The American Legion Weekly [Volume 2, No. 35 (September 24
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
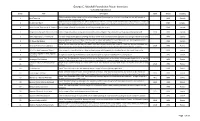
GCMF Poster Inventory
George C. Marshall Foundation Poster Inventory Compiled August 2011 ID No. Title Description Date Period Country A black and white image except for the yellow background. A standing man in a suit is reaching into his right pocket to 1 Back Them Up WWI Canada contribute to the Canadian war effort. A black and white image except for yellow background. There is a smiling soldier in the foreground pointing horizontally to 4 It's Men We Want WWI Canada the right. In the background there is a column of soldiers march in the direction indicated by the foreground soldier's arm. 6 Souscrivez à L'Emprunt de la "Victoire" A color image of a wide-eyed soldier in uniform pointing at the viewer. WWI Canada 2 Bring Him Home with the Victory Loan A color image of a soldier sitting with his gun in his arms and gear. The ocean and two ships are in the background. 1918 WWI Canada 3 Votre Argent plus 5 1/2 d'interet This color image shows gold coins falling into open hands from a Canadian bond against a blue background and red frame. WWI Canada A young blonde girl with a red bow in her hair with a concerned look on her face. Next to her are building blocks which 5 Oh Please Do! Daddy WWI Canada spell out "Buy me a Victory Bond" . There is a gray background against the color image. Poster Text: In memory of the Belgian soldiers who died for their country-The Union of France for Belgium and Allied and 7 Union de France Pour La Belqiue 1916 WWI France Friendly Countries- in the Church of St. -

Coming out on June 14Th 2011
Coming out on June 14th 2011, new releases from Actors and Actresses, Geza X, Hardgirls, Kudrow, Naked Raygun, Slow Gherkin, The Holy Mess, The Preachers, The Saint Catherines, and The Tigermilks Exclusively Distributed by INDEPENDENT LABEL COLLECTIVE Actors & Actresses Street Date: We Love Our Enemy LP 06/14/2011 INFORMATION: Artist Hometown: Kansas City, MO For Fans Of: Low, Juno, Autolux, Swervedriver Actors&Actresses are a 3 piece from Kansas City, MO who mix synthetic, pre-recorded and organic sounds to produce alternately chilling backdrops and intense sequences of heavy post... whatever. While the stage presence of the band is relatively calm, the visual accompaniments filmed and edited by drummer Dave Sumner provide textural kinetics, without actually overpowering the complex rumble the band creates. Triggered samples and treated drum loops roil in the background, while the overpowering down-tuned bass ARTIST: ACTORS & ACTRESSES played by vocalist Scott Bennett bursts at the seams. Moving forward TITLE: WE LOVE OUR ENEMY and aft through the stereo field, Andrew Schiller’s guitars provide CAT#: Sheath028v eerie whines alternating with roaring walls of chords. The band can FORMAT: LP deftly move from a vast downpour to a quite intimate and delicate GENRE: shoegaze indie rock singularity, often within mere measures. The lean arrangements of BOX LOT: 12 the band’s material allow for the players to concoct a sound all their SRLP: $16.98 own yet deliver full sets of songs, each one sounding very different UPC: 798546267017 from the last. As record reviewers often note, it’s easy to hear where EXPORT: NO RESTRICTIONS A&A’s influences originate, but they’re somehow able to bring it all within their hazy machinery and make it all seem new again. -

