PCL Iso8859/10 Latin 6 Page 1 of 5 PCL Iso8859/10 Latin 6
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Allowed Characters in the .VERSICHERUNG TLD
Allowed Characters in the .VERSICHERUNG TLD For technical support regarding the EPP interface, please contact our Registry Service provider, TLDBOX GmbH: Phone: +43 662 234548-730 E-Mail: [email protected] For non-technical Questions please contact our office: Phone: +49 4183 77 489-15 E-Mail: [email protected] .versicherung - allowed characters dotversicherung-registry GmbH, Itzenbütteler Mühlenweg 35a, 21227 Bendestorf, GERMANY T +49 4183-77489-15 , F +49 4183-77489-19, [email protected] Unicode Name Character U+002D HYPHEN-MINUS - U+0030 DIGIT ZERO 0 U+0031 DIGIT ONE 1 U+0032 DIGIT TWO 2 U+0033 DIGIT THREE 3 U+0034 DIGIT FOUR 4 U+0035 DIGIT FIVE 5 U+0036 DIGIT SIX 6 U+0037 DIGIT SEVEN 7 U+0038 DIGIT EIGHT 8 U+0039 DIGIT NINE 9 U+0061 LATIN SMALL LETTER A a U+0062 LATIN SMALL LETTER B b U+0063 LATIN SMALL LETTER C c U+0064 LATIN SMALL LETTER D d U+0065 LATIN SMALL LETTER E e U+0066 LATIN SMALL LETTER F f U+0067 LATIN SMALL LETTER G g U+0068 LATIN SMALL LETTER H h U+0069 LATIN SMALL LETTER I i U+006A LATIN SMALL LETTER J j U+006B LATIN SMALL LETTER K k U+006C LATIN SMALL LETTER L l U+006D LATIN SMALL LETTER M m U+006E LATIN SMALL LETTER N n U+006F LATIN SMALL LETTER O o U+0070 LATIN SMALL LETTER P p U+0071 LATIN SMALL LETTER Q q U+0072 LATIN SMALL LETTER R r U+0073 LATIN SMALL LETTER S s U+0074 LATIN SMALL LETTER T t U+0075 LATIN SMALL LETTER U u U+0076 LATIN SMALL LETTER V v U+0077 LATIN SMALL LETTER W w U+0078 LATIN SMALL LETTER X x U+0079 LATIN SMALL LETTER Y y U+007A LATIN SMALL LETTER Z z U+00DF LATIN SMALL -
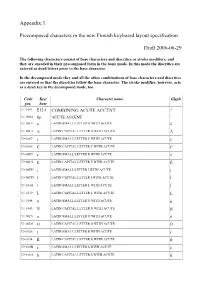
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02
Title: Encoding Finno-Ugric Phonetic Alphabet (FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02 The Finno-Ugric Phonetic Alphabet (FUPA) 0. Introduction This paper presents a collection of characters, diacritics, and notation marks used in the FUPA scheme. This transcription is and has been used creatively by different scientists in different countries at different times (Lagercrantz probably made the most baroque use of the system); therefore the phonetic or phonematic values of the elements of the FUPA are intentionally left aside here. However, all the users of this scheme have one thing in common: they use the FUPA in a technical way, as described below. We prefer the term ÒFUPAÓ to ÒFUTÓ (Finno- Ugric Transcription) because of its analogy to the IPA (International Phonetic Alphabet). It is not the intention of this paper to encourage exact (or over-exact) phonetic transcription or the extensive use of diacritics. The intention is rather to facilitate the use of the FUPA by the Uralicist community in the context of the Universal Character Set (UCS), by ensuring that a comprehensive analysis of the system leads to the possibility of encoding FUPA texts, past and present, with the UCS. In the exploratory versions of this document, firm advice on how to use FUPA will not be given; when the study is complete, however, advice on which characters in the UCS refer to whch letters used in the FUPA system will be given. An example of this, we believe, will be the advice for the LATIN SMALL LETTER ENG to be used in coded representations of FUPA texts, past and present, for the velar nasal, in preference to the GREEK SMALL LETTER ETA, although a great many printed texts use an eta glyph (Ç) and not an eng glyph (Ë). -

Multilingualism, the Needs of the Institutions of the European Community
