Puzzles in Logic, Languages and Computation Recreational Linguistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Minutes of the CHMP Meeting 14-17 September 2020
13 January 2021 EMA/CHMP/625456/2020 Corr.1 Human Medicines Division Committee for medicinal products for human use (CHMP) Minutes for the meeting on 14-17 September 2020 Chair: Harald Enzmann – Vice-Chair: Bruno Sepodes Disclaimers Some of the information contained in these minutes is considered commercially confidential or sensitive and therefore not disclosed. With regard to intended therapeutic indications or procedure scopes listed against products, it must be noted that these may not reflect the full wording proposed by applicants and may also vary during the course of the review. Additional details on some of these procedures will be published in the CHMP meeting highlights once the procedures are finalised and start of referrals will also be available. Of note, these minutes are a working document primarily designed for CHMP members and the work the Committee undertakes. Note on access to documents Some documents mentioned in the minutes cannot be released at present following a request for access to documents within the framework of Regulation (EC) No 1049/2001 as they are subject to on- going procedures for which a final decision has not yet been adopted. They will become public when adopted or considered public according to the principles stated in the Agency policy on access to documents (EMA/127362/2006). 1 Addition of the list of participants Official address Domenico Scarlattilaan 6 ● 1083 HS Amsterdam ● The Netherlands Address for visits and deliveries Refer to www.ema.europa.eu/how-to-find-us Send us a question Go to www.ema.europa.eu/contact Telephone +31 (0)88 781 6000 An agency of the European Union © European Medicines Agency, 2020. -

UAX #44: Unicode Character Database File:///D:/Uniweb-L2/Incoming/08249-Tr44-3D1.Html
UAX #44: Unicode Character Database file:///D:/Uniweb-L2/Incoming/08249-tr44-3d1.html Technical Reports L2/08-249 Working Draft for Proposed Update Unicode Standard Annex #44 UNICODE CHARACTER DATABASE Version Unicode 5.2 draft 1 Authors Mark Davis ([email protected]) and Ken Whistler ([email protected]) Date 2008-7-03 This Version http://www.unicode.org/reports/tr44/tr44-3.html Previous http://www.unicode.org/reports/tr44/tr44-2.html Version Latest Version http://www.unicode.org/reports/tr44/ Revision 3 Summary This annex consolidates information documenting the Unicode Character Database. Status This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress. A Unicode Standard Annex (UAX) forms an integral part of the Unicode Standard, but is published online as a separate document. The Unicode Standard may require conformance to normative content in a Unicode Standard Annex, if so specified in the Conformance chapter of that version of the Unicode Standard. The version number of a UAX document corresponds to the version of the Unicode Standard of which it forms a part. Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this annex is found in Unicode Standard Annex #41, “Common References for Unicode Standard Annexes.” For the latest version of the Unicode Standard, see [Unicode]. For a list of current Unicode Technical Reports, see [Reports]. -

Following Sub-Sections: 1) Languageintroduction, Grade 6
DOCUMENT RESUME ED 051 153 SP 007 203 TITLE Curriculum Guide, English for Grades VI-IX. INST:aUTIO/ Boston Public Schools, Mass. PUB DATE 70 NOTE 307p.; School Document No 2-1970 AVAILABLE FROM Boston School Committee, 15 Beacon Street, Boston, Mass. 02108 ($3.75, check payable to The City of Boston) EtRS PRICE EDRS Price MF-$0.65 HC-$13.16 DESCRIPTORS Composition (Literary), *Curriculum Guides, *English Curriculum, English Literature, Grade 6, Grade 7, Grade 8, Grade 9, *Intermediate Grades, *Junior High Schools, Language Instruction, *Middle Schools ABSTRACT GRADES OR AGES: Grades 6-9. SUBJECT MATTER: English. ORGANIZATION AND PHYSICAL APPEARANCE: The guide has three main sections dealing with language, literature, and composition with the following sub-sections: 1) languageintroduction, grade 6, grade 7, grade 8, grade 9, chronology, bibliography, spelling, listening skills; 2) literature -- overview and teaching techuiguez, grade 6, grade 7, grade 8, grade 9, choral speaking; and 3) composition. The guide is mimeographed and spiral-bound with a soft cover. OBJECTIVES AND ACTIVITIES: Objectives are listed for the various topics. Suggested classroom activities andtudent enrichment activities are included in the text. INSTRUCTIONAL MATERIALS: References to texts and materials are given at the end of sone sub-sections. There is also a bibliography, and a list of suggested texts for composition. STUDENT ASSESSMENT: The section on composition includes a oriel description of evaluation techniques for the teacher. (MBM) .=r II PERSYSSieN TO PCPROOVCE THIS IVINP 1111111111 MATERIAL HAS BEEN GRAMM BY kg-21c.y 4-097:. elyzAre__,__ TO ERIC AND ORGANIZATIONS OPYRATING UNDER AGREEMENTS Was THE ,u$ OffiCE OF EDUCATIONFOP r'R REPFOPUCTION OUTSIDE THE ERIC ,a.'ENI REQUIRES PER MISSION CIF THE COPYRIGHT OWNER School Document No. -

