Indian Model of Language Management Prof
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

Linguistic Survey of India Bihar
LINGUISTIC SURVEY OF INDIA BIHAR 2020 LANGUAGE DIVISION OFFICE OF THE REGISTRAR GENERAL, INDIA i CONTENTS Pages Foreword iii-iv Preface v-vii Acknowledgements viii List of Abbreviations ix-xi List of Phonetic Symbols xii-xiii List of Maps xiv Introduction R. Nakkeerar 1-61 Languages Hindi S.P. Ahirwal 62-143 Maithili S. Boopathy & 144-222 Sibasis Mukherjee Urdu S.S. Bhattacharya 223-292 Mother Tongues Bhojpuri J. Rajathi & 293-407 P. Perumalsamy Kurmali Thar Tapati Ghosh 408-476 Magadhi/ Magahi Balaram Prasad & 477-575 Sibasis Mukherjee Surjapuri S.P. Srivastava & 576-649 P. Perumalsamy Comparative Lexicon of 3 Languages & 650-674 4 Mother Tongues ii FOREWORD Since Linguistic Survey of India was published in 1930, a lot of changes have taken place with respect to the language situation in India. Though individual language wise surveys have been done in large number, however state wise survey of languages of India has not taken place. The main reason is that such a survey project requires large manpower and financial support. Linguistic Survey of India opens up new avenues for language studies and adds successfully to the linguistic profile of the state. In view of its relevance in academic life, the Office of the Registrar General, India, Language Division, has taken up the Linguistic Survey of India as an ongoing project of Government of India. It gives me immense pleasure in presenting LSI- Bihar volume. The present volume devoted to the state of Bihar has the description of three languages namely Hindi, Maithili, Urdu along with four Mother Tongues namely Bhojpuri, Kurmali Thar, Magadhi/ Magahi, Surjapuri. -
Advertisement 01 2020.Pdf
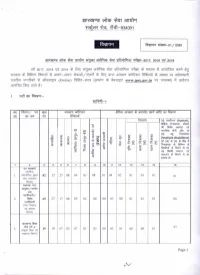
!ii1'<~O~ • ~ 3lIll\I~1 ti~<.YIx m, tRfi-834001 fcl$IQ"'1 ~-01 /2020 ~ 2017, 2018 -c;ct 2019 ~ ~ ~ ~ 00 l'lFc1<1'lfTlctlcRtlRT ~ l1TUfl1 ~ 3l1""llftict m ~ ~c:f5TX ~ ~ FcPwn ~ 3l(1lT-3l(1lT oo3lT/~ ~ ~ ID1{l 31Ra-TUT Cfilf?;C1lx RFcm<1'i ~ 3Tltl"R 'R ~ ~ ·iIlIRCfil ~ 3l1"'1C'11~'i (Online) fuf8f-~ (3WITrr ~ ~~f1I~c www.jpsc.gov.in 'R ~) -tr ~ ~~~tl 1. "4GT cpr ~:- ~-1 -wo fcI'+n<T/ ~ cgR 3lRefUT Q"> II cq IX ~ 3lRefUT q? 3Rfltcr ~ cmtC Cf5T fcrcRuT x:io Cf5T ~ ~ ~ ~ ("EI) ~ (Autism), ~ f.'t:Wifm!T, ~ t <tt ~ 3!af"I(!T ~ .......• .......• ~ ~ lfRfuq; ~, 3l'R, <IT I ~ f.'t:Wifm!T 0 I (~) <IS 0 .[ 0 § ~G (Multiple disabilities) a .[ i~ ~ ~ 15 ~ .......• un- (Cf» ~ (u) ~ <fi'q ~ 15 0 1Y3: 1 dtE ~ ~ d!:~"-' d!::£ f.'t:Wifm!T ~ ~ ~ ~ 0 i ~ I 4::: ~ We ~ ~ fi'R;r;f ~ m, 0 i ~ &: t ~ ~ <n;" ~ 3it:Ifq;f ~ ~ ~ fi'R;r;f ~ 3!T i mmrr tl 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 i3'l~ (~, I. ~WfR 82 32 27 08 04 03 08 01 04 02 0] 01 0] 0] \1m~ fcrwT) ~"'flN 3!TlJCffi' / ~ <'fCf) ~/ 2. ~ 65 27 17 06 05 04 06 00 03 00 01 0] 01 00 ~ (~ fcicI;m ~ 3!TCfR1 fcrwT) ~ ftre1T WIT Cf'f-2 0] 01 3. (¥ fuan ~ 39 19 07 02 07 01 03 00 02 01 00 00 X1Tffi(TI fcrwT) Page-I ,..V f.!mUR ~/ ~~ 4. ~ (J)fl1, 07 05 00 00 02 00 00 00 00 00 00 00 00 00 ~~ 1Iftre'fUT fcr:rrrT) ~ ~(~, 00 5. -

