Wg2 N5125 & L2/19-386
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc. -

Outline of the Course
Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (()30%) User Services (10%) Additional topics (()15%) Buliding of a (small) digital library Reference material: – Ian Witten, David Bainbridge, David Nichols, How to build a Digital Library, Morgan Kaufmann, 2010, ISBN 978-0-12-374857-7 (Second edition) – The Web FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -1 Access to information Representation of characters within a computer Representation of documents within a computer – Text documents – Images – Audio – Video How to store efficiently large amounts of data – Compression How to retrieve efficiently the desired item(s) out of large amounts of data – Indexing – Query execution FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -2 Representation of characters The “natural” wayyp to represent ( (palphanumeric ) characters (and symbols) within a computer is to associate a character with a number,,g defining a “coding table” How many bits are needed to represent the Latin alphabet ? FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -3 The ASCII characters The 95 printable ASCII characters, numbdbered from 32 to 126 (dec ima l) 33 control characters FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -4 ASCII table (7 bits) FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -5 ASCII 7-bits character set FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -6 Representation standards ASCII (late fifties) – AiAmerican -

Using the Unicode Standard for Linguistic Data: Preliminary Guidelines∗
Using the Unicode Standard for Linguistic Data: Preliminary Guidelines∗ Deborah Anderson UC Berkeley 1 Introduction A core concern for E-MELD is the need for a common standard for the digitalization of linguistic data, for the different archiving practices and representation of languages will inhibit accessing data, searching, and scientific investigation.1 While the context is expressed in terms of documenting endangered languages, E- MELD will serve generally as a “showroom of best practices” for linguistic data from all languages. The problem posed by the lack of a single, common standard for text data in various scripts was already evident in the business world in the 1980s, when competing industry and governmental body character encoding standards made the exchange of text data chaotic. This situation led to the creation of a single, universal character encoding standard, Unicode.2 That standard was synchronized with the ISO/IEC 10646, the parallel International Standard maintained by the International Organization for Standardization (ISO). Unicode is now the default character encoding standard for XML. Fortunately, Unicode provides a single standard that can be used by linguists in their work, either when working with transcription, languages with existent writing systems, or those languages that have no established orthography. Indeed, its use is advocated in “Seven Dimensions of Portability for Language Documentation and Description” (Bird and Simons 2002). But specifying “Unicode” as the character encoding does not provide enough guidance for many linguists, who may be puzzled by the structure of the Unicode Standard and how to use it, are unsure which Unicode characters ought to be used in a particular context and whom to ask about this, are uncertain how to report a missing character, etc. -

Section 18.1, Han
The Unicode® Standard Version 12.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2019 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 12.0. Includes index. ISBN 978-1-936213-22-1 (http://www.unicode.org/versions/Unicode12.0.0/) 1. -