Saber and Scroll Journal Volume VI Issue I Winter 2017 Saber And
Saber and Scroll Journal Volume VI Issue I Winter 2017 Saber and Scroll Historical Society 1 © Saber and Scroll Historical Society, 2018 Logo Design: Julian Maxwell Cover Design: Joan at the coronation of Charles VII, oil on canvas by Jean Auguest Dominique Ingres, c. 1854. Currently at Louvre Museum. Members of the Saber and Scroll Historical Society, the volunteer staff at the Saber and Scroll Journal publishes quarterly. saberandscroll.weebly.com 2 Journal Staff Editor in Chief Michael Majerczyk Copy Editors Anne Midgley, Michael Majerczyk Content Editors Tormod Engvig, Joe Cook, Mike Gottert, Kathleen Guler, Michael Majerczyk, Anne Midgley, Jack Morato, Chris Schloemer, Christopher Sheline Proofreaders Aida Dias, Tormod Engvig, Frank Hoeflinger, Anne Midgley, Michael Majerczyk, Jack Morato, John Persinger, Chris Schloemer, Susanne Watts Webmaster Jona Lunde Academic Advisors Emily Herff, Dr. Robert Smith, Jennifer Thompson 3 Contents Letter from the Editor 5 The Hundred Years War: A Different Contextual Overview Dr. Robert G. Smith 7 The Maiden of France: A Brief Overview of Joan of Arc and the Siege of Orléans 17 Cam Rea Joan of Arc through the Ages: In Art and Imagination 31 Anne Midgley Across the Etowah and into the Hell-Hole: Johnston’s Lost Chance for Victory in the Atlanta Campaign 47 Greg A. Drummond Cape Esperance: The Misunderstood Victory of Admiral Norman Scott 67 Jeffrey A. Ballard “Died on the Field of Honor, Sir.” Virginia Military Institute in the American Civil War and the Cadets Who Died at the Battle of New Market: May 15, 1864 93 Lew Taylor Exhibit and Book Reviews 105 4 Letter from the Editor Michael Majerczyk Hi everyone. -
The Florida Historical Quarterly
COVER The Gainesville Graded and High School, completed in 1900, contained twelve classrooms, a principal’s office, and an auditorium. Located on East University Avenue, it was later named in honor of Confederate General Edmund Kirby Smith. Photograph from the postcard collection of Dr. Mark V. Barrow, Gainesville. The Historical Quarterly Volume LXVIII, Number April 1990 THE FLORIDA HISTORICAL SOCIETY COPYRIGHT 1990 by the Florida Historical Society, Tampa, Florida. The Florida Historical Quarterly (ISSN 0015-4113) is published quarterly by the Florida Historical Society, Uni- versity of South Florida, Tampa, FL 33620, and is printed by E. O. Painter Printing Co., DeLeon Springs, Florida. Second-class postage paid at Tampa and DeLeon Springs, Florida. POSTMASTER: Send address changes to the Florida Historical Society, P. O. Box 290197, Tampa, FL 33687. THE FLORIDA HISTORICAL QUARTERLY Samuel Proctor, Editor Everett W. Caudle, Editorial Assistant EDITORIAL. ADVISORY BOARD David R. Colburn University of Florida Herbert J. Doherty University of Florida Michael V. Gannon University of Florida John K. Mahon University of Florida (Emeritus) Jerrell H. Shofner University of Central Florida Charlton W. Tebeau University of Miami (Emeritus) Correspondence concerning contributions, books for review, and all editorial matters should be addressed to the Editor, Florida Historical Quarterly, Box 14045, University Station, Gainesville, Florida 32604-2045. The Quarterly is interested in articles and documents pertaining to the history of Florida. Sources, style, footnote form, original- ity of material and interpretation, clarity of thought, and in- terest of readers are considered. All copy, including footnotes, should be double-spaced. Footnotes are to be numbered con- secutively in the text and assembled at the end of the article. -