To Download JPSC Syllabus
Youth Power IAS Academy The JPSC Exam Pattern for the Combined Civil Service Exam comprises 3 stages: 1. Prelims – 2 Objective type papers for 200 Marks each. 2. Mains – 6 Descriptive type Papers, all the papers are compulsory 3. Personality Test – 100 Marks JPSC Syllabus for Prelims ● History of India ● Geography of India ● Indian Polity and Governance ● Economic and Sustainable development ● Science and Technology ● Jharkhand specific questions (General Awareness of its history, society, culture, and heritage) ● National and international current events. ● General questions of miscellaneous nature Compiled by Rishi Poddar JPSC Syllabus for Prelims- General Studies – Paper 1 Compiled by Rishi Poddar Compiled by Rishi Poddar General Studies – Paper 2 Compiled by Rishi Poddar Compiled by Rishi Poddar Important suggestions regarding JPSC Syllabus for prelims: 1. Under history, candidates need to focus on economic, social and political aspects of Jharkhand 2. Under Geography, candidates have to focus on Geography of Jharkhand 3. To handle questions on Science and Technology, candidates need not require any specialisation. JPSC Exam Pattern for Mains Candidates who have successfully cleared Prelims stage will be eligible for JPSC Mains. Under OFFICIAL NOTIFICATIONS the number of candidates selected for Mains will be equal to 15 times the total number of vacancies. JPSC Syllabus for Mains There are no optional papers in the JPSC Mains Syllabus. The details of JPSC Syllabus for Mains is given below: ● Paper I: General Hindi and General English (100 Marks) ● Paper-II: Language and Literature (150 Marks) ● Paper III: Social Sciences, History and Geography (200 Marks) ● Paper IV: Indian Constitution, Polity, Public Administration and Good governance (200 Marks) ● Paper V: Indian Economy, Globalization, and Sustainable development (200 Marks) ● Paper VI: General Sciences, Environment & Technology Development (200 Marks) Compiled by Rishi Poddar Paper 1 (General Hindi and General English) Out of 100 marks, every candidate will have to secure only 30 marks. -

2001 Presented Below Is an Alphabetical Abstract of Languages A
Hindi Version Home | Login | Tender | Sitemap | Contact Us Search this Quick ABOUT US Site Links Hindi Version Home | Login | Tender | Sitemap | Contact Us Search this Quick ABOUT US Site Links Census 2001 STATEMENT 1 ABSTRACT OF SPEAKERS' STRENGTH OF LANGUAGES AND MOTHER TONGUES - 2001 Presented below is an alphabetical abstract of languages and the mother tongues with speakers' strength of 10,000 and above at the all India level, grouped under each language. There are a total of 122 languages and 234 mother tongues. The 22 languages PART A - Languages specified in the Eighth Schedule (Scheduled Languages) Name of language and Number of persons who returned the Name of language and Number of persons who returned the mother tongue(s) language (and the mother tongues mother tongue(s) language (and the mother tongues grouped under each grouped under each) as their mother grouped under each grouped under each) as their mother language tongue language tongue 1 2 1 2 1 ASSAMESE 13,168,484 13 Dhundhari 1,871,130 1 Assamese 12,778,735 14 Garhwali 2,267,314 Others 389,749 15 Gojri 762,332 16 Harauti 2,462,867 2 BENGALI 83,369,769 17 Haryanvi 7,997,192 1 Bengali 82,462,437 18 Hindi 257,919,635 2 Chakma 176,458 19 Jaunsari 114,733 3 Haijong/Hajong 63,188 20 Kangri 1,122,843 4 Rajbangsi 82,570 21 Khairari 11,937 Others 585,116 22 Khari Boli 47,730 23 Khortha/ Khotta 4,725,927 3 BODO 1,350,478 24 Kulvi 170,770 1 Bodo/Boro 1,330,775 25 Kumauni 2,003,783 Others 19,703 26 Kurmali Thar 425,920 27 Labani 22,162 4 DOGRI 2,282,589 28 Lamani/ Lambadi 2,707,562 -

