Using the Unicode Standard for Linguistic Data: Preliminary Guidelines∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Alan Ng Systems Librarian the Chinese University of Hong Kong Library Agenda
Enhancing Chinese character normalization in Primo with the HKIUG TSVCC mapping table Alan Ng Systems Librarian The Chinese University of Hong Kong Library Agenda ❖ Primo out-of-box character normalization ❖ Background on CJK normalization ❖ HKIUG TSVCC mapping table ❖ Implementing TSVCC on Primo About CUHK Library ❖ established in 1963 ❖ 7 branches ❖ 200 staff ❖ 260K current patrons ❖ 130K journal subscriptions, 4.5M ebooks, 2.5M printed volumes ❖ special collections includes from oracles bones, Chinese rare books, modern Chinese literary archives … character normalization ❖ different people type differently ❖ normal to expect “Apple” will have the exact results from “aPPLE”, “ApPle”, “appLE” … ❖ before indexing, Primo will first “clean up” (normalize) the data to its lower case (e.g. A —> a, B —> b …) ❖ Primo FE will do the same for the search term typed by users, to get a match with the index Primo out-of-box normalizations ❖ Primo provides OTB normalizations for different languages at: ❖ /exlibris/primo/p4_1/ng/jaguar/home/profile/ analysis/specialCharacters/CharConversion/OTB/ OTB ❖ e.g. ❖ latin languages (non_cjk_unicode_normalization.txt) ❖ CJK (cjk_unicode_trad_to_simp_normalization.txt) OTB CJK normalization table ❖ 2700+ entries ❖ mainly for mapping Traditional Chinese into its Simplified form ❖ assume it is a 1:1 mapping, Simplified Chinese being the “lowercase” like the English language ❖ But in fact, Simplified Chinese is only one kind of variant form for Chinese character ❖ other variant forms (ideograph) of the same character need to be cover as well extract of the OTB table background on CJK ❖ Traditional Chinese characters have been used since as early as 2nd centuryBC (Han Dynasty, 漢朝) ❖ used by people in Taiwan, Hong Kong and Macau ❖ Simplified Chinese characters were introduced by PRC government during 1950’s ❖ used by people in PRC, SE Asia countries e.g. -
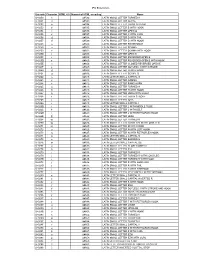
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Wg2 N5125 & L2/19-386
ISO/IEC JTC1/SC2/WG2 N5125 L2/19-386 Title: Proposal to change the code chart font for 21 blocks in Unicode Version 14.0 Author: Ken Lunde Date: 2019-12-02 This document proposes to change the code chart font for 21 blocks—affecting 1,762 charac- ters—that are CJK-related or otherwise include characters that are used primarily in CJK con- texts and are therefore supported in fonts for typical CJK typefaces. The suggested target for this change is Unicode Version 14.0 (2021). The purpose of this font change is four-fold: • Reduce the number of fonts that are necessary for code chart production. • Improve the consistency of the glyphs for similar or related characters by using a uniform typeface design and typeface style, at least for characters whose glyphs do not need to ad- here to a particular specification.. • Simplify code chart font management by covering as many complete blocks as possible using a single font. • Ensure that the font is accessible via open source. The actual font, CJK Symbols, will be open-sourced in both TrueType and OpenType/CFF for- mats under the terms of the SIL Open Font License, Version 1.1, and therefore can be updated to include glyphs for additional blocks, or to add glyphs to blocks that are already supported. This is maintenance work that I plan to take on for the foreseeable future. Code Tables This and subsequent pages include left-to-right, top-to-bottom code tables that serve as a glyph synopsis for the CJK Symbols font. -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with -

1. Introduction
ISO/IEC JTC1/SC2/WG2 N3643 L2/09-171 2009-04-30 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to redefine the scope of Ideographic Description Sequences and to encode four additional Ideographic Description Characters Source: Andrew West Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2009-04-30 1. Introduction This is a proposal to redefine the scope of Ideographic Description Sequences (IDS) to cover non-Han scripts (see Section 3), and also to encode four new Ideographic Description Characters (IDC) in order to represent IDS sequences in non-Han scripts (see Section 2). 1.1 Current Definition of IDS Sequences The Unicode Standard 5.1 section 12.2 defines Ideographic Description Sequences as follows: Ideographic Description Sequences. Ideographic Description Sequences are defined by the following grammar. The list of characters associated with the Unified_CJK_Ideograph and CJK_Radical properties can be found in the Unicode Character Database. See Appendix A, Notational Conventions , for the notational conventions used here. IDS := Unified_CJK_Ideograph | CJK_Radical | IDS_BinaryOperator IDS IDS | IDS_TrinaryOperator IDS IDS IDS IDS_BinaryOperator := U+2FF0 | U+2FF1 | U+2FF4 | U+2FF5 | U+2FF6 | U+2FF7 | U+2FF8 | U+2FF9 | U+2FFA | U+2FFB IDS_TrinaryOperator := U+2FF2 | U+2FF3 This definition is also echoed in ISO/IEC 10646:2003 Annex F.3.1: F.3.1 Syntax of an ideographic description sequence An IDS consists of an IDC followed by a fixed number of Description Components (DC). A DC may be any one of the following : - a coded ideograph - a coded radical - another IDS NOTE 1 – The above description implies that any IDS may be nested within another IDS. -

