology – the study of how the sounds of speech are represented in our minds – is one of the core areas of linguistic theory, and is central to the study of human language. This state-of-the-art handbook brings together the world’s leading experts in phonology to present the most comprehensive and detailed overview of the field to date. Focusing on the most recent research and the most influential theories, the authors discuss each of the central issues in phonological theory, explore a variety of empirical phenomena, and show how phonology interacts with other aspects of language such as syntax, morph- ology, phonetics, and language acquisition. Providing a one-stop guide to every aspect of this important field, The Cambridge Handbook of Phonology will serve as an invaluable source of readings for advanced undergraduate and graduate students, an informative overview for linguists, and a useful starting point for anyone beginning phonological research. PAUL DE LACY is Assistant Professor in the Department of Linguistics, Rutgers University. His publications include Markedness: Reduction and Preservation in Phonology (Cambridge University Press, 2006). The Cambridge Handbook of Phonology Edited by Paul de Lacy CAMBRIDGE UNIVERSITY PRESS Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, São Paulo Cambridge University Press The Edinburgh Building, Cambridge CB2 8RU, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521848794 © Cambridge University Press 2007 This publication is in copyright. Subject to statutory exception and to the provision of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. -

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -
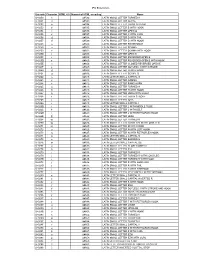
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with -

Spacing Modifier Letters Range: 02B0–02FF the Unicode Standard
Spacing Modifier Letters Range: 02B0–02FF The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

MUFI Character Recommendation V. 3.0: Code Chart Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 2: Code chart order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-403-9 MUFI character recommendation ※ Part 2: code chart order version 3.0 p. 2 / 245 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). There are also 18 characters which have been decommissioned from the Private Use Area due to the fact that they have been included in later versions of the Unicode Standard (and, in one case, because a character has been withdrawn). -

Font Configuration Files Supported Platforms 6-1 Loading Font Configuration Files 6-1
Java Platform, Standard Edition Internationalization Guide Release 9 E76505-03 September 2017 Java Platform, Standard Edition Internationalization Guide, Release 9 E76505-03 Copyright © 1993, 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. -

LATEX for Linguists Contents Reader
LATEX for Linguists LATEX for Linguists Contents 1 Transcriptions with IPA LATEX for Linguists L L 4 05: IPA & verbatim 2 Verbatim Antonio Machicao y Priemer hps://www.linguistik.hu-berlin.de/sta/amyp MGK Workshop – SFB 1412, Berlin 1 / 11 2 / 11 LATEX for Linguists LATEX for Linguists Transcriptions with IPA Reader 1 Transcriptions with IPA LATEX Reader (Freitag & Machicao y Priemer 2019): 2 Verbatim hps://doi.org/10.13140/RG.2.2.29299.27682 Exercises and Handouts: hps://www.linguistik.hu-berlin.de/de/sta/amyp/latex 3 / 11 4 / 11 LATEX for Linguists LATEX for Linguists Transcriptions with IPA Transcriptions with IPA macros: Transcriptions with IPA [\textglotstop{}an.\textesh{}\textinvscr{}\texttoptiebar{a\textsci{}}. \textschwa{}n] [\textsecstress\textepsilon kspl\textschwa \textprimstress ne\textsci\textesh \textschwa n] The package tipa oers commands for transcriptions with IPA, but it is not fully compatible with all other packages. (1)[ Pan.SK>aI.@n] (2)[ Ekspl@"neIS@n] Since tipa redefines certain LATEX commands, additional seings may be necessary (depending on your font encoding): groups of macros: > Load the package fontenc with the options T3 and T1 (in that order). \textipa{[Pan.SK\t{aI}.@n]} (3) [Pan.SKaI.@n] \textipa{[""Ekspl@"neIS@n]} Load tipa with the options noenc and safe. (4) [Ekspl@"neIS@n] \usepackage[T3,T1]{fontenc} tipa environment: \usepackage[noenc,safe]{tipa} > \begin{IPA} (5) [Pan.SKaI.@n] [Pan.SK\t{aI}.@n] tipa provides 3 ways to use IPA characters: macros, group of macros, and [Ekspl@"neIS@n] environment. [""Ekspl@"neIS@n] \end{IPA} Normally, we use macros inside of \textipa{ }. -

Journal of the International Phonetic Association
International Phonetic Association General information For general information on the International Phonetic Association contact: Secretariat, International Phonetic Association Department of Theoretical and Applied Linguistics School of English Aristotle University of Thessaloniki Thessaloniki 54124 Greece Tel: (+30) 2310 997429 Fax: (+30) 2310 997432 E-mail: [email protected] IPA on the Web The IPA also maintains a site on the World Wide Web which provides information on the International Phonetic Alphabet, on available phonetic fonts and sound recordings, on subscription to the Association, and on examinations in phonetics. It also has links to other sources of information on phonetics. The address is: http://www.langsci.ucl.ac.uk/IPA/ipa Audio files of the recorded material accompanying the language Illustrations in the Handbook of the International Phonetic Association, published by Cambridge University Press in 1999, may be downloaded from the following web site: http://web.uvic.ca/ling/resources/ipa/handbook.htm Audio files of the recorded material accompanying language Illustrations published in the Journal of the International Phonetic Association since 1998 (after the publication of the Handbook of the International Phonetic Association) may be downloaded from the following privileged-access website available to registered members of the IPA: http://web.uvic.ca/ling/resources/ipa/members Members can contact the Secretary to obtain a username and a password. Membership services and publications The annual dues of the Association for 2010 are 45 euros for full membership and 22.50 euros for student membership. They should be paid to the Treasurer, International Phonetic Association, Department of Applied Linguistics, School of Languages and European Studies, University of Reading, Whiteknights, Reading RG6 6AA, UK.