Considerations in the Use of the Latin Script in Variant Internationalized Top-Level Domains
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PROC SORT (Then And) NOW Derek Morgan, PAREXEL International
Paper 143-2019 PROC SORT (then and) NOW Derek Morgan, PAREXEL International ABSTRACT The SORT procedure has been an integral part of SAS® since its creation. The sort-in-place paradigm made the most of the limited resources at the time, and almost every SAS program had at least one PROC SORT in it. The biggest options at the time were to use something other than the IBM procedure SYNCSORT as the sorting algorithm, or whether you were sorting ASCII data versus EBCDIC data. These days, PROC SORT has fallen out of favor; after all, PROC SQL enables merging without using PROC SORT first, while the performance advantages of HASH sorting cannot be overstated. This leads to the question: Is the SORT procedure still relevant to any other than the SAS novice or the terminally stubborn who refuse to HASH? The answer is a surprisingly clear “yes". PROC SORT has been enhanced to accommodate twenty-first century needs, and this paper discusses those enhancements. INTRODUCTION The largest enhancement to the SORT procedure is the addition of collating sequence options. This is first and foremost recognition that SAS is an international software package, and SAS users no longer work exclusively with English-language data. This capability is part of National Language Support (NLS) and doesn’t require any additional modules. You may use standard collations, SAS-provided translation tables, custom translation tables, standard encodings, or rules to produce your