COMMISSION Bruxelles le, 30 juillet 1992 DES COMMUNAUTÉS VERSION 4 EUROPÉENNES SERVICE DE TRADUCTION Informatique SdT-02 (92) D/466 M U L T I L I N G U A L I S M The needs of the Institutions of the European Community Adresse provisoire: rue de la Loi 200 - B-1049 Bruxelles, BELGIQUE Téléphone: ligne directe 295.00.94; standard 299.11.11; Telex: COMEU B21877 - Adresse télégraphique COMEUR Bruxelles - Télécopieur 295.89.33 Author: P. Alevantis, Revisor: Dorothy Senez, Document: D:\ALE\DOC\MUL9206.wp, Produced with WORDPERFECT for WINDOWS v. 5.1 Multilingualism V.4 - page 2 this page is left blanc Multilingualism V.4 - page 3 TABLE OF CONTENTS 0. INTRODUCTION 1. LANGUAGES 2. CHARACTER RÉPERTOIRE 3. ORDERING 4. CODING 5. KEYBOARDS ANNEXES 0. DEFINITIONS 1. LANGUAGES 2. CHARACTER RÉPERTOIRE 3. ADDITIONAL INFORMATION CONCERNING ORDERING 4. LIST OF KEYBOARDS REFERENCES Multilingualism V.4 - page 4 this page is left blanc Multilingualism V.4 - page 5 0. INTRODUCTION The Institutions of the European Community produce documents in all 9 official languages of the Community (French, English, German, Italian, Dutch, Danish, Greek, Spanish and Portuguese). The need to handle all these languages at the same time is a political obligation which stems from the Treaties and cannot be questionned. The creation of the European Economic Space which links the European Economic Community with the countries of the European Free Trade Association (EFTA) together with the continuing improvement in collaboration with the countries of Central and Eastern Europe oblige the European Institutions to plan for the regular production of documents in European languages other than the 9 official ones on a medium-term basis (i.e. -
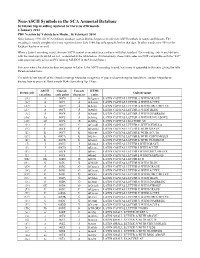
Non-ASCII Symbols in the SCA Armorial Database
Non-ASCII Symbols in the SCA Armorial Database by Iulstan Sigewealding, updated by Herveus d'Ormonde 4 January 2014 PDF Version by Yehuda ben Moshe, 16 February 2014 Since January 1996, the SCA Ordinary database (oanda.db) has begun to encode non-ASCII symbols in names and blazons. The encoding is mostly complete for items registered since July 1980, but only sporadic before that date. In other words, over 90% of the database has been revised. When a Latin-1 encoding exists, the non-ASCII symbol is encoded in accordance with that standard. The resulting code is an 8-bit byte with the most-significant bit set to 1, as detailed in the table below. (Unfortunately, these 8-bit codes are NOT compatible with the "437" code page normally active on PCs running MS-DOS in the United States.) For cases where the character does not appear in Latin-1, the ASCII encoding is used, but a note is appended to the entry giving the fully Da'ud encoded form. The table below lists all of the Da'ud encodings Morsulus recognizes. If you need something not listed there, contact Morsulus to discuss how to proceed. Don't simply Make Something Up. Please. ASCII Unicode Unicode HTML Da'ud code Unicode name encoding code point character entity {'A} A 00C0 À À LATIN CAPITAL LETTER A WITH GRAVE {A'} A 00C1 Á Á LATIN CAPITAL LETTER A WITH ACUTE {A^} A 00C2 Â Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX {A~} A 00C3 Ã Ã LATIN CAPITAL LETTER A WITH TILDE {A:} A 00C4 Ä Ä LATIN CAPITAL LETTER A WITH DIAERESIS {Ao} Aa 00C5 Å Å LATIN CAPITAL LETTER -

MSR-4: Annotated Repertoire Tables, Non-CJK
Maximal Starting Repertoire - MSR-4 Annotated Repertoire Tables, Non-CJK Integration Panel Date: 2019-01-25 How to read this file: This file shows all non-CJK characters that are included in the MSR-4 with a yellow background. The set of these code points matches the repertoire specified in the XML format of the MSR. Where present, annotations on individual code points indicate some or all of the languages a code point is used for. This file lists only those Unicode blocks containing non-CJK code points included in the MSR. Code points listed in this document, which are PVALID in IDNA2008 but excluded from the MSR for various reasons are shown with pinkish annotations indicating the primary rationale for excluding the code points, together with other information about usage background, where present. Code points shown with a white