PRESIDENT SENDS HIS MESSAGE to PEACE Socffities
■ / M ’Tr-.. ''. f" s n s m A m m s ' - ^ iT iiu n ViULT c m e o j a i M i i r M m M i «f ApiO^ 1M9 5,509 M M Nr of Affifi B o m m iMmurbrolrr lEiintinn lirraUi tw o . - ' ' •ICXr M M Io i. 4 ft; , PRICE THREE CENTS (ftH iittff A4vcrttilflf M f« fi !•«) SOUtH BfANCHESTER, CpNN.« MONDAY. MAY 2, 1932. (TWELVE PAGES) VOLi LI^ n o ; 192. GEORGE WASHINGTON IS ‘ONAUGURATED” AGAIN SNATEVOTES Atom Is Shattered —IN SHADOW OP MODERN SKYSCRAPERS PRESIDENT SENDS WCREASEDTAX By English Savants HIS MESSAGE TO O N TQ IGRAM S London, May 2,— (AP)—Two<^#v«r for ev«ry 10,000,000 particles younc scientists of CamBirdGe Uni-1 used to BomBard it, Be said. Dr. versity were hailed today os havinG j Cockroft, the elder of the two ex- PEACE SOCffiTIES ochleved a Great Goal physicists perimenters U only 34. TdephoM R at« AUo hchid have souGht to reach for years— O pti^tlc sdentis^ lonG have SW Bav“ Broken the atom, ; hoi^ In announclDg details of what he j tending that w ^ ^ feat was «c- id Bit Greater Exemp- eoli^ “A discovery of great science compllshed a boundl^ source of K ID N APED IN T E X A S jB M h res That Jostiee Is lh« » Lord Rutherford, energy would be available. M ' S S I "It U dUflcult to « y to whjit tU . tia ii Are ADewed — Tax Doiea scienvw , ^ ociom- ^scovery majrn fy lead'' Lord Ruther- roft and E. -

Hotel Berlin
HOTEL BERLIN: THE POLITICS OF COMMERCIAL HOSPITALITY IN THE GERMAN METROPOLIS, 1875–1945 by Adam Bisno A dissertation submitted to Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland December, 2017 © 2017 Adam Bisno ii Dissertation Advisor: Peter Jelavich Adam Bisno Hotel Berlin: The Politics of Commercial Hospitality in the German Metropolis, 1875–1945 Abstract This dissertation examines the institution of the grand hotel in Imperial, Weimar, and Nazi Berlin. It is a German cultural and business history of the fate of classical liberalism, which in practice treated human beings as rational, self-regulating subjects. The major shareholders in the corporations that owned the grand hotels, hotel managers, and hotel experts, through their daily efforts to keep the industry afloat amid the vicissitudes of modern German history, provide a vantage point from which to see the pathways from quotidian difficulties to political decisions, shedding light on how and why a multi-generational group of German businessmen embraced and then rejected liberal politics and culture in Germany. Treating the grand hotel as an institution and a space for the cultivation of liberal practices, the dissertation contributes to the recent body of work on liberal governance in the modern city by seeing the grand hotel as a field in which a dynamic, socially and culturally heterogeneous population tried and ultimately failed to determine the powers and parameters of liberal subjectivity. In locating the points at which liberal policies became impracticable, this dissertation also enters a conversation about the timing and causes of the crisis of German democracy. -

INSIDE:- Earliest Use of “Heavy Metal” - 1300 Underground Metal Flyers - Original KISS Zine Art - Signed Books, Albums and More
METALSECOND CATALOG OF HEAVY METAL JUNE 2015 Featuring: INSIDE:- Earliest Use of “Heavy Metal” - 1300 Underground Metal Flyers - Original KISS Zine Art - Signed Books, Albums and More.... Arthur Brown The God of Hellfire TERMS OF SALE This material is subject to prior sale. If you are interested in items in this catalog, we recommend you contact us HEAVY right away to secure it. As always, if you are not satis- fied with your purchase, all items are returnable within ten days of delivery. Materials must be returned in the same condition as sent. Simply call us at 626.967.1888 to discuss. Institutions and previously known custom- METAL ers can expect the usual terms. We accept all manner of payment. California residents will pay 9% sales tax, or, if items are purchased at a book fair, pay the sales ORIGIN tax appropriate to that local. As proud members of the Antiquarian Book- STORY sellers’ Association of America, we uphold our The Fugs. THE FUGS PRESENT A NIGHT OF NAPALM association’s code of IN SUPPORT OF THE ASSEMBLY OF UNREPRESENTED ethics. For more information about ABAA book fairs and PEOPLE. New York: [Ed Sanders / Fuck You Press], [1965]. events and to review our complete code of ethics, please An original flyer promoting the band’s August 7, 1965 visit the website: www.ABAA.org concert at The Bridge Theatre in New York. Mimeographed on a 8 ½” x 11” sheet of yellow paper. Mild smudging of the BRAD & JEN JOHNSON mimeo ink to the top right corner; else clean and bright. -

