Phonetic Symbols in Word Processing and on the Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unicode Request for Cyrillic Modifier Letters Superscript Modifiers
Unicode request for Cyrillic modifier letters L2/21-107 Kirk Miller, [email protected] 2021 June 07 This is a request for spacing superscript and subscript Cyrillic characters. It has been favorably reviewed by Sebastian Kempgen (University of Bamberg) and others at the Commission for Computer Supported Processing of Medieval Slavonic Manuscripts and Early Printed Books. Cyrillic-based phonetic transcription uses superscript modifier letters in a manner analogous to the IPA. This convention is widespread, found in both academic publication and standard dictionaries. Transcription of pronunciations into Cyrillic is the norm for monolingual dictionaries, and Cyrillic rather than IPA is often found in linguistic descriptions as well, as seen in the illustrations below for Slavic dialectology, Yugur (Yellow Uyghur) and Evenki. The Great Russian Encyclopedia states that Cyrillic notation is more common in Russian studies than is IPA (‘Transkripcija’, Bol’šaja rossijskaja ènciplopedija, Russian Ministry of Culture, 2005–2019). Unicode currently encodes only three modifier Cyrillic letters: U+A69C ⟨ꚜ⟩ and U+A69D ⟨ꚝ⟩, intended for descriptions of Baltic languages in Latin script but ubiquitous for Slavic languages in Cyrillic script, and U+1D78 ⟨ᵸ⟩, used for nasalized vowels, for example in descriptions of Chechen. The requested spacing modifier letters cannot be substituted by the encoded combining diacritics because (a) some authors contrast them, and (b) they themselves need to be able to take combining diacritics, including diacritics that go under the modifier letter, as in ⟨ᶟ̭̈⟩BA . (See next section and e.g. Figure 18. ) In addition, some linguists make a distinction between spacing superscript letters, used for phonetic detail as in the IPA tradition, and spacing subscript letters, used to denote phonological concepts such as archiphonemes. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

FONT GUIDE Workbook to Help You Find the Right One for Your Brand
FONT GUIDE Workbook to help you find the right one for your brand. www.ottocreative.com.au Choosing the right font for your brand YOUR BRAND VALUES: How different font styles can be used to make up your brand: Logo Typeface: Is usually a bit more special and packed with your brands personality. This font should be used sparingly and kept for special occasions. Headings font: Logo Font This font will reflect the same brand values as your logo font - eg in this example both fonts are feminine and elegant. Headings Unlike your logo typeface, this font should be easier to read and look good a number of different sizes and thicknesses. Body copy Body font: The main rule here is that this font MUST be easy to read, both digitally and for print. If there is already alot going on in your logo and heading font, keep this style simple. Typefaces, common associations & popular font styles San Serif: Clean, Modern, Neutral Try these: Roboto, Open Sans, Lato, Montserrat, Raleway Serif: Classic, Traditional, reliable Try these: Playfair Display, Lora, Source Serif Pro, Prata, Gentium Basic Slab Serif: Youthful, modern, approachable Try these: Roboto Slab, Merriweather, Slabo 27px, Bitter, Arvo Script: Feminine, Romantic, Elegant Try these: Dancing Script, Pacifico, Satisfy, Courgette, Great Vibes Monotype:Simple, Technical, Futuristic Try these: Source Code Pro, Nanum Gothic Coding, Fira Mono, Cutive Mono Handwritten: Authentic, casual, creative Try these: Indie Flower, Shadows into light, Amatic SC, Caveat, Kalam Display: Playful, fun, personality galore Try these: Lobster, Abril Fatface, Luckiest Guy, Bangers, Monoton NOTE: Be careful when using handwritten and display fonts, as they can be hard to read. -

Complete Issue 40:3 As One
TUGBOAT Volume 40, Number 3 / 2019 General Delivery 211 From the president / Boris Veytsman 212 Editorial comments / Barbara Beeton TEX Users Group 2019 sponsors; Kerning between lowercase+uppercase; Differential “d”; Bibliographic archives in BibTEX form 213 Ukraine at BachoTEX 2019: Thoughts and impressions / Yevhen Strakhov Publishing 215 An experience of trying to submit a paper in LATEX in an XML-first world / David Walden 217 Studying the histories of computerizing publishing and desktop publishing, 2017–19 / David Walden Resources 229 TEX services at texlive.info / Norbert Preining 231 Providing Docker images for TEX Live and ConTEXt / Island of TEX 232 TEX on the Raspberry Pi / Hans Hagen Software & Tools 234 MuPDF tools / Taco Hoekwater 236 LATEX on the road / Piet van Oostrum Graphics 247 A Brazilian Portuguese work on MetaPost, and how mathematics is embedded in it / Estev˜aoVin´ıcius Candia LATEX 251 LATEX news, issue 30, October 2019 / LATEX Project Team Methods 255 Understanding scientific documents with synthetic analysis on mathematical expressions and natural language / Takuto Asakura Fonts 257 Modern Type 3 fonts / Hans Hagen Multilingual 263 Typesetting the Bangla script in Unicode TEX engines—experiences and insights Document Processing / Md Qutub Uddin Sajib Typography 270 Typographers’ Inn / Peter Flynn Book Reviews 272 Book review: Hermann Zapf and the World He Designed: A Biography by Jerry Kelly / Barbara Beeton 274 Book review: Carol Twombly: Her brief but brilliant career in type design by Nancy Stock-Allen / Karl -