A STUDY of WRITING Oi.Uchicago.Edu Oi.Uchicago.Edu /MAAM^MA
oi.uchicago.edu A STUDY OF WRITING oi.uchicago.edu oi.uchicago.edu /MAAM^MA. A STUDY OF "*?• ,fii WRITING REVISED EDITION I. J. GELB Phoenix Books THE UNIVERSITY OF CHICAGO PRESS oi.uchicago.edu This book is also available in a clothbound edition from THE UNIVERSITY OF CHICAGO PRESS TO THE MOKSTADS THE UNIVERSITY OF CHICAGO PRESS, CHICAGO & LONDON The University of Toronto Press, Toronto 5, Canada Copyright 1952 in the International Copyright Union. All rights reserved. Published 1952. Second Edition 1963. First Phoenix Impression 1963. Printed in the United States of America oi.uchicago.edu PREFACE HE book contains twelve chapters, but it can be broken up structurally into five parts. First, the place of writing among the various systems of human inter communication is discussed. This is followed by four Tchapters devoted to the descriptive and comparative treatment of the various types of writing in the world. The sixth chapter deals with the evolution of writing from the earliest stages of picture writing to a full alphabet. The next four chapters deal with general problems, such as the future of writing and the relationship of writing to speech, art, and religion. Of the two final chapters, one contains the first attempt to establish a full terminology of writing, the other an extensive bibliography. The aim of this study is to lay a foundation for a new science of writing which might be called grammatology. While the general histories of writing treat individual writings mainly from a descriptive-historical point of view, the new science attempts to establish general principles governing the use and evolution of writing on a comparative-typological basis. -

World Braille Usage, Third Edition
World Braille Usage Third Edition Perkins International Council on English Braille National Library Service for the Blind and Physically Handicapped Library of Congress UNESCO Washington, D.C. 2013 Published by Perkins 175 North Beacon Street Watertown, MA, 02472, USA International Council on English Braille c/o CNIB 1929 Bayview Avenue Toronto, Ontario Canada M4G 3E8 and National Library Service for the Blind and Physically Handicapped, Library of Congress, Washington, D.C., USA Copyright © 1954, 1990 by UNESCO. Used by permission 2013. Printed in the United States by the National Library Service for the Blind and Physically Handicapped, Library of Congress, 2013 Library of Congress Cataloging-in-Publication Data World braille usage. — Third edition. page cm Includes index. ISBN 978-0-8444-9564-4 1. Braille. 2. Blind—Printing and writing systems. I. Perkins School for the Blind. II. International Council on English Braille. III. Library of Congress. National Library Service for the Blind and Physically Handicapped. HV1669.W67 2013 411--dc23 2013013833 Contents Foreword to the Third Edition .................................................................................................. viii Acknowledgements .................................................................................................................... x The International Phonetic Alphabet .......................................................................................... xi References ............................................................................................................................ -

