A Probabilistic Bias in the Morphology of Verbal Agreement
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Toward the Reconstruction of Proto-Algonquian-Wakashan. Part 3: the Algonquian-Wakashan 110-Item Wordlist
Sergei L. Nikolaev Institute of Slavic studies of the Russian Academy of Sciences (Moscow/Novosibirsk); [email protected] Toward the reconstruction of Proto-Algonquian-Wakashan. Part 3: The Algonquian-Wakashan 110-item wordlist In the third part of my complex study of the historical relations between several language families of North America and the Nivkh language in the Far East, I present an annotated demonstration of the comparative data that was used in the lexicostatistical calculations to determine the branching and approximate glottochronological dating of Proto-Algonquian- Wakashan and its offspring; because of volume considerations, this data could not be in- cluded in the previous two parts of the present work and has to be presented autonomously. Additionally, several new Proto-Algonquian-Wakashan and Proto-Nivkh-Algonquian roots have been set up in this part of study. Lexicostatistical calculations have been conducted for the following languages: the reconstructed Proto-North Wakashan (approximately dated to ca. 800 AD) and modern or historically attested variants of Nootka (Nuuchahnulth), Amur Nivkh, Sakhalin Nivkh, Western Abenaki, Miami-Peoria, Fort Severn Cree, Wiyot, and Yurok. Keywords: Algonquian-Wakashan languages, Nivkh-Algonquian languages, Algic languages, Wakashan languages, Chimakuan-Wakashan languages, Nivkh language, historical phonol- ogy, comparative dictionary, lexicostatistics. The classification and preliminary glottochronological dating of Algonquian-Wakashan currently remain the same as presented in Nikolaev 2015a, Fig. 1 1. That scheme was generated based on the lexicostatistical analysis of 110-item basic word lists2 for one reconstructed (Proto-Northern Wakashan, ca. 800 A.D.) and several modern Algonquian-Wakashan lan- guages, performed with the aid of StarLing software 3. -

Deixis and Reference Tracing in Tsova-Tush (PDF)
DEIXIS AND REFERENCE TRACKING IN TSOVA-TUSH A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAIʻI AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN LINGUISTICS MAY 2020 by Bryn Hauk Dissertation committee: Andrea Berez-Kroeker, Chairperson Alice C. Harris Bradley McDonnell James N. Collins Ashley Maynard Acknowledgments I should not have been able to finish this dissertation. In the course of my graduate studies, enough obstacles have sprung up in my path that the odds would have predicted something other than a successful completion of my degree. The fact that I made it to this point is a testament to thekind, supportive, wise, and generous people who have picked me up and dusted me off after every pothole. Forgive me: these thank-yous are going to get very sappy. First and foremost, I would like to thank my Tsova-Tush host family—Rezo Orbetishvili, Nisa Baxtarishvili, and of course Tamar and Lasha—for letting me join your family every summer forthe past four years. Your time, your patience, your expertise, your hospitality, your sense of humor, your lovingly prepared meals and generously poured wine—these were the building blocks that supported all of my research whims. My sincerest gratitude also goes to Dantes Echishvili, Revaz Shankishvili, and to all my hosts and friends in Zemo Alvani. It is possible to translate ‘thank you’ as მადელ შუნ, but you have taught me that gratitude is better expressed with actions than with set phrases, sofor now I will just say, ღაზიშ ხილჰათ, ბედნიერ ხილჰათ, მარშმაკიშ ხილჰათ.. -