The Fontspec Package Font Selection for XƎLATEX and Lualatex
The fontspec package Font selection for XƎLATEX and LuaLATEX Will Robertson and Khaled Hosny [email protected] 2013/05/12 v2.3b Contents 7.5 Different features for dif- ferent font sizes . 14 1 History 3 8 Font independent options 15 2 Introduction 3 8.1 Colour . 15 2.1 About this manual . 3 8.2 Scale . 16 2.2 Acknowledgements . 3 8.3 Interword space . 17 8.4 Post-punctuation space . 17 3 Package loading and options 4 8.5 The hyphenation character 18 3.1 Maths fonts adjustments . 4 8.6 Optical font sizes . 18 3.2 Configuration . 5 3.3 Warnings .......... 5 II OpenType 19 I General font selection 5 9 Introduction 19 9.1 How to select font features 19 4 Font selection 5 4.1 By font name . 5 10 Complete listing of OpenType 4.2 By file name . 6 font features 20 10.1 Ligatures . 20 5 Default font families 7 10.2 Letters . 20 6 New commands to select font 10.3 Numbers . 21 families 7 10.4 Contextuals . 22 6.1 More control over font 10.5 Vertical Position . 22 shape selection . 8 10.6 Fractions . 24 6.2 Math(s) fonts . 10 10.7 Stylistic Set variations . 25 6.3 Miscellaneous font select- 10.8 Character Variants . 25 ing details . 11 10.9 Alternates . 25 10.10 Style . 27 7 Selecting font features 11 10.11 Diacritics . 29 7.1 Default settings . 11 10.12 Kerning . 29 7.2 Changing the currently se- 10.13 Font transformations . 30 lected features . -

Cyberarts 2021 Since Its Inception in 1987, the Prix Ars Electronica Has Been Honoring Creativity and Inno- Vativeness in the Use of Digital Media
Documentation of the Prix Ars Electronica 2021 Lavishly illustrated and containing texts by the prize-winning artists and statements by the juries that singled them out for recognition, this catalog showcases the works honored by the Prix Ars Electronica 2021. The Prix Ars Electronica is the world’s most time-honored media arts competition. Winners are awarded the coveted Golden Nica statuette. Ever CyberArts 2021 since its inception in 1987, the Prix Ars Electronica has been honoring creativity and inno- vativeness in the use of digital media. This year, experts from all over the world evaluated Prix Ars Electronica S+T+ARTS 3,158 submissions from 86 countries in four categories: Computer Animation, Artificial Intelligence & Life Art, Digital Musics & Sound Art, and the u19–create your world com - Prize ’21 petition for young people. The volume also provides insights into the achievements of the winners of the Isao Tomita Special Prize and the Ars Electronica Award for Digital Humanity. ars.electronica.art/prix STARTS Prize ’21 STARTS (= Science + Technology + Arts) is an initiative of the European Commission to foster alliances of technology and artistic practice. As part of this initiative, the STARTS Prize awards the most pioneering collaborations and results in the field of creativity 21 ’ and innovation at the intersection of science and technology with the arts. The STARTS Prize ‘21 of the European Commission was launched by Ars Electronica, BOZAR, Waag, INOVA+, T6 Ecosystems, French Tech Grande Provence, and the Frankfurt Book Fair. This Prize catalog presents the winners of the European Commission’s two Grand Prizes, which honor Innovation in Technology, Industry and Society stimulated by the Arts, and more of the STARTS Prize ‘21 highlights. -