The Spectral Voice and 9/11
SILENCIO: THE SPECTRAL VOICE AND 9/11 Lloyd Isaac Vayo A Dissertation Submitted to the Graduate College of Bowling Green State University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY August 2010 Committee: Ellen Berry, Advisor Eileen C. Cherry Chandler Graduate Faculty Representative Cynthia Baron Don McQuarie © 2010 Lloyd Isaac Vayo All Rights Reserved iii ABSTRACT Ellen Berry, Advisor “Silencio: The Spectral Voice and 9/11” intervenes in predominantly visual discourses of 9/11 to assert the essential nature of sound, particularly the recorded voices of the hijackers, to narratives of the event. The dissertation traces a personal journey through a selection of objects in an effort to seek a truth of the event. This truth challenges accepted narrativity, in which the U.S. is an innocent victim and the hijackers are pure evil, with extra-accepted narrativity, where the additional import of the hijacker’s voices expand and complicate existing accounts. In the first section, a trajectory is drawn from the visual to the aural, from the whole to the fragmentary, and from the professional to the amateur. The section starts with films focused on United Airlines Flight 93, The Flight That Fought Back, Flight 93, and United 93, continuing to a broader documentary about 9/11 and its context, National Geographic: Inside 9/11, and concluding with a look at two YouTube shorts portraying carjackings, “The Long Afternoon” and “Demon Ride.” Though the films and the documentary attempt to reattach the acousmatic hijacker voice to a visual referent as a means of stabilizing its meaning, that voice is not so easily fixed, and instead gains force with each iteration, exceeding the event and coming from the past to inhabit everyday scenarios like the carjackings. -
Evaluation Guidelines to Deal with Implicit Phenomena to Assess Factuality in Data-To-Text Generation
Evaluation Guidelines to Deal with Implicit Phenomena to Assess Factuality in Data-to-Text Generation Roy Eisenstadt Michael Elhadad Ben Gurion University Ben Gurion University Computer Science Department Computer Science Department Be’er Sheva, Israel Be’er Sheva, Israel [email protected] [email protected] Abstract Yet, recent work has shown that neural genera- tion models risk to create text that is not faithful Data-to-text generation systems are trained to the input data specification (Wang, 2019; Chen on large datasets, such as WebNLG, Ro- toWire, E2E or DART. Beyond traditional et al., 2019a), by either introducing content which token-overlap evaluation metrics (BLEU or is not warranted by the input or failing to express METEOR), a key concern faced by recent gen- some of the content which is part of the input. In erators is to control the factuality of the gen- fact, studies indicate that the training datasets also erated text with respect to the input data spec- suffer from problematic alignment between data ification. We report on our experience when and text (e.g., (Rebuffel et al., 2020) and (Dusekˇ developing an automatic factuality evaluation et al., 2019)), because large-scale data collection is system for data-to-text generation that we are complex. testing on WebNLG and E2E data. We aim to prepare gold data annotated manually to iden- In response, new evaluation metrics are being de- tify cases where the text communicates more veloped to assess the factuality of text with respect information than is warranted based on the in- to the input data. -