The Writing Revolution
9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iii The Writing Revolution Cuneiform to the Internet Amalia E. Gnanadesikan A John Wiley & Sons, Ltd., Publication 9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iv This edition first published 2009 © 2009 Amalia E. Gnanadesikan Blackwell Publishing was acquired by John Wiley & Sons in February 2007. Blackwell’s publishing program has been merged with Wiley’s global Scientific, Technical, and Medical business to form Wiley-Blackwell. Registered Office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom Editorial Offices 350 Main Street, Malden, MA 02148-5020, USA 9600 Garsington Road, Oxford, OX4 2DQ, UK The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, UK For details of our global editorial offices, for customer services, and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com/wiley-blackwell. The right of Amalia E. Gnanadesikan to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. Wiley also publishes its books in a variety of electronic formats. Some content that appears in print may not be available in electronic books. Designations used by companies to distinguish their products are often claimed as trademarks. -

ONIX for Books Codelists Issue 47
ONIX for Books Codelists Issue 47 31 October 2019 DOI: 10.4400/akjh Go to latest Issue All ONIX standards and documentation – including this document – are copyright materials, made available free of charge for general use. A full license agreement (DOI: 10.4400/nwgj) that governs their use is available on the EDItEUR website. All ONIX users should note that this issue of the ONIX codelists does not include support for codelists used only with ONIX version 2.1. ONIX 2.1 remains fully usable, using Issue 36 of the codelists or earlier, and Issue 36 continues to be available via the archive section of the EDItEUR website (https://www.editeur.org/15/Archived-Previous-Releases). These codelists are also available within a multilingual online browser at https://ns.editeur.org/onix. Codelists are revised quarterly. Layout of codelists This document contains ONIX for Books codelists Issue 46, intended primarily for use with ONIX 3.0. The codelists are arranged in a single table for reference and printing. They may also be used as controlled vocabularies, independent of ONIX. This document does not differentiate explicitly between codelists for ONIX 3.0 and those that are used with earlier releases, but lists used only with earlier releases have been removed. For details of which code list to use with which data element in each version of ONIX, please consult the main Specification for the appropriate release. Occasionally, a handful of codes within a particular list are defined as either deprecated, or not valid for use in a particular version of ONIX or with a particular data element. -

Winter 2005-2006 (Pdf)
Winter 2005-06 Volume XLVIII, No. 4 WHAT’S INSIDE: BRAILLE LITERACY –It's a Family Value "The Good Old Girl System" Computer Braille Code The Least Restrictive Environment JOURNAL The official publication of the California Transcribers and Educators of the Visually Handicapped Message from the Editor I would like to thank both Dr. Vasiliauskas M.D. and Winifred Downing for their excellent contributions to this issue of the CTEVH Journal. This is my tenth Journal as your editor and I feel very fortunate to work with our very special team of Specialists. As I peruse this year's selection of conference workshops I have many difficult decisions ahead. I look forward to seeing you all at conference and hope you enjoy this issue. THE CTEVH JOURNAL Editor: Lisa Merriam Print Proofreader: Julia Moyer Braille Transcription: Joanne Call Embossing: Sacramento Braille Transcribers Inc. Tape Recording & Duplication: Volunteers of Vacaville The CTEVH Journal is published four times a year by the California Transcribers and Educators of the Visually Handicapped, Inc., 741 North Vermont Avenue, Los Angeles, California 90029. ©2006 by California Transcribers and Educators of the Visually Hand- icapped, Inc. except where noted. All rights reserved. No part of this periodical may be reproduced without the consent of the publishers. Editorial office for the CTEVH Journal and all other CTEVH publications is: Lisa Merriam CTEVH Publications 10061 Riverside Drive #88 Toluca Lake, California 91602 E-mail: [email protected] Deadlines for submission of articles: Spring Issue: Summer Issue: Fall Issue April 1, 2006 June 1, 2006 August 1, 2006 CTEVH JOURNAL Winter 2005-06 Volume XLVIII, No. -