background are not PVALID in IDNA2008. Repertoire corresponding to the CJK Unified Ideographs: Main (4E00-9FFF), Extension-A (3400-4DBF), Extension B (20000- 2A6DF), and Hangul Syllables (AC00-D7A3) are included in separate files. For links to these files see "Maximal Starting Repertoire - MSR-4: Overview and Rationale". How the repertoire was chosen: This file only provides a brief categorization of code points that are PVALID in IDNA2008 but excluded from the MSR. For a complete discussion of the principles and guidelines followed by the Integration Panel in creating the MSR, as well as links to the other files, please see “Maximal Starting Repertoire - MSR-4: Overview and Rationale”. Brief description of exclusion -

Symbols & Glyphs 1
Symbols & Glyphs Content Shortcut Category ← leftwards-arrow Arrows ↑ upwards-arrow Arrows → rightwards-arrow Arrows ↓ downwards-arrow Arrows ↔ left-right-arrow Arrows ↕ up-down-arrow Arrows ↖ north-west-arrow Arrows ↗ north-east-arrow Arrows ↘ south-east-arrow Arrows ↙ south-west-arrow Arrows ↚ leftwards-arrow-with-stroke Arrows ↛ rightwards-arrow-with-stroke Arrows ↜ leftwards-wave-arrow Arrows ↝ rightwards-wave-arrow Arrows ↞ leftwards-two-headed-arrow Arrows ↟ upwards-two-headed-arrow Arrows ↠ rightwards-two-headed-arrow Arrows ↡ downwards-two-headed-arrow Arrows ↢ leftwards-arrow-with-tail Arrows ↣ rightwards-arrow-with-tail Arrows ↤ leftwards-arrow-from-bar Arrows ↥ upwards-arrow-from-bar Arrows ↦ rightwards-arrow-from-bar Arrows ↧ downwards-arrow-from-bar Arrows ↨ up-down-arrow-with-base Arrows ↩ leftwards-arrow-with-hook Arrows ↪ rightwards-arrow-with-hook Arrows ↫ leftwards-arrow-with-loop Arrows ↬ rightwards-arrow-with-loop Arrows ↭ left-right-wave-arrow Arrows ↮ left-right-arrow-with-stroke Arrows ↯ downwards-zigzag-arrow Arrows 1 ↰ upwards-arrow-with-tip-leftwards Arrows ↱ upwards-arrow-with-tip-rightwards Arrows ↵ downwards-arrow-with-tip-leftwards Arrows ↳ downwards-arrow-with-tip-rightwards Arrows ↴ rightwards-arrow-with-corner-downwards Arrows ↵ downwards-arrow-with-corner-leftwards Arrows anticlockwise-top-semicircle-arrow Arrows clockwise-top-semicircle-arrow Arrows ↸ north-west-arrow-to-long-bar Arrows ↹ leftwards-arrow-to-bar-over-rightwards-arrow-to-bar Arrows ↺ anticlockwise-open-circle-arrow Arrows ↻ clockwise-open-circle-arrow -

Considerations in the Identification and Management of Variant Elements in Latin Script Tables for IDN Registration
Considerations in the identification and management of variant elements in Latin script tables for IDN registration Cary Karp Swedish Museum of Natural History This Support Brief was contributed to the ICANN VIP initiative by the host of its Latin script study, the Internet Infrastructure Foundation, with the support of the Swedish Museum of Natural History. The code points available for use in IDNs are all taken from the Unicode Character Code Charts. The Latin script is divided there into nine blocks. The one headed “Basic Latin” restates the ASCII repertoire and therefore includes the familiar letter-digit-hyphen (“LDH”) array to which TLD registries previously restricted all second-level domain names. The TLD labels, themselves, were further restricted to the letters in that repertoire. Latin letters other than the ‘a–z’ encoded in ASCII, as well as diacritically marked and otherwise decorated forms are presented in supplemental and extended Latin blocks, with further Latin letters in blocks under the heading “Phonetic Symbols”. Many of the marked letters can be represented with differing series of code points. Other letters that are intrinsically different and have different code points may share the same glyph. Protocol constraint renders the first of these situations tractable. Contextual restriction on the use of certain code points is necessary for the second. Basic concepts and considerations in the protocol and contextual management of these conditions are discussed below, with specific regard to the local collation of permissible IDN character repertoires and the identification of variant relationships among the listed characters. The rubric “Support Brief” indicates the intention of this text serving as a source document for the study group’s deliberations and report, without being a structured work in itself. -