Iso/Iec Jtc1 Sc2 Wg2 N3984
ISO/IEC JTC1 SC2 WG2 N3984 Notes on the naming of some characters proposed in the FCD of ISO/IEC 10646:2012 (3rd ed.) (JTC1/SC2/WG2 N3945, JTC1/SC2 N4168) Karl Pentzlin — 2011-02-02 This paper addresses the naming of the following characters proposed for inclusion: U+2E33 RAISED DOT U+2E34 RAISED COMMA (both proposed in JTC1/SC2/WG2 N3912) U+A78F LATIN LETTER GLOTTAL DOT (proposed in JTC1/SC2/WG2 N3567 as LATIN LETTER MIDDLE DOT) shown by the following excerpts from N3945: 1. Dots, Points, and "middle" and "raised" characters encoded in Unicode 6.0 (without script-specific ones and fullwidth/small forms; of similar characters within a block, a single character is selected as representative): Dots and Points: U+002E FULL STOP U+00B7 MIDDLE DOT U+02D9 DOT ABOVE U+0387 GREEK ANO TELEIA U+2024 ONE DOT LEADER U+2027 HYPHENATION POINT U+22C5 DOT OPERATOR U+2E31 WORD SEPARATOR MIDDLE DOT U+02D9 has the property Sk (Symbol, modifier), U+22C5 has Sm (Symbol, math), while all others have Po (Punctuation, other). U+A78F is proposed to have Lo (Letter, other). "Middle" and "raised" characters: U+02F4 MODIFIER LETTER MIDDLE GRAVE ACCENT U+2E0C LEFT RAISED OMISSION BRACKET (representing several similar characters in the same block) U+02F8 MODIFIER LETTER RAISED COLON U+A71B MODIFIER LETTER RAISED UP ARROW The following table will show these characters using some different widespread fonts. Font 002E 00B7 02D9 0387 2024 2027 22C5 2E31 02F4 2E0C 02F8 A71B Andron Mega Corpus x.E x·E x˙E α·Ε x․E x‧E x⋅E --- x˴E x⸌E x˸E --- Arial x.E x·E x˙E α·Ε x․E x‧E -

Translate's Localization Guide
Translate’s Localization Guide Release 0.9.0 Translate Jun 26, 2020 Contents 1 Localisation Guide 1 2 Glossary 191 3 Language Information 195 i ii CHAPTER 1 Localisation Guide The general aim of this document is not to replace other well written works but to draw them together. So for instance the section on projects contains information that should help you get started and point you to the documents that are often hard to find. The section of translation should provide a general enough overview of common mistakes and pitfalls. We have found the localisation community very fragmented and hope that through this document we can bring people together and unify information that is out there but in many many different places. The one section that we feel is unique is the guide to developers – they make assumptions about localisation without fully understanding the implications, we complain but honestly there is not one place that can help give a developer and overview of what is needed from them, we hope that the developer section goes a long way to solving that issue. 1.1 Purpose The purpose of this document is to provide one reference for localisers. You will find lots of information on localising and packaging on the web but not a single resource that can guide you. Most of the information is also domain specific ie it addresses KDE, Mozilla, etc. We hope that this is more general. This document also goes beyond the technical aspects of localisation which seems to be the domain of other lo- calisation documents. -