Special Characters in Aletheia
Special Characters in Aletheia Last Change: 28 May 2014 The following table comprises all special characters which are currently available through the virtual keyboard integrated in Aletheia. The virtual keyboard aids re-keying of historical documents containing characters that are mostly unsupported in other text editing tools (see Figure 1). Figure 1: Text input dialogue with virtual keyboard in Aletheia 1.2 Due to technical reasons, like font definition, Aletheia uses only precomposed characters. If required for other applications the mapping between a precomposed character and the corresponding decomposed character sequence is given in the table as well. When writing to files Aletheia encodes all characters in UTF-8 (variable-length multi-byte representation). Key: Glyph – the icon displayed in the virtual keyboard. Unicode – the actual Unicode character; can be copied and pasted into other applications. Please note that special characters might not be displayed properly if there is no corresponding font installed for the target application. Hex – the hexadecimal code point for the Unicode character Decimal – the decimal code point for the Unicode character Description – a short description of the special character Origin – where this character has been defined Base – the base character of the special character (if applicable), used for sorting Combining Character – combining character(s) to modify the base character (if applicable) Pre-composed Character Decomposed Character (used in Aletheia) (only for reference) Combining Glyph -

Proste Unikodne Vektorske Pisave
Proste unikodne vektorske pisave Primozˇ Peterlin Univerza v Ljubljani, Medicinska fakulteta, Institutˇ za biofiziko Lipiceˇ va 2, 1000 Ljubljana primoz.peterlin@biofiz.mf.uni-lj.si Povzetek Predstavljen je projekt prostih unikodnih vektorskih pisav. Uvodoma predstavimo stanje s pisavami v prostih programskih okoljih in motive za izdelavo prostih pisav. Osrednji del prispevka je namenjen opisu zasnove tipografije, ki vkljucujeˇ pismenke iz razlicnihˇ pisav. Sledi opis razlogov, zakaj je OpenType najboljsaˇ trenutno dostopna tehnologija. Zakljucimoˇ s pregledom stanja projekta in nacrtiˇ za delo v prihodnje. 1. Uvod se porajajo tako v akademskih jezikoslovnih krogih kot tudi “na terenu”, torej v okoljih, kjer ziˇ vijo govorci jezikov, ki Prosti operacijski sistemi, kot so GNU/Linux ter sistemi te pismenke uporabljajo. FreeBSD, OpenBSD in NetBSD, izhajajociˇ iz BSD Unixa, so od sistema Unix podedovali stihijsko obravnavanje pi- 1.1. Znaki in pismenke sav. Tako graficniˇ sistem X Window System uporablja svojo Standard ISO10646/Unicode (Unicode Consortium, obliko zapisa pisav, terminalski nacinˇ svojo, stavni program 2000) izrecno locujeˇ med “znaki” (angl. character) in “pi- T X pa spet svoje. Krajevna prilagoditev (lokalizacija) ta- E smenkami” (angl. glyph): “Characters reside only in the kih sistemov je zato po nepotrebnem bolj zapletena, kot bi machine, as strings in memory or on disk, in the backing bilo nujno potrebno, saj je treba poskrbeti za vsakega od store. The Unicode standard deals only with character locenihˇ podsistemov posebej. codes. In contrast to characters, glyphs appear on the Boljsaˇ resiteˇ v je uporaba enotne oblike zapisa pisave, screen or paper as particular representation of one or more ki ga uporabljajo vsi programi za prikaz pismenk na za- backing store characters. -