Expanding the JHU Bible Corpus for Machine Translation of the Indigenous Languages of North America
Expanding the JHU Bible Corpus for Machine Translation of the Indigenous Languages of North America Garrett Nicolai, Edith Coates, Ming Zhang and Miikka Silfverberg Department of Linguistics University of British Columbia Vancouver, Canada [email protected], [email protected], [email protected], [email protected] Abstract ence of the language communities. We demonstrate the usefulness of our Indigenous parallel corpus by build- We present an extension to the JHU Bible ing multilingual neural machine translation systems for corpus, collecting and normalizing more than North American Indigenous languages. Multilingual thirty Bible translations in thirty Indigenous training is shown to be beneficial especially for the languages of North America. These exhibit a most resource-poor languages in our corpus which lack wide variety of interesting syntactic and mor- complete Bible translations. phological phenomena that are understudied in the computational community. Neural transla- 2 Corpus Construction tion experiments demonstrate significant gains obtained through cross-lingual, many-to-many The Bible is perhaps unique as a parallel text. Partial translation, with improvements of up to 8.4 translations exist in more languages than any other text 2 BLEU over monolingual models for extremely (Mayer and Cysouw, 2014). Furthermore, for nearly low-resource languages. 500 years, the Bible has had a canonical hierarchical structure - the Bible is made up of 66 books, each of 1 Introduction which contains a number of chapters, which are, in turn, broken down into verses. Each verse corresponds In 2019, Johns Hopkins University collated a corpus of to a short segment – often no more than a sentence. -
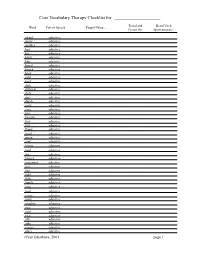
250 Word List
Core Vocabulary Therapy Checklist for ____________________ Tested and Heard Used Word Part of Speech Taught Using ... Passed On: Spontaneously: afraid adjective angry adjective another adjective bad adjective big adjective black adjective blue adjective bored adjective brown adjective busy adjective cold adjective cool adjective dark adjective different adjective dirty adjective dry adjective dumb adjective early adjective easy adjective fast adjective favorite adjective first adjective full adjective funny adjective good adjective green adjective grey adjective happy adjective hard adjective hot adjective hungry adjective important adjective last adjective late adjective light adjective little adjective lonely adjective long adjective mad adjective many adjective more adjective naughty adjective new adjective next adjective nice adjective old adjective only adjective orange adjective other adjective ©VanTatenhove, 2001 page 1 Core Vocabulary Therapy Checklist for ____________________ Word Part of Speech Taught Using ... Tested and Heard Used Passed On: Spontaneously: pink adjective purple adjective real adjective red adjective right adjective sad adjective same adjective sick adjective silly adjective sure adjective thirsty adjective tired adjective wet adjective white adjective wrong adjective yellow adjective adjective adjective adjective again adverb all right adverb almost adverb already adverb always adverb away adverb backwards adverb forward adverb here adverb indoors adverb just adverb maybe adverb much adverb never adverb not -

Remarks on the History of the Indo-European Infinitive Dorothy Disterheft University of South Carolina - Columbia, [email protected]
University of South Carolina Scholar Commons Faculty Publications Linguistics, Program of 1981 Remarks on the History of the Indo-European Infinitive Dorothy Disterheft University of South Carolina - Columbia, [email protected] Follow this and additional works at: https://scholarcommons.sc.edu/ling_facpub Part of the Linguistics Commons Publication Info Published in Folia Linguistica Historica, Volume 2, Issue 1, 1981, pages 3-34. Disterheft, D. (1981). Remarks on the History of the Indo-European Infinitive. Folia Linguistica Historica, 2(1), 3-34. DOI: 10.1515/ flih.1981.2.1.3 © 1981 Societas Linguistica Europaea. This Article is brought to you by the Linguistics, Program of at Scholar Commons. It has been accepted for inclusion in Faculty Publications by an authorized administrator of Scholar Commons. For more information, please contact [email protected]. Foli.lAfl//ui.tfcoFolia Linguistica HfltorlcGHistorica II/III/l 'P'P.pp. 8-U3—Z4 © 800£etruSocietae lAngu,.ticaLinguistica Etlropaea.Evropaea, 1981lt)8l REMARKSBEMARKS ONON THETHE HISTORYHISTOKY OFOF THETHE INDO-EUROPEANINDO-EUROPEAN INFINITIVEINFINITIVE i DOROTHYDOROTHY DISTERHEFTDISTERHEFT I 1.1. INTRODUCTIONINTRODUCTION WithWith thethe exceptfonexception ofof Indo-IranianIndo-Iranian (Ur)(Hr) andand CelticCeltic allall historicalhistorical Indo-EuropeanIndo-European (IE)(IE) subgroupssubgroups havehave a morphologicalIymorphologically distinctdistinct II infinitive.Infinitive. However,However, nono singlesingle proto-formproto-form cancan bebe reconstructedreconstructed -