Militant South
07095 THE MILITANT SOUTH 18OO-1861 John Hope Franklin (c) Cupynfiht. WA. hv the I'trudent and telltttM of Pint a% a (trtutm * pubthhftl PaprrikttH /^^ f h\ wrangtment with ftwufd friurmfv Itfaeon l^nt ^/mA.ii r^ fmhluhnl uri^rr ^ f &t th* l nitantm tfnwrr UI/MI 4 |i,u>< iatitm, Printed in tHf f'm'ffrf S/rt/^s f .i Third fMinting, tfrtrmhn MOZELLA. .AJNTlSrE, BTJC1C (jTr Preface When the Union fell apart in 1861, it was not possible for anyone to answer all the questions that arose in the troubled minds o Americans regarding that catastrophe. In searching for an explanation of the tragic dissolution, thoughtful ob- servers looked at the political and philosophical bases of the nation's structure. They found that the controversial ques- tion of the autonomy of the states and the concept of liberty that had evolved offered a partial answer to the question. They examined the economic order and realized that be- tween a commercial-industrial section and one that was pre- dominantly agricultural there was basis for conflict. They looked into the structure of society in the two sections and concluded that there were inherent conflicts between that committed to the view that universal freedom was the proper foundation for improving the social order and the other that insisted that its half-free, half-slave society needed only to be left alone. continued to Questions of how and why the war came have baffle the minds of men in the generations since 1861. A notable lack of agreement, except on the point of the almost accumulation of hopeless complexity, and the remarkable have been details regarding the course of events prior to 1861 the most impressive results. -

3Dpageflip Ebook Maker Page 1 of 129 INTRODUCTION
3DPageFlip eBook Maker Page 1 of 129 INTRODUCTION After years of pondering over how awesome it would be to release a compilation of bands from all around the world, we have finally gone and done just that! We asked bands to submit a song and bio for this huge compilation and the response was fantastic. This free e-book is our way of saying thanks to the readers of Heavy Planet and a terrific way to promote some amazing bands spanning the Stoner Rock, Doom, Psychedelic and Sludge Metal genres. Many thanks goes out to all of the bands and labels for allowing us to use their music and most of all to you the readers for making Heavy Planet what it has become today. Cheers! Enjoy and Doom on! ~Reg 3DPageFlip eBook Maker Page 2 of 129 THE ALBUM TITLE I asked my talented group of writers to come up with a name for the compilation and a bunch of different titles were thrown around but one truly encapsulated what Heavy Planet is about. Misha suggested..."Bong Hits From the Astral Basement", we all agreed and here it is, sixty-one of the finest bands from all around the world. Following are the biographies of each band and the artist that contributed the killer artwork. 3DPageFlip eBook Maker Page 3 of 129 THE BANDS 1000MODS 1000mods is a psychedelic/stoner rock band from Chiliomodi, Greece. They were formed in the summer of 2006 and since then, they have played over 100 live shows, including openings for Brant Bjork, Colour Haze, Karma to Burn, My Sleeping Karma, Radio Moscow and many others. -

Supplementary Materials
Guo, Jin, Wang, Qiu, Zhang, Zhu, Zhang, Wipf Supplementary Materials The supplementary file includes additional content related to the following: 1. Synthetic Experiments (Section 5.1 in main paper): We explain why the synthetic data loosely align with Definition 1, describe the network architectures of the CycleBase and CycleCVAE models, and include additional generation results. 2. WebNLG Experiments (Section 5.2 in main paper): We describe the experimental setup for WebNLG, including the task description, cycle-consistency model design, and all baseline and implementation details. We also include an ablation study varying dim[z]. 3. T5 Extension (Section 5.3 in main paper): We provide details of the CycleCVAE+T5 extension and include additional generated samples showing textual diversity. 4. Proof of Proposition 2. 5. Proof of Corollary 3. 7 Synthetic Dataset Experimental Details and Additional Results 7.1 Dataset Description and Relation to Definition 1 To motivate how the synthetic data used in Section 5.1 from the main paper at least partially align with Definition 1, we let c and e be zero vectors and A 2 Rd×10 be a d × 10 transformation matrix from images to digits, where d is the total number of pixels in each image x. In other words, each column i 2 f0; 1;:::; 9g of A is a linearized pixel sequence of the 2D image of digit i from top left to bottom right. Based on A, we construct an example inverse matrix D so that DA = I. Specifically, D can be a 10 × d matrix where each row i 2 f0; 1;:::; 9g is a linearized pixel sequence of a masked version of the image of the digit i, and this image can have, for example, only one non-zero pixel that is sufficient to distinguish the digit i from all other nine possibilities.