Unicode in Vitalware 3.0
Vitalware Documentation Unicode in Vitalware 3.0 Document Version 1 Vitalware 3.0 Contents SECTION 1 Unicode 1 Overview 1 Code Points 3 Inputting Unicode Characters 6 Graphemes 10 Index Terms 11 SECTION 2 Searching 15 Transformations 17 Regular Expressions 18 Anchors 19 Proximity 20 Conditionals 22 SECTION 3 Auto‐phrasing 23 SECTION 4 Collation 25 SECTION 5 Lookup Lists 27 Index 29 Unicode S ECTION 1 Unicode Overview Vitalware 3.0 sees implementation of support for the Unicode 8.0 (http://www.unicode.org/versions/Unicode8.0.0/) standard. While earlier versions of Vitalware allowed Unicode characters to be stored and retrieved, the system did not interpret the characters entered, leading to very limited searching functionality. In order to retrieve a Unicode character it was necessary to enter the search term in exactly the same case (upper or lower) along with the same diacritics. For example, a search for the name Frederic would not match Fréderic as the e acute character was not interpreted as an e character with a diacritic associated with it. Vitalware 3.0 supports case folding and base character mapping: Case folding is similar to converting a character to its lower case equivalent except that it handles some special cases. The purpose of case folding is to make searching case insensitive. One special case is that the German lower case sharp s character (ß) is generally written in upper case as SS. So Großen would be converted to GROSSEN in upper case. When searching we would like to enter either of the previous terms and find all case variations. -

Unicode Glyph Example Languages Using the Code Point
Unicode Glyph Example EGIDS ISO Population Ref Unicode Comments languages using 639- the code point 3 (note: not an exhaustive list of languages using the code point) 00DF ß German 1 German deu 78,093,980 CLDR LATIN SMALL LETTER May only appear in the middle or at the end of a label. SHARP S IDNA version issues. 00E0 à Portuguese, 1 Portuguese por 203,352,100 CLDR LATIN SMALL LETTER French A WITH GRAVE 00E1 á Spanish 1 Spanish spa 398,931,840 CLDR LATIN SMALL LETTER A WITH ACUTE 00E2 â Portuguese, 1 Portuguese por 203,352,100 CLDR LATIN SMALL LETTER More information about circumflex use in Turkish: French, Turkish A WITH CIRCUMFLEX https://en.wikipedia.org/wiki/Turkish_alphabet in the Distinctive Features section. 00E3 ã Portuguese 1 Portuguese por 203,352,100 CLDR LATIN SMALL LETTER A WITH TILDE 00E4 ä German, Swedish, 1 German deu 78,093,980 CLDR LATIN SMALL LETTER Turkmen A WITH DIAERESIS 00E5 å Swedish, 1 Swedish swe 9,197,090 CLDR LATIN SMALL LETTER Norwegian A WITH RING ABOVE 00E6 æ French, Danish 1 French fra 75,916,150 CLDR LATIN SMALL LETTER AE 00E7 ç Portuguese, 1 Portuguese por 203,352,100 CLDR LATIN SMALL LETTER Catalan, Turkish C WITH CEDILLA 00E8 è French, Italian 1 French fra 75,916,150 CLDR LATIN SMALL LETTER E WITH GRAVE 00E9 é Spanish, French 1 Spanish spa 398,931,840 CLDR LATIN SMALL LETTER E WITH ACUTE 00EA ê Portuguese, 1 Portuguese por 203,352,100 CLDR LATIN SMALL LETTER French E WITH CIRCUMFLEX 00EB ë French, Dutch 1 French fra 75,916,150 CLDR LATIN SMALL LETTER E WITH DIAERESIS 00EC ì Italian 1 Italian ita 63,783,247 CLDR LATIN SMALL LETTER I WITH GRAVE 00ED í Spanish 1 Spanish spa 398,931,840 CLDR LATIN SMALL LETTER I WITH ACUTE 00EE î French, Turkish 1 French fra 75,916,150 CLDR LATIN SMALL LETTER I More information about circumflex use in Turkish: WITH CIRCUMFLEX https://en.wikipedia.org/wiki/Turkish_alphabet in the Distinctive Features section.