A Language Without a State: Early Histories of Maithili Literature
A LANGUAGE WITHOUT A STATE: EARLY HISTORIES OF MAITHILI LITERATURE Lalit Kumar When we consider the more familiar case of India’s new national language, Hindi, in relation to its so-called dialects such as Awadhi, Brajbhasha, and Maithili, we are confronted with the curious image of a thirty-year-old mother combing the hair of her sixty-year-old daughters. —Sitanshu Yashaschandra The first comprehensive history of Maithili literature was written by Jayakanta Mishra (1922-2009), a professor of English at Allahabad University, in two volumes in 1949 and 1950, respectively. Much before the publication of this history, George Abraham Grierson (1851- 1941), an ICS officer posted in Bihar, had first attempted to compile all the available specimens of Maithili literature in a book titled Maithili Chrestomathy (1882).1 This essay analyses Jayakanta Mishra’s History in dialogue with Grierson’s Chrestomathy, as I argue that the first history of Maithili literature was the culmination of the process of exploration of literary specimens initiated by Grierson, with the stated objective of establishing the identity of Maithili as an independent modern Indian language.This journey from Chrestomathy to History, or from Grierson to Mishra,helps us understand not only the changes Maithili underwent in more than sixty years but also comprehend the centrality of the language-dialect debate in the history of Maithili literature. A rich literary corpus of Maithili created a strong ground for its partial success, not in the form of Mithila getting the status of a separate state, but in the official recognition by the Sahitya Akademi in 1965 and by the Eighth Schedule of the Indian Constitution in 2003. -

Map by Steve Huffman; Data from World Language Mapping System
Svalbard Greenland Jan Mayen Norwegian Norwegian Icelandic Iceland Finland Norway Swedish Sweden Swedish Faroese FaroeseFaroese Faroese Faroese Norwegian Russia Swedish Swedish Swedish Estonia Scottish Gaelic Russian Scottish Gaelic Scottish Gaelic Latvia Latvian Scots Denmark Scottish Gaelic Danish Scottish Gaelic Scottish Gaelic Danish Danish Lithuania Lithuanian Standard German Swedish Irish Gaelic Northern Frisian English Danish Isle of Man Northern FrisianNorthern Frisian Irish Gaelic English United Kingdom Kashubian Irish Gaelic English Belarusan Irish Gaelic Belarus Welsh English Western FrisianGronings Ireland DrentsEastern Frisian Dutch Sallands Irish Gaelic VeluwsTwents Poland Polish Irish Gaelic Welsh Achterhoeks Irish Gaelic Zeeuws Dutch Upper Sorbian Russian Zeeuws Netherlands Vlaams Upper Sorbian Vlaams Dutch Germany Standard German Vlaams Limburgish Limburgish PicardBelgium Standard German Standard German WalloonFrench Standard German Picard Picard Polish FrenchLuxembourgeois Russian French Czech Republic Czech Ukrainian Polish French Luxembourgeois Polish Polish Luxembourgeois Polish Ukrainian French Rusyn Ukraine Swiss German Czech Slovakia Slovak Ukrainian Slovak Rusyn Breton Croatian Romanian Carpathian Romani Kazakhstan Balkan Romani Ukrainian Croatian Moldova Standard German Hungary Switzerland Standard German Romanian Austria Greek Swiss GermanWalser CroatianStandard German Mongolia RomanschWalser Standard German Bulgarian Russian France French Slovene Bulgarian Russian French LombardRomansch Ladin Slovene Standard -

