Proposal to Encode the Khojki Script in ISO/IEC 10646
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Types of Polar Questions in Javanese Jozina VANDER KLOK 1
Types of polar questions in Javanese Jozina VANDER KLOK University of Oslo This paper describes the different grammatical strategies to form polar questions (broadly including yes-no questions and alternative questions) in Javanese, an area that has not been fully documented before. Focusing on the dialect of Javanese spoken in Paciran, Lamongan, East Java, Indonesia, yes-no questions can be formed with intonation, the particles opo, toh and iyo, or by fronting an auxiliary. Yes-no questions with narrow focus in this dialect are achieved via various syntactic positions of the particle toh in contrast to broad focus sentence- finally. Alternative questions are also formed with toh, either conjoining two constituents or with negation as a tag question. Based on these new findings in Paciran Javanese compared with Standard Javanese, the reflex of the alternative question particle is shown to co-vary with the disjunctive marker of that dialect. Additional dialectal variation concerning syntactic restrictions on auxiliary fronting is also discussed. Finally, combinations of these strategies— unexplored in any dialect—are shown to be possible (e.g., auxiliary fronting plus the particle opo) while other combinations are shown to be impossible (e.g., with the particle opo and particle toh in sentence final position). This paper serves as a benchmark for further investigation into dialectal variation across Javanese as well as into the syntax-semantics and syntax-prosody interfaces in deriving different types of yes-no questions. 1. Introduction1 Polar questions in Javanese—in any dialect—are currently not well-documented. Putting together descriptions from various sources on Standard Javanese, as spoken in the courtly centers of Yogyakarta and Surakarta/Solo, yes-no questions are noted to be formed via (i) intonation, (ii) the particle iya/yha/ya ‘yes’, (iii) the particle apa, and (iv) the particle ta (Horne 1961; Arps et al. -

Section 14.4, Phags-Pa
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

From Arabic Style Toward Javanese Style: Comparison Between Accents of Javanese Recitation and Arabic Recitation
From Arabic Style toward Javanese Style: Comparison between Accents of Javanese Recitation and Arabic Recitation Nur Faizin1 Abstract Moslem scholars have acceptedmaqamat in reciting the Quran otherwise they have not accepted macapat as Javanese style in reciting the Quran such as recitationin the State Palace in commemoration of Isra` Miraj 2015. The paper uses a phonological approach to accents in Arabic and Javanese style in recitingthe first verse of Surah Al-Isra`. Themethod used here is analysis of suprasegmental sound (accent) by usingSpeech Analyzer programand the comparison of these accents is analyzed by descriptive method. By doing so, the author found that:first, there is not any ideological reason to reject Javanese style because both of Arabic and Javanese style have some aspects suitable and unsuitable with Ilm Tajweed; second, the suitability of Arabic style was muchthan Javanese style; third, it is not right to reject recitingthe Quran with Javanese style only based on assumption that it evokedmistakes and errors; fourth, the acceptance of Arabic style as the art in reciting the Quran should risedacceptanceof the Javanese stylealso. So, rejection of reciting the Quranwith Javanese style wasnot due to any reason and it couldnot be proofed by any logical argument. Keywords: Recitation, Arabic Style, Javanese Style, Quran. Introduction There was a controversial event in commemoration of Isra‘ Mi‘raj at the State Palacein Jakarta May 15, 2015 ago. The recitation of the Quran in the commemoration was recitedwithJavanese style (langgam).That was not common performance in relation to such as official event. Muhammad 58 Nur Faizin, From Arabic Style toward Javanese Style Yasser Arafat, a lecture of Sunan Kalijaga State Islamic University Yogyakarta has been reciting first verse of Al-Isra` by Javanese style in the front of state officials and delegationsof many countries. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
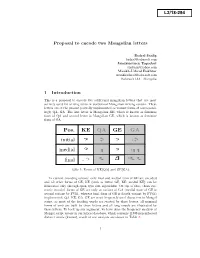
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

The Origins, Evolution and Decline of the Khojki Script
The origins, evolution and decline of the Khojki script Juan Bruce The origins, evolution and decline of the Khojki script Juan Bruce Dissertation submitted in partial fulfilment of the requirements for the Master of Arts in Typeface Design, University of Reading, 2015. 5 Abstract The Khojki script is an Indian script whose origins are in Sindh (now southern Pakistan), a region that has witnessed the conflict between Islam and Hinduism for more than 1,200 years. After the gradual occupation of the region by Muslims from the 8th century onwards, the region underwent significant cultural changes. This dissertation reviews the history of the script and the different uses that it took on among the Khoja people since Muslim missionaries began their activities in Sindh communities in the 14th century. It questions the origins of the Khojas and exposes the impact that their transition from a Hindu merchant caste to a broader Muslim community had on the development of the script. During this process of transformation, a rich and complex creed, known as Satpanth, resulted from the blend of these cultures. The study also considers the roots of the Khojki writing system, especially the modernization that the script went through in order to suit more sophisticated means of expression. As a result, through recording the religious Satpanth literature, Khojki evolved and left behind its mercantile features, insufficient for this purpose. Through comparative analysis of printed Khojki texts, this dissertation examines the use of the script in Bombay at the beginning of the 20th century in the shape of Khoja Ismaili literature. -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