L I E P S N a 2012
L I E P S N A 2012 ATIO NER NS GE HE T G IN T I N U • Ą T R A K Į 2012 metų 50 S O T R A Lietuvių Fondo K Š I pelno skirsymas 1962-2012 2012 Grant Allocation of the Lithuanian Foundation, Inc. LIETUVIŲ FONDAS LITHUANIAN FOUNDATION, INC. 14911 127th Street Lemont, IL 60439 630-257-1616 www.lithuanianfoundation.org [email protected] www.lietuviufondas.org 2012 Lietuvių Fondo Taryba Dr. Antanas Razma, Sr. LF T arybos Garbės Pirmininkas 2012 The LF Board of Directors LF Taryba Board of Directors Marius Kasniūnas Pirmininkas Saulius Čyvas Violeta Gedgaudienė Šarūnas Griganavičius Rimantas Griškelis Juozas Kapačinskas Audronė Karalius Rita Kisielienė Almis Kuolas Dalė Lukienė Laurynas Misevičius Vytas Narutis Dr. Antanas Razma, Jr. Dr. Donatas Siliūnas Raimundas Šilkaitis Arvydas Tamulis Dalius Vasys 2012 metų LF Tarybos ir Kontrolės komisijos nariai / 2012 LF Mem- bers of the Board and Audit Committee LF Valdyba Nuotraukoje: pirmoje eilėje iš kairės/in the picture first row from the left: Officers Arvydas Tamulis (LF Valdybos pirmininkas / LF President) , Dalius Vasys, Arvydas Tamulis Juozas Kapačinskas, Aušrelė Sakalaitė, Audronė Karalius, Raimundas Pirmininkas Šilkaitis, Antanas Razma jr., Dalė Lukienė, Marius Kasniūnas (LF Tarybos Matas Čyvas pirmininkas / Chairman of the Board), Almis Kuolas, Rimantas Griškelis. Saulius Čyvas Antroje eilėje iš kairės / second row from the left: Vytas Narutis, Algis Iždininkas Rugienius, Šarūnas Griganavičius, Laurynas Misevičius, Saulius Čyvas. Agnė Vertelkaitė Nuotraukoje nėra/ not pictured: Violeta Gedgaudienė, Rita Kiselienė, Ramūnas Astrauskas Leonas Narbutis Gytis Petkus, Dr. Donatas Siliūnas. Jūratė Mereckienė Administratorė A. Rimas Domanskis Korp. sekretorius Kontrolės Komisija Audit Committee Gytis Petkus Algis Rugienius, Jr. -
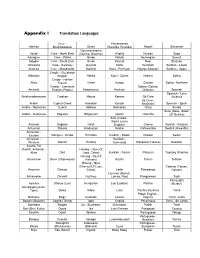
Appendix I Translation Languages
Appendix I Translation Languages Cree - Kinyarwanda Abkhaz Mushkegowuk Gonja (Rwanda, Ruanda) Nepali Slovenian Gourmanchema Acholi Cree - North East (Gurma, Gourma) Kirghiz Niuean Soga Adangme Cree - Plains Grebo Kiribati Norwegian Somali Adyghe Cree - South East Greek Kirundi Nuer Soninke Afrikaans Cree - Swampy Gujarati Koho Nuristani Sorbian - Lower Akateko Cree - Woodlands Gwichin Komi - Permyak Nyanja (Malawi) Sorbian - Upper Creole - Guyanese Albanian English Hakka Komi - Zyrian Nzema Sotho Creole - Haitian Altay French Harari Kongo Occitan Sotho - Northern Creole - Jamaican Ojibwa (Ojibwe, Amharic English (Patois) Hassaniyya Konkani Ojibway) Spanish Spanish - Latin Anishinaabemowin Croatian Hausa Korean Oji-Cree America Oji-Cree - Arabic Cypriot Greek Hawaiian Koryak Anishinini Spanish - Spain Arabic - Moroccan Czech Hebrew Kosraean Oriya Sunda Susu (Sose, Soso) Arabic - Sudanese Dagaare Hiligaynon Kpelle Oromiffa (Of Guinea) Krio (Creole - Sierra Leone Aramaic Dagbani Hindi English) Oromo Swahili - Kibajuni Armenian Dakota Hindustani Krobo Oshiwambo Swahili (Kiswahili) Armenian - Eastern Dangme - Krobo Hiri Motu Kurdish - Badini Ossetic Swazi Armenian - Kurdish - Western Danish Hmong Kurmandji Otjiherero (Herero) Swedish Asante Twi (Asanti, Ashante) - Hmong - Daw (Of Akan Dari Laos, China) Kurdish - Sorani Palauan Tagalog (Filipino) Hmong - Do (Of Assamese Dene (Chipewyan) Vietnam) Kutchi Pamiri Tahitian Hmong - Njua (Green) (Of Laos, Taishan (Toisan, Assyrian Dewoin China) Ladin Pampango Hoisan) Lamnso' (Banso', Atikamekw Dhivehi -