10646-2CD US Comment
WG2 N2807R INCITS/L2/04- 161R2 Date: June 21, 2004 Title: HKSCS and GB 18030 PUA characters, background document Source: UTC/US Authors: Michel Suignard, Eric Muller, John Jenkins Action: For consideration by UTC and IRG Summary This documents describes characters still encoded in the Private Use Area of ISO/IEC 10646/Unicode as commonly found in the mapping information for Chinese coded characters such as HKSCS and GB-18030. It describes new encoding proposal to eliminate these Private Use Area allocation, so that the PUA can really be used for its true purpose. Doing so would tremendously improve interoperability between the East Asian market platforms because support for Government related encoded repertoire would not interfere with local comprehensive usage of the PUA area. Hong Kong Supplementary Character Set (HKSCS) According to http://www.info.gov.hk/digital21/eng/hkscs/download/big5-iso.txt there are a large number of HKSCS-2001 characters still encoded in the Private Use Area (PUA). A large majority of these characters looks like CJK Basic stroke that could be used to describe the appearance of CJK characters. Although there are already collections of various CJK fragments (such as CJK Radicals Supplement, Kangxi Radical) and methods to describe their arrangement using the Ideographic Description Characters, these ‘stroke’ elements stands on their own merit as an interesting mechanism to describe CJK characters and corresponding glyphs. Most of these characters have been proposed for encoding on the CJK Extension C. However that extension is not yet mature, but at the same time removing characters from the PUA is urgent. -
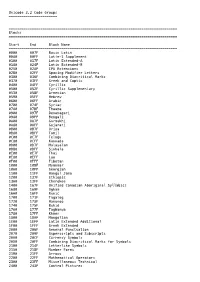
Unicode Groups
Unicode 3.2 Code Groups ======================= ================================================================================ Blocks ================================================================================ Start End Block Name -------------------------------------------------------------------------------- 0000 007F Basic Latin 0080 00FF Latin-1 Supplement 0100 017F Latin Extended-A 0180 024F Latin Extended-B 0250 02AF IPA Extensions 02B0 02FF Spacing Modifier Letters 0300 036F Combining Diacritical Marks 0370 03FF Greek and Coptic 0400 04FF Cyrillic 0500 052F Cyrillic Supplementary 0530 058F Armenian 0590 05FF Hebrew 0600 06FF Arabic 0700 074F Syriac 0780 07BF Thaana 0900 097F Devanagari 0980 09FF Bengali 0A00 0A7F Gurmukhi 0A80 0AFF Gujarati 0B00 0B7F Oriya 0B80 0BFF Tamil 0C00 0C7F Telugu 0C80 0CFF Kannada 0D00 0D7F Malayalam 0D80 0DFF Sinhala 0E00 0E7F Thai 0E80 0EFF Lao 0F00 0FFF Tibetan 1000 109F Myanmar 10A0 10FF Georgian 1100 11FF Hangul Jamo 1200 137F Ethiopic 13A0 13FF Cherokee 1400 167F Unified Canadian Aboriginal Syllabics 1680 169F Ogham 16A0 16FF Runic 1700 171F Tagalog 1720 173F Hanunoo 1740 175F Buhid 1760 177F Tagbanwa 1780 17FF Khmer 1800 18AF Mongolian 1E00 1EFF Latin Extended Additional 1F00 1FFF Greek Extended 2000 206F General Punctuation 2070 209F Superscripts and Subscripts 20A0 20CF Currency Symbols 20D0 20FF Combining Diacritical Marks for Symbols 2100 214F Letterlike Symbols 2150 218F Number Forms 2190 21FF Arrows 2200 22FF Mathematical Operators 2300 23FF Miscellaneous Technical 2400 243F Control -

Greek Abcdefghijklmno
Autoclick - typing UNICODE - http://pcl.to/unicode © RedTitan™ Technology 2005 ÊËÌÍÎÏ&'Ï(ËÎ)ÎÏ*Ë+,-./01Ï234567Ï89:0Ï;<Ï=4Ï>04?;+Í&Ïê To view this document as UNICODE.TXT you need Notepad conf igured for font Arial on Windows XP Most Windows XP text utilities support Unicode using UTF - see http://pcl.to/unicode/utf .xml Many Windows XP fonts have more than 255 character glyphs defined. For example, the font Arial has 1419 glyphs defined which covers many foreign languages and a lot of technical symbols. Check your favourite font on http://pcl.to/pclt/ The question remains - How do you insert UTF encoded UNICODE into a docum ent like this text file? You can buy specialist editors and a new keyboard but if you just want to insert a small amount of ÊËÌÍÎËÏ Arabic text there has got to be an easier way! The AUTOCLICK utility from RedTitan provides an answer. Just click on the character and you too can - ABCÏDEFGHIJCÏKFLBMNÏ (type in Greek) Unicode code plane 0x03: JDOPBCQHGMIKRCLSTENUVWXYZ[Ï- Greek Unicode code plane 0x04: \]^_`abcdefghijklmnopqrstuvwxyz{Ï- Russian Unicode code plane 0x05: &'()*+ - Hebrew Unicode code plane 0x06: ÊËÌÍÎËÏ -Arabic Print this document with a PCL driver and use RedTitan EscapeE to convert to PDF. Note: AutoClick supports characters in the rang e 0x0000 to 0xFFFF. i.e. two byte. Version 3 UNICODE defines 3 bytes and moves some of the original glyph ranges (e.g Chinese). The full list looks like this Unicode version 3.0 - range start codes. 0000 Basic Latin 0080 Latin-1 Supplem ent 0100 Latin Extended-A 0180 Latin -
Unicodestandard the UNICODE CONSORTIUM .4Vaddison
UnicodeUnicode .o STANDARD THE UNICODE CONSORTIUM Edited by Julie D. Allen, Joe Becker, Richard Cook, Mark Davis, Michael Everson, Asmus Freytag, John H. Jenkins, Mike Ksar, Rick McGowan, Lisa Moore, Eric Muller, Markus Scherer, Michel Suignard, and Ken Whistler .4vAddison-Wesley Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Contents List of Figures xxiii List of Tables xxvii Foreword by Mark Davis xxxi Preface xxxiii Why Buy This Book xxxiii Why Upgrade to Version 5.0 xxxiv Organization of This Book xxxiv Unicode Standard Annexes xxxvi The Unicode Character Database xxxvii Unicode Technical Standards and Unicode Technical Reports xxxvii On the CD-ROM xxxvü Updates and Errata xxxviii Acknowledgments xxxix Unicode Consortium Members xlvii Unicode Consortium Liaison Members xlix Unicode Consortium Board of Directors 1 Introduction 1 1.1 Coverage 2 Standards Coverage 3 New Characters 3 1.2 Design Goals 4 1.3 Text Handling 5 Text Elements 6 2 General Structure 9 2.1 Architectural Context 9 Basic Text Processes 10 Text Elements, Characters, and Text Processes 10 Text Processes and Encoding 11 2.2 Unicode Design Principles 13 Universality 14 Efficiency 14 Characters, Not Glyphs 14 Semantics 16 Plain Text 18 Logical Order 19 Unification 21 Dynamic Composition 22 x Co ntents Stability 22 Convertibility 23 2.3 Compatibility Characters 23 Compatibility Variants 23 Compatibility Decomposable Characters 24 Mapping Compatibility -