Map by Steve Huffman Data from World Language Mapping System 16
Tajiki Tajiki Tajiki Shughni Southern Pashto Shughni Tajiki Wakhi Wakhi Wakhi Mandarin Chinese Sanglechi-Ishkashimi Sanglechi-Ishkashimi Wakhi Domaaki Sanglechi-Ishkashimi Khowar Khowar Khowar Kati Yidgha Eastern Farsi Munji Kalasha Kati KatiKati Phalura Kalami Indus Kohistani Shina Kati Prasuni Kamviri Dameli Kalami Languages of the Gawar-Bati To rw al i Chilisso Waigali Gawar-Bati Ushojo Kohistani Shina Balti Parachi Ashkun Tregami Gowro Northwest Pashayi Southwest Pashayi Grangali Bateri Ladakhi Northeast Pashayi Southeast Pashayi Shina Purik Shina Brokskat Aimaq Parya Northern Hindko Kashmiri Northern Pashto Purik Hazaragi Ladakhi Indian Subcontinent Changthang Ormuri Gujari Kashmiri Pahari-Potwari Gujari Bhadrawahi Zangskari Southern Hindko Kashmiri Ladakhi Pangwali Churahi Dogri Pattani Gahri Ormuri Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Southern Pashto Ladakhi Central Pashto Khams Tibetan Kullu Pahari KinnauriBhoti Kinnauri Sunam Majhi Western Panjabi Mandeali Jangshung Tukpa Bilaspuri Chitkuli Kinnauri Mahasu Pahari Eastern Panjabi Panang Jaunsari Western Balochi Southern Pashto Garhwali Khetrani Hazaragi Humla Rawat Central Tibetan Waneci Rawat Brahui Seraiki DarmiyaByangsi ChaudangsiDarmiya Western Balochi Kumaoni Chaudangsi Mugom Dehwari Bagri Nepali Dolpo Haryanvi Jumli Urdu Buksa Lowa Raute Eastern Balochi Tichurong Seke Sholaga Kaike Raji Rana Tharu Sonha Nar Phu ChantyalThakali Seraiki Raji Western Parbate Kham Manangba Tibetan Kathoriya Tharu Tibetan Eastern Parbate Kham Nubri Marwari Ts um Gamale Kham Eastern -

Manual of Instructions for Editing, Coding and Record Management of Individual Slips
For offiCial use only CENSUS OF INDIA 1991 MANUAL OF INSTRUCTIONS FOR EDITING, CODING AND RECORD MANAGEMENT OF INDIVIDUAL SLIPS PART-I MASTER COPY-I OFFICE OF THE REGISTRAR GENERAL&. CENSUS COMMISSIONER. INOI.A MINISTRY OF HOME AFFAIRS NEW DELHI CONTENTS Pages GENERAlINSTRUCnONS 1-2 1. Abbreviations used for urban units 3 2. Record Management instructions for Individual Slips 4-5 3. Need for location code for computer processing scheme 6-12 4. Manual edit of Individual Slip 13-20 5. Code structure of Individual Slip 21-34 Appendix-A Code list of States/Union Territories 8a Districts 35-41 Appendix-I-Alphabetical list of languages 43-64 Appendix-II-Code list of religions 66-70 Appendix-Ill-Code list of Schedules Castes/Scheduled Tribes 71 Appendix-IV-Code list of foreign countries 73-75 Appendix-V-Proforma for list of unclassified languages 77 Appendix-VI-Proforma for list of unclassified religions 78 Appendix-VII-Educational levels and their tentative equivalents. 79-94 Appendix-VIII-Proforma for Central Record Register 95 Appendix-IX-Profor.ma for Inventory 96 Appendix-X-Specimen of Individual SHp 97-98 Appendix-XI-Statement showing number of Diatricts/Tehsils/Towns/Cities/ 99 U.AB.lC.D. Blocks in each State/U.T. GENERAL INSTRUCTIONS This manual contains instructions for editing, coding and record management of Individual Slips upto the stage of entry of these documents In the Direct Data Entry System. For the sake of convenient handling of this manual, it has been divided into two parts. Part·1 contains Management Instructions for handling records, brief description of thf' process adopted for assigning location code, the code structure which explains the details of codes which are to be assigned for various entries in the Individual Slip and the edit instructions. -

A Less Resourced Language Spoken in the State of Jharkhand, India
Dialectologia 25 (2020), 25-43. ISSN: 2013-2247 Received 21 September 2018. Accepted 21 November 2018. DESIGNING A LINGUISTIC PROFILE OF KHORTHA: A LESS RESOURCED LANGUAGE SPOKEN IN THE STATE OF JHARKHAND, INDIA Atul AMAN1, Niladri Sekhar DASH1 & Jayashree CHAKRABORTY2 Linguistic Research Unit, Indian Statistical Institute, Kolkata1** Dept. of HSS, Indian Institute of Technology, Kharagpur2 ** [email protected] / [email protected] / [email protected] Abstract This paper describes the linguistic outline of Khortha language, which is spoken in the state of Jharkhand, India. Khortha is the second most spoken language after Hindi in the state of Jharkhand, with approximately 80 million speakers (As per the Govt. of India, census reports 2011). The paucity of the language resources in Khortha played a vital role in motivating us for the present work. The methodology adopted for the present study comprises linguistic field surveys (Dash & Aman 2015) and reviews on the earlier literature of Khortha. The current status and demographic profile of Khortha suggest its usage as a link language among the other indigenous language communities (i.e. Munda, Bedia, Kurmali, etc.) as well. The scope (usage) of the Khortha language within the various domains (i.e. administration, education, mass media, social divisions and religion, judiciary and interpersonal communication), as discussed in the paper, gives a clear idea of its usage and linguistic identity. This paper can be a helpful resource for the researchers in order to portray the current linguistic status of the language. Keywords Khortha, language resources, earlier literature, demographic profile, linguistic identity ** Linguistic Research Unit, Indian Statistical Institute, 203, B.T Road, Kolkata, 700108, West Bengal, India. -