(SIRS) Manual School Year
New York State Student Information Repository System (SIRS) Manual Reporting Data for the 2010–11 School Year October 15, 2010 Version 6.0 The University of the State of New York THE STATE EDUCATION DEPARTMENT Information and Reporting Services Albany, New York 12234 Revision History Revision History Version Date Revisions Initial Release. Please pay particular attention to revisions to guidance on: • Role of District Data Coordinator. • New race/ethnicity reporting rules. • New teacher/course reporting rules. • Implementation of new federal rules (one-day enrollment criterion, assignment of grade 9 entry date for ungraded students with a disability, and outcome status determinations for court placements of incarcerated students) for 2006 (non-accountability) and 2007 total cohort graduation October 15, 6.0 rate reporting purposes. 2010 • New Reason for Ending Enrollment Code 8338 – Incarcerated student, no participation in a program culminating in a regular diploma. • New test accommodation codes. • Deleted CTE Codes. • Student Grades, Staff Snapshot, Course, and Marking Period Templates. • Component Retests, SLPs, Reading First, and Grades 5 & 8 NYSTP and NYSAA Social Studies no longer available. ii Student Information Repository System Manual for 2010–11 Version 6.0 Table of Contents Table of Contents INTRODUCTION...........................................................................................................................................1 New York State Education Department E-mail Queries ..........................................................................3 -

Bankjet 2500 Programmer's Guide
Programmer’s Guide PN: 100-08072 Rev D Feb-2008 Change Log BANKjet® 2500 Programmer’s Guide Change Log Rev 1 Initial Draft Aug 2007 Rev 2 Second Draft Aug 2007 Rev 2 Added Wide Slip Zone commands. Updated statistics tables. Rev 3 Added Enhanced Page Mode Oct 2007 Rev A Initial Release Nov 2007 Rev B Dec 2007 Clarified the enter boot load instructions. Added reference to secondary boot loader document Rev C Jan 2008 Added a section on enhanced POR.INI options. Added a section on error indications Removed references to paper low. (The Bankjet 2500 does not support paper low) Changed the print zone from 2.83 to 2.67 inches. Rev D Added Hard error blink Error Chart Reformatted document. Removed sections. Page ii 100-08072 Rev D Feb-08 Programmer’s Guide BANKjet® 2500 General Information Feb-08 100-08072 Rev D Page iii Change Log BANKjet® 2500 Programmer’s Guide ® BANKjet 2500 Disclaimer © 2007 Transact Technologies, Inc. All rights reserved. NOTICE TO ALL PERSONS RECEIVING THIS DOCUMENT: The information in this document is subject to change without notice. No part of this document may be reproduced, stored or transmitted in any form or by any means, electronic or mechanical, for any purpose, without the express written permission of Transact Technologies, Inc. ("Transact"). This document is the property of and contains information that is both confidential and proprietary to Transact. Recipient shall not disclose any portion of this document to any third party. TRANSACT DOES NOT ASSUME ANY LIABILITY FOR DAMAGES INCURRED, DIRECTLY OR INDIRECTLY, FROM ANY ERRORS, OMISSIONS OR DISCREPANCIES IN THE INFORMATION CONTAINED IN THIS DOCUMENT.