Navajo Verb Stem Position and the Bipartite Structure of the Navajo
678 REMARKSANDREPLIES NavajoVerb Stem Positionand the BipartiteStructure of the NavajoConjunct Sector Ken Hale TheNavajo verb stem appears at the rightmost edge of the verb word. Innumerouscases it forms a lexicalconstituent with a preverb,occur- ringat theleftmost edge of thesurface verb word, much in themanner ofDutchand German verb-particle arrangements in verb-secondfinite clauses.In Navajothe initial and finalpositions are separated by eight morphemeorder ‘ ‘slots’’ recognizedin the Athabaskan literature (and describedin detail for Navajo in Young and Morgan 1987). A phono- logicalsolution to this and a numberof otherdeep-surface disparities isexploredhere, based on theinsights of earlierworks on theNavajo verb,including Speas 1984, 1990, McDonough 1996, 2000, and Rice 1989, 2000. Keywords: verbmorphology, morphosyntactic disparity, spell-out, Navajo,Athabaskan 1Verb Stem Position TheNavajo verb stem forms asinglelexical constituent with the prefixal, particle-like category called preverb inthe Athabaskan linguistic literature (see Rice2000). However, like particle- verbcombinations in Dutchand German verb-second clauses, the parts of thisconstituent in the Navajocounterpart are separated in the surface forms ofverbal projections in syntax. In the Navajoversion of thisarrangement, the preverb occupies the leftmost position in the verb word, andthe verb stem occupies the rightmost position. TheNavajo verb in (1) canbe used to illustrate the phenomenon. The verb is segmented intoits various parts in (2), and the components are identified in slightly greater detail in (3). (1) Sila´o t’o´o´’go´o´ ch’´õ shidinõ´daøzh.(Young and Morgan 1987:283) ‘Thepoliceman jerked me outdoors (to get me out of afight).’ (2) ch’´õ sh d n-´ daøzh PreverbObject Qualifier Mode/ SubjVoice V (stem) Iwishto dedicate thisarticle totheNavajo Language Academy, asmall groupof linguists and teachers devotedto Navajolanguage research andeducation. -

33 Contact and North American Languages
9781405175807_4_033 1/15/10 5:37 PM Page 673 33 Contact and North American Languages MARIANNE MITHUN Languages indigenous to the Americas offer some good opportunities for inves- tigating effects of contact in shaping grammar. Well over 2000 languages are known to have been spoken at the time of first contacts with Europeans. They are not a monolithic group: they fall into nearly 200 distinct genetic units. Yet against this backdrop of genetic diversity, waves of typological similarities suggest pervasive, longstanding multilingualism. Of particular interest are similarities of a type that might seem unborrowable, patterns of abstract structure without shared substance. The Americas do show the kinds of contact effects common elsewhere in the world. There are some strong linguistic areas, on the Northwest Coast, in California, in the Southeast, and in the Pueblo Southwest of North America; in Mesoamerica; and in Amazonia in South America (Bright 1973; Sherzer 1973; Haas 1976; Campbell, Kaufman, & Stark 1986; Thompson & Kinkade 1990; Silverstein 1996; Campbell 1997; Mithun 1999; Beck 2000; Aikhenvald 2002; Jany 2007). Numerous additional linguistic areas and subareas of varying sizes and strengths have also been identified. In some cases all domains of language have been affected by contact. In some, effects are primarily lexical. But in many, there is surprisingly little shared vocabulary in contrast with pervasive structural parallelism. The focus here will be on some especially deeply entrenched structures. It has often been noted that morphological structure is highly resistant to the influence of contact. Morphological similarities have even been proposed as better indicators of deep genetic relationship than the traditional comparative method. -