"9-41516)9? "9787:)4 ;7 -6+7,- )=1 16 ;0- & $
L2/20-256 "9-41516)9?"9787:)4;7-6+7,-)=116;0-&$ ᭛᭜᭛ <;079 ,1;?))?<"-9,)6)215-14,7;3755/5)14+75 40)5 <9=)6:)0140)56<9=)6:)0/5)14+75 );- ;0$-8;-5*-9 6;97,<+;176 ,=:#6L>H8G>EI>H6=>HIDG>86AG6=B>76H:9H8G>EI;DJC9>CK6G>DJH>CH8G>EI>DCH6C96GI:;68IHEGD9J8:97:IL::CI=: I=6C9I=: I=8:CIJGN>C>CHJA6G+DJI=:6HIH>6A6G<:EDGI>DCD;>IH8DGEJH>H;DJC9>C"6K67JI#6L>B6I:G>6AH =6K:6AHD7::C;DJC9>C+JB6IG6%6A6N(:C>CHJA66A>6C9I=:(=>A>EE>C:H,=:H8G>EI>H;G:FJ:CIAN6HHD8>6I:9L>I= I=:'A9"6K6C:H:A6C<J6<:7JIB6I:G>6AHLG>II:C>C+6CH@G>I'A9%6A6N'A96A>C:H:6C9'A9+JC96C:H:A6C<J6<: =6H6AHD7::C;DJC9>CI=:#6L>H8G>EIGDBI=:B>9I=8:CIJGNH>BEA:;JC8I>DC6A#6L>L6HL>9:ANJH:9IDG:8DG9 A6C9 <G6CIH GDN6A :9>8IH 6C9 H>B>A6G 8=6C8:GN 9D8JB:CIH ,DL6G9H I=: :C9 D; I=: ;>GHI B>AA:CC>JB I=: H8G>EI 7:86B:>C8G:6H>C<AN9:8DG6I>K:6C986AA><G6E=>89J:ID>IHJH:6HI=:B6>CK:=>8A:D;'A9"6K6C:H:A>I:G6GNA6C<J6<: L>I=ADC<A6HI>C<A:<68N>CI=:A>I:G6GNIG69>I>DCD;I=:BD9:GC"6K6C:H:6C96A>C:H:A6C<J6<:H$6I:G#6L>H=DLH B6CNK6G>6I>DCHDK:G6L>9:<:D<G6E=>89>HIG>7JI>DC'K:GI>B:I=:H:K6G>6CIH=6K::KDAK:9>G:8IANDG>C9>G:8IAN >CIDI=:B6CNBD9:GCG6=B>8H8G>EIHD;>CHJA6G+H>6HJ8=6H6A>C:H:6I6@"6K6C:H:$DCI6G6:I8 /=>A:I=:68I>K:JH:D;#6L>H8G>EI=6H7::CG:EA68:97NDI=:GH8G>EIHH>C8:I=: I=8:CIJGNI=:G:6G:6CJB7:GD; BD9:GC96N:CI=JH>6HIH6C98DBBJC>I>:HL=DJH:I=:H8G>EIID96N;DGDI=:GEJGEDH:HI=6C6C8>:CIG:EGD9J8I>DC ;DG:M6BEA:ID8=6I>CHD8>6A6EEA>86I>DC6C98G:6I:>B6<:EDHIH!CI=>HG:K>K6AINE:D;JH:I=:#6L>H8G>EIB6N7: JH:9IDLG>I:A6C<J6<:HI=6I6G:CDI;DJC9>C‘6JI=:CI>8’#6L>8DGEJHHJ8=6HI=:BD9:GC"6K6C:H:A6C<J6<:DG I=: !C9DC:H>6C A6C<J6<: H#6L>=6H CDI 7::C :C8D9:9>C I=: -C>8D9: N:I I=: -

WG2 M52 Minutes
ISO.IEC JTC 1/SC 2 N____ ISO/IEC JTC 1/SC 2/WG 2 N3603 2009-07-08 ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) - ISO/IEC 10646 Secretariat: ANSI DOC TYPE: Meeting Minutes TITLE: Unconfirmed minutes of WG 2 meeting 54 Room S206/S209, Dublin Centre University, Dublin, Ireland 2009-04-20/24 SOURCE: V.S. Umamaheswaran, Recording Secretary, and Mike Ksar, Convener PROJECT: JTC 1.02.18 – ISO/IEC 10646 STATUS: SC 2/WG 2 participants are requested to review the attached unconfirmed minutes, act on appropriate noted action items, and to send any comments or corrections to the convener as soon as possible but no later than the Due Date below. ACTION ID: ACT DUE DATE: 2009-10-12 DISTRIBUTION: SC 2/WG 2 members and Liaison organizations MEDIUM: Acrobat PDF file NO. OF PAGES: 60 (including cover sheet) Michael Y. Ksar Convener – ISO/IEC/JTC 1/SC 2/WG 2 22680 Alcalde Rd Phone: +1 408 255-1217 Cupertino, CA 95014 Email: [email protected] U.S.A. ISO International Organization for Standardization Organisation Internationale de Normalisation ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2 N____ ISO/IEC JTC 1/SC 2/WG 2 N3603 2009-07-08 Title: Unconfirmed minutes of WG 2 meeting 54 Room S206/S209, Dublin Centre University, Dublin, Ireland; 2009-04-20/24 Source: V.S. Umamaheswaran ([email protected]), Recording Secretary Mike Ksar ([email protected]), Convener Action: WG 2 members and Liaison organizations Distribution: ISO/IEC JTC 1/SC 2/WG 2 members and liaison organizations 1 Opening Input document: 3573 2nd Call Meeting # 54 in Dublin; Mike Ksar; 2009-02-16 Mr.