The Unicode Standard Version 3.0
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON-WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts • Harlow, England • Menlo Park, California Berkeley, California • Don Mills, Ontario • Sydney Bonn • Amsterdam • Tokyo • Mexico City Contents Acknowledgments iii Unicode Consortium Menibers and Directors viii Füll Members viii Current Associate Members viii Current Liaison Menibers ix Current Specialist Members ix Current Individual Members ix Current Members of the Board of Directors ix Former Members of the Board of Directors ix Contents xi Figures xix Tables xxi Preface xxv 0.1 About the Unicode Standard xxv Concepts, Architecture, Conformance, and Guidelines xxv Character Block Descriptions xxvi Charts and Index xxvi Appendices and Tables xxvii The Unicode Character Database and Technical Reports xxvii On the CD-ROM xxvii 0.2 Notational Conventions xxviii Extended BNF xxviii Operators xxix 0.3 Resources xxx Unicode Web Site xxx Unicode Anonymous FTP Site xxx Unicode Public Mailing List xxx How to Contact the Unicode Consortium xxx Introduction 1 1.1 Coverage 2 Standards Coverage 3 New Characters 3 1.2 Design Basis 3 1.3 Text Handling 4 Interpreting Characters 5 Text Elements 5 1.4 The Unicode Standard and ISO/IEC 10646 5 1.5 The Unicode Consortium 6 The Unicode Technical Committee 6 General Structure 9 2.1 Architectural Context 9 Basic Text Processes 9 Text Elements, Code Values, and Text Processes 10 The Unicode Standard 3.0 xi Contents Text Processes and Encoding 1 ] 2.2 Unicode Design Principles -

10.1 Han CJK Unified Ideographs
Chapter 10 East Asian Scripts 10 All of the writing systems of East Asia have as their root the ideographic script developed in China in the second millennium . Originally intended to write the various Chinese dia- lects, this script was exported throughout China’s sphere of influence and was used for cen- turies to write even non-Chinese languages such as Japanese, Korean, and Vietnamese. Speakers of other languages, such as Yi, created their own ideographs in imitation of Chinese. The Chinese language is largely monosyllabic and noninflecting, and an ideographic writ- ing system suits it well. Ideographs are less well suited for unrelated languages. In Japan, this problem was solved by creating two syllabic scripts, hiragana and katakana. In Korea, an alphabetic system was invented, with letters grouped into ideograph-like syllabic blocks called hangul. Ideographs continued to be the exclusive way of writing Vietnamese until the twentieth century, when they were replaced with an alphabet based on the Latin script. They are still extensively used in Japanese, where they are called kanji, and somewhat more rarely in Korean, where they are called hanja. In mainland China, the government has promoted the use of more modern, simplified forms of the ideographs over the older, more traditional forms used in Taiwan and overseas Chinese communities. Appendix A, Han Unification History, describes how the diverse typographic traditions of mainland China, Taiwan, Japan, Korea, and Vietnam have been reconciled to provide a common set of ideographs in the Unicode Standard for all of these languages and regions. The Unicode Standard includes a complete set of Korean hangul syllables, as well as the individual letters (jamos), which can be also be used to write Korean.