Unity and Diversity in Grammaticalization Scenarios
Unity and diversity in grammaticalization scenarios Edited by Walter Bisang Andrej Malchukov language Studies in Diversity Linguistics 16 science press Studies in Diversity Linguistics Chief Editor: Martin Haspelmath In this series: 1. Handschuh, Corinna. A typology of marked-S languages. 2. Rießler, Michael. Adjective attribution. 3. Klamer, Marian (ed.). The Alor-Pantar languages: History and typology. 4. Berghäll, Liisa. A grammar of Mauwake (Papua New Guinea). 5. Wilbur, Joshua. A grammar of Pite Saami. 6. Dahl, Östen. Grammaticalization in the North: Noun phrase morphosyntax in Scandinavian vernaculars. 7. Schackow, Diana. A grammar of Yakkha. 8. Liljegren, Henrik. A grammar of Palula. 9. Shimelman, Aviva. A grammar of Yauyos Quechua. 10. Rudin, Catherine & Bryan James Gordon (eds.). Advances in the study of Siouan languages and linguistics. 11. Kluge, Angela. A grammar of Papuan Malay. 12. Kieviet, Paulus. A grammar of Rapa Nui. 13. Michaud, Alexis. Tone in Yongning Na: Lexical tones and morphotonology. 14. Enfield, N. J (ed.). Dependencies in language: On the causal ontology of linguistic systems. 15. Gutman, Ariel. Attributive constructions in North-Eastern Neo-Aramaic. 16. Bisang, Walter & Andrej Malchukov (eds.). Unity and diversity in grammaticalization scenarios. ISSN: 2363-5568 Unity and diversity in grammaticalization scenarios Edited by Walter Bisang Andrej Malchukov language science press Walter Bisang & Andrej Malchukov (eds.). 2017. Unity and diversity in grammaticalization scenarios (Studies in Diversity Linguistics -

California Indian Languages
SUB Hamburg B/112081 CALIFORNIA INDIAN LANGUAGES VICTOR GOLLA UNIVERSITY OF CALIFORNIA PRESS Berkeley Los Angeles London CONTENTS PREFACE ix PART THREE PHONETIC ORTHOGRAPHY xiii Languages and Language Families Algic Languages / 61 PART ONE Introduction: Defining California as a 3.1 California Algic Languages (Ritwan) / 61 Sociolinguistic Area 3.2 Wiyot / 62 3.3 Yurok / 65 1.1 Diversity / 1 Athabaskan (Na-Dene) Languages / 68 1.2 Tribelet and Language / 2 3.4 The Pacific Coast Athabaskan Languages / 68 1.3 Symbolic Function of California Languages / 4 3.5 Lower Columbia Athabaskan 1.4 Languages and Migration / 5 (Kwalhioqua-Tlatskanai) / 69 1.5 Multilingualism / 6 3.6 Oregon Athabaskan Languages / 70 1.6 Language Families and Phyla / 8 3.7 California Athabaskan Languages / 76 Hokan Languages / 82 PART TWO 3.8 The Hokan Phylum / 82 History of Study 3.9 Karuk / 84 3.10 Chimariko / 87 3.11 Shastan Languages / 90 Before Linguistics / 12 3.12 Palaihnihan Languages / 95 2.1 Earliest Attestations / 12 3.13 Yana / 100 2.2 Jesuit Missionaries in Baja California / 12 3.14 Washo / 102 2.3 Franciscans in Alta California / 14 3.15 Porno Languages / 105 2.4 Visitors and Collectors, 1780-1880 / 22 3.16 Esselen / 112 3.17 Salinan / 114 Linguistic Scholarship / 32 3.18 Yuman Languages / 117 3.19 Cochimi and the Cochimi-Yuman Relationship / 125 2.5 Early Research Linguistics, 1865-1900 / 32 3.20 Seri / 126 2.6 The Kroeber Era, 1900 to World War II / 35 2.7 Independent Scholars, 1900-1940 / 42 Penutian Languages / 128 2.8 Structural Linguists / 49 2.9 The -