Glyphs in Font Noto Sans CJK TC (Notosanscjktc-Regular.Otf from Noto-Hinted)
Glyphs in font Noto Sans CJK TC (NotoSansCJKtc-Regular.otf from Noto-hinted) asic !atin" #$%%%%-%%&' #$%%(%-)' *+,-./()0$"-.1%2()345&6789:;<= #$%%3%-4' >? C@A'GHCJK!DNEFGRSTUHIJKLMNOPQ #$%%5%-&' RaScdefghiTUlmnopqrstuWXYyZ[\]^ !atin-2 Supplement" #$%%6%-%%'' #$%%?%- ' _`abcdefghijklmnopqrstuvwxyz{| #$%%C%-@' }~ÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞß #$%%A%-'' àáâã¡¢£¤¥¦§¨©ª«¬®¯ó±²³÷ø¶·¸¹º»¼ !atin AYtended-?" #$%2%%-%2&' #$%2%%-2' ½ā¿ă ÁÂÃÄ ÅÆ #$%2(%-)' ÇÈĪÊ #$%23%-4' Ëń ÍÎ ÏÐŎŏ Œœ #$%25%-&' ŨũŪūŬŭ !atin AYtended- " #$%26%-%(3' #$%26%-7' ƒ #$%2?%- ' Ơơ Ưư #$%2C%-@' ǍáǏãǑǒǓǔèéêëǙǚǛǜ #$%2A%-'' Ǹñ CF? AYtensions" #$%(4%-%(?' #$%(4%-5' ɑ ɡ Spacing Dodifier !etters" #$%( %-%('' #$%( %-C' ˇ ˉˊˋ #$%(@%-A' ˙ GreeU and Coptic, #$%)&%-%)'' #$%)7%-?' úûΓΔΕΖΗΘΙΚΛΜΝΞΟΠΡ ΣΤΥΦΧΨΩ #$%) %-C' αβγδεζηθικλμν !"# $%&'()* Cyrillic, #$%3%%-%3'' #$%3%%-2' + ,-./0123456789:; #$%3(%-)' <=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[ #$%33%-4' \]^_`abcdefghijk l Noto Sans CJK TC 2 Bangul Jamo" #$22%%-22'' #$22%%-2' ᄀᄁᄂᄃᄄᄅᄆᄇᄈᄉᄊᄋᄌᄍᄎᄏᄐᄑᄒᄓᄔᄕᄖᄗᄘᄙᄚᄛᄜᄝᄞᄟ #$22(%-)' ᄠᄡᄢᄣᄤᄥᄦᄧᄨᄩᄪᄫᄬᄭᄮᄯᄰᄱᄲᄳᄴᄵᄶᄷᄸᄹᄺᄻᄼᄽᄾᄿ #$223%-4' ᅀᅁᅂᅃᅄᅅᅆᅇᅈᅉᅊᅋᅌᅍᅎᅏᅐᅑᅒᅓᅔᅕᅖᅗᅘᅙᅚᅛᅜᅝᅞᅟ #$225%-&' ᅠᅡᅢᅣᅤᅥᅦᅧᅨᅩᅪᅫᅬᅭᅮᅯᅰᅱᅲᅳᅴᅵᅶᅷᅸᅹᅺᅻᅼᅽᅾᅿ #$226%-7' ᆀᆁᆂᆃᆄᆅᆆᆇᆈᆉᆊᆋᆌᆍᆎᆏᆐᆑᆒᆓᆔᆕᆖᆗᆘᆙᆚᆛᆜᆝᆞᆟ #$22?%- ' ᆠᆡᆢᆣᆤᆥᆦᆧᆨᆩᆪᆫᆬᆭᆮᆯᆰᆱᆲᆳᆴᆵᆶᆷᆸᆹᆺᆻᆼᆽᆾᆿ #$22C%-@' ./0123456789:;<=>?@ABCDEFGHIJKLM #$22A%-'' NOPQRSTUVWXYZ[\]^_`abcdefghijklm !atin AYtended ?dditional" #$2A%%-2A'' #$2A(%-)' no #$2A?%- ' pqrstuvwxyz{|}~ắẰằẲẳẴẵẶặẸẹẺẻẼẽẾế #$2AC%-@' ỀềỂểỄễỆệỈỉỊịỌọỎỏỐ¡¢£¤¥¦§¨©ª«¬®¯ #$2AA%-'' Ỡ±²³´ụ¶·¸¹º»¼½Ữ¿ỰÁÂÃÄÅÆÇÈỹ General Functuation" #$(%%%-(%5' #$(%%%-2' ÊË ‐-ÍÍÎÏÐ ‘’‚ “”„ #$(%(%-)' -

MUFI Character Recommendation V. 3.0: Code Chart Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 2: Code chart order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-403-9 MUFI character recommendation ※ Part 2: code chart order version 3.0 p. 2 / 245 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). There are also 18 characters which have been decommissioned from the Private Use Area due to the fact that they have been included in later versions of the Unicode Standard (and, in one case, because a character has been withdrawn). -

The Unicode Standard, Version 6.2 Copyright © 1991–2012 Unicode, Inc
The Unicode Standard Version 6.2 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Copyright © 1991–2012 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium ; edited by Julie D. Allen ... [et al.]. — Version 6.2.