Applications and Innovations in Typeface Design for North American Indigenous Languages Julia Schillo, Mark Turin
Applications and innovations in typeface design for North American Indigenous languages Julia Schillo, Mark Turin To cite this version: Julia Schillo, Mark Turin. Applications and innovations in typeface design for North American Indige- nous languages. Book 2.0, Intellect Ltd, 2020, 10 (1), pp.71-98. 10.1386/btwo_00021_1. halshs- 03083476 HAL Id: halshs-03083476 https://halshs.archives-ouvertes.fr/halshs-03083476 Submitted on 22 Jan 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. BTWO 10 (1) pp. 71–98 Intellect Limited 2020 Book 2.0 Volume 10 Number 1 btwo © 2020 Intellect Ltd Article. English language. https://doi.org/10.1386/btwo_00021_1 Received 15 September 2019; Accepted 7 February 2020 Book 2.0 Intellect https://doi.org/10.1386/btwo_00021_1 10 JULIA SCHILLO AND MARK TURIN University of British Columbia 1 71 Applications and 98 innovations in typeface © 2020 Intellect Ltd design for North American 2020 Indigenous languages ARTICLES ABSTRACT KEYWORDS In this contribution, we draw attention to prevailing issues that many speakers orthography of Indigenous North American languages face when typing their languages, and typeface design identify examples of typefaces that have been developed and harnessed by histor- Indigenous ically marginalized language communities. -
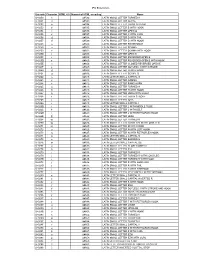
IPA Extensions
IPA Extensions Unicode Character HTML 4.0 Numerical HTML encoding Name U+0250 ɐ ɐ LATIN SMALL LETTER TURNED A U+0251 ɑ ɑ LATIN SMALL LETTER ALPHA U+0252 ɒ ɒ LATIN SMALL LETTER TURNED ALPHA U+0253 ɓ ɓ LATIN SMALL LETTER B WITH HOOK U+0254 ɔ ɔ LATIN SMALL LETTER OPEN O U+0255 ɕ ɕ LATIN SMALL LETTER C WITH CURL U+0256 ɖ ɖ LATIN SMALL LETTER D WITH TAIL U+0257 ɗ ɗ LATIN SMALL LETTER D WITH HOOK U+0258 ɘ ɘ LATIN SMALL LETTER REVERSED E U+0259 ə ə LATIN SMALL LETTER SCHWA U+025A ɚ ɚ LATIN SMALL LETTER SCHWA WITH HOOK U+025B ɛ ɛ LATIN SMALL LETTER OPEN E U+025C ɜ ɜ LATIN SMALL LETTER REVERSED OPEN E U+025D ɝ ɝ LATIN SMALL LETTER REVERSED OPEN E WITH HOOK U+025E ɞ ɞ LATIN SMALL LETTER CLOSED REVERSED OPEN E U+025F ɟ ɟ LATIN SMALL LETTER DOTLESS J WITH STROKE U+0260 ɠ ɠ LATIN SMALL LETTER G WITH HOOK U+0261 ɡ ɡ LATIN SMALL LETTER SCRIPT G U+0262 ɢ ɢ LATIN LETTER SMALL CAPITAL G U+0263 ɣ ɣ LATIN SMALL LETTER GAMMA U+0264 ɤ ɤ LATIN SMALL LETTER RAMS HORN U+0265 ɥ ɥ LATIN SMALL LETTER TURNED H U+0266 ɦ ɦ LATIN SMALL LETTER H WITH HOOK U+0267 ɧ ɧ LATIN SMALL LETTER HENG WITH HOOK U+0268 ɨ ɨ LATIN SMALL LETTER I WITH STROKE U+0269 ɩ ɩ LATIN SMALL LETTER IOTA U+026A ɪ ɪ LATIN LETTER SMALL CAPITAL I U+026B ɫ ɫ LATIN SMALL LETTER L WITH MIDDLE TILDE U+026C ɬ ɬ LATIN SMALL LETTER L WITH BELT U+026D ɭ ɭ LATIN SMALL LETTER L WITH RETROFLEX HOOK U+026E ɮ ɮ LATIN SMALL LETTER LEZH U+026F ɯ ɯ LATIN SMALL -

Iso/Iec Jtc1/Sc2/Wg2 N5148 L2/20-266
ISO/IEC JTC1/SC2/WG2 N5148 L2/20-266 2020-10-03 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Consolidated code chart including proposed phonetic and medieval characters Source: Michael Everson and Kirk Miller Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2020-01-03 The charts attached present the recommended code positions for a number of documents related to the addition of IPA, phonetic, and medievalist characters to the repertoire. Cells marked in yellow indicate characters which the script ad-hoc has not formally approved as of this date. 1 1AB0 Combining Diacritical Marks Extended 1AFF 1AB 1AC 1AD 1AE 1AF 0 1 $᫁ 1AC1 2 $᫂ 1AC2 3 $᫃ 1AC3 4 $᫄ 1AC4 5 $᫅ 1AC5 6 $᫆ 1AC6 7 $᫇ 1AC7 8 $᫈ 1AC8 9 $᫉ 1AC9 A $᫊ 1ACA B $᫋ 1ACB C $ᫌ 1ACC D $ᫍ 1ACD E F Printed using UniBook™ Printed: 04-Oct-2020 2 (http://www.unicode.org/unibook/) 1AC1 Combining Diacritical Marks Extended 1ACD IPA characters for disordered speech 1AC1 $᫁ COMBINING LEFT PARENTHESIS ABOVE LEFT → 1ABB $᪻ combining parentheses above 1AC2 $᫂ COMBINING LEFT PARENTHESIS ABOVE RIGHT 1AC3 $᫃ COMBINING LEFT PARENTHESIS BELOW LEFT → 1ABD $᪽ combining parentheses below 1AC4 $᫄ COMBINING LEFT PARENTHESIS BELOW RIGHT Additional diacritics 1AC5 $᫅ COMBINING SQUARE BRACKETS ABOVE 1AC6 $᫆ COMBINING NUMBER SIGN 1AC7 $᫇ COMBINING INVERTED DOUBLE ARCH ABOVE • used over letters with