[.35 **Natural Language Processing Class Here Computational Linguistics See Manual at 006.35 Vs
006 006 006 DeweyiDecimaliClassification006 006 [.35 **Natural language processing Class here computational linguistics See Manual at 006.35 vs. 410.285 *Use notation 019 from Table 1 as modified at 004.019 400 DeweyiDecimaliClassification 400 400 DeweyiDecimali400Classification Language 400 [400 [400 *‡Language Class here interdisciplinary works on language and literature For literature, see 800; for rhetoric, see 808. For the language of a specific discipline or subject, see the discipline or subject, plus notation 014 from Table 1, e.g., language of science 501.4 (Option A: To give local emphasis or a shorter number to a specific language, class in 410, where full instructions appear (Option B: To give local emphasis or a shorter number to a specific language, place before 420 through use of a letter or other symbol. Full instructions appear under 420–490) 400 DeweyiDecimali400Classification Language 400 SUMMARY [401–409 Standard subdivisions and bilingualism [410 Linguistics [420 English and Old English (Anglo-Saxon) [430 German and related languages [440 French and related Romance languages [450 Italian, Dalmatian, Romanian, Rhaetian, Sardinian, Corsican [460 Spanish, Portuguese, Galician [470 Latin and related Italic languages [480 Classical Greek and related Hellenic languages [490 Other languages 401 DeweyiDecimali401Classification Language 401 [401 *‡Philosophy and theory See Manual at 401 vs. 121.68, 149.94, 410.1 401 DeweyiDecimali401Classification Language 401 [.3 *‡International languages Class here universal languages; general -

Overt Pronouon Constraint Effects in Second Lanugage Japanese
Overt Pronoun Constraint effects in second language Japanese Tokiko Okuma Department of Linguistics McGill University Montreal, Quebec April 2, 2015 A thesis submitted to McGill University in partial fulfilment of the requirements of the degree of DOCTOR OF PHILOSOPHY © Copyright by Tokiko Okuma 2014 All Rights Reserved ABSTRACT This dissertation investigates the applicability of the Full Transfer/Full Access hypothesis (FT/FA) (Schwartz & Sprouse, 1994, 1996) by investigating the interpretation of the Japanese pronoun (kare ‘he’) by adult English and Spanish speaking learners of Japanese. The Japanese, Spanish, and English languages differ with respect to interpretive properties of pronouns. In Japanese and Spanish, overt pronouns disallow a bound variable interpretation in subject and object positions. By contrast, In English, overt pronouns may have a bound variable interpretation in these positions. This is called the Overt Pronoun Constraint (OPC) (Montalbetti, 1984). The FT/FA model suggests that the initial state of L2 grammar is the end state of L1 grammar and that the restructuring of L2 grammar occurs with L2 input. This hypothesis predicts that L1 English speakers of L2 Japanese would initially allow a bound variable interpretation of Japanese pronouns in subject and object positions, transferring from their L1s. Nevertheless, they will successfully come to disallow a bound variable interpretation as their proficiency improves. In contrast, L1 Spanish speakers of L2 Japanese would correctly disallow a bound variable interpretation of Japanese pronouns in subject and object positions from the beginning. In order to test these predictions, L1 English and L1 Spanish speakers of L2 Japanese at intermediate and advanced levels of proficiency were compared with native Japanese speakers in their interpretations of pronouns with quantified i antecedents in two tasks. -

Preverbs and Particles in Algonquian
Preverbs and Particles in Algonquian DAVID H. PENTLAND University of Manitoba In his comparative Algonquian sketch, Bloomfield (1946) distinguished three classes of words: nouns, verbs, and particles. Within the particle category he further distinguished pronouns (subdivided into personal pro nouns, demonstratives, indefinite pronouns, and interrogative pronouns), preverbs (defined as particles which freely precede verb stems, including some particles which never occur anywhere else), and prenouns (particles which similarly appear before nouns). Other scholars have found it useful to set up separate word classes of pronouns and numerals (e.g., Goddard & Bragdon 1988, Nichols & Nyholm 1995), and nowadays most Algonquianists treat preverbs and their kin as a separate category, rather than as a sub-class of particles. Beyond this there is little agreement. For example, in his sketch of Malecite-Passamaquoddy, Teeter (1971:203) divided the words we are concerned with into the categories prenoun, preverb and adverb - the last roughly equivalent to Bloom- field's particle. LeSourd (1993:8) more closely followed Bloomfield in stating that there are only three parts of speech, noun, verb and particle, but went on to note that there are also "loosely joined modifiers known as preverbs and prenouns" (LeSourd 1993:16) which may precede verb stems and noun stems, though he does not seem to have defined "modifier" in rela tion to the parts of speech. Leavitt (1985) introduced a distinction between "separate" preverbs and "attached" preverbs. However, in practice his "separate" preverbs include not only what others call preverbs, but also initial elements (i.e., "attached preverbs") which happen to be followed by an HI in derivation.