Nepal Early Grade Reading Materials Assessment
NEPAL EARLY GRADE READING MATERIALS ASSESSMENT A Report Submitted to United States Agency for International Development (USAID) Nepal Maharajgunj, Kathmandu, Nepal Submitted by Research Management Cell (RMC) Kathmandu Shiksha Campus (KSC) Ramshah Path, Kathmandu, Nepal May 9, 2014 1 Study Team Core Team SN Name of the Consultant Position/Area of Expertise 1 Prof. Dr Prem Narayan Aryal Team Leader and Early Childhood Development Expert 2 Prof. Dr Yogendra Prasad Yadava Team Member and Linguist 3 Prof. Dr Ram Krishna Maharjan Team Member and Educationist 4 Prof. Dr Hemang Raj Adhikari Team Member and Nepali Language Subject Expert 5 Dr Sushan Acharya Team Member and Gender, Child and Social Inclusion Expert 6 Mr Karnakhar Khatiwada Team Member and Linguist 7 Mr Bhagwan Aryal Team Member and Educationist 8 Mr Shatrughan Prasad Gupta Project Manager and Educationist Advisory Input - Prof. Dr Basu Dev Kafle Subject Experts (Evaluators) SN Name of the Nepali Language Name of the Mother Tongue Language Subject Experts Subject Experts 1 Prof. Dr Hemang Raj Nepali Mr Surya Prasad Yadav Maithili Adhikari 2 Prof. Dr Madhav Bhattarai Nepali Mr Jeevan Kumar Maharjan Nepal Bhasa 3 Prof. Dr Kedar Sharma Nepali Mr Padam Rai Bantawa 4 Prof. Maheshwor Neupane Nepali Mr Purna Bahadur Gharti Magar Athara Magarat 5 Prof. Dr Sanat Kumar Wasti Nepali Mr Jai Prakash Lal Srivastav Awadhi 2 6 Dr Madhav Prasad Poudel Nepali Mr Khenpo Gyurme Tsultrim Mugali 7 Mr Diwakar Dhungel Nepali Ms Bagdevi Rai Chamling 8 Mr Ganesh Prasad Bhattarai Nepali Mr Krishna Raj Sarbahari Tharu 9 Mr Hari Prasad Niraula Nepali Mr Rajesh Prasad Sah Bajjika 10 Ms Rajni Dhimal Nepali Dr Lal-Shyãkarelu Rapacha Sunuwar 11 Prof. -

International Journal of the Sociology of Language
IJSL 2018; 252: 97–123 Hannah Carlan* “In the mouth of an aborigine”: language ideologies and logics of racialization in the Linguistic Survey of India https://doi.org/10.1515/ijsl-2018-0016 Abstract: The Linguistic Survey of India (LSI),editedandcompiledbyGeorge Abraham Grierson, was the first systematic effort by the British colonial gov- ernment to document the spoken languages and dialects of India. While Grierson advocated an approach to philology that dismissed the affinity of language to race, the LSI mobilizes a complex, intertextualsetofracializing discourses that form the ideological ground upon which representations of language were constructed and naturalized. I analyze a sub-set of the LSI’s volumes in order to demonstrate how Grierson’s linguistic descriptions and categorizations racialize minority languages and their speakers as corrupt, impure, and uncivilized. I highlight how semiotic processes in the text con- struct speakers as possessing essential “ethnic” characteristics that are seen as indexical of naturalized linguistic differences. I argue that metapragmatic statements within descriptions of languages and dialects are made possible by ethnological discourses that ultimately reinforce an indexical relationship between language and race. This analysis of the survey sheds light on the centrality of language in colonial constructions of social difference in India, as well as the continued importance of language as a tool for legitimating claims for political recognition in postcolonial India. Keywords: language surveys, language ideologies, racialization, British colonialism, India 1 Introduction The Linguistic Survey of India (1903–1928), hereafter the LSI, was the first attempt to capture the spoken languages and dialects of British India as part of the wider goal of the colonial government to learn, through bureaucratic documentation, about the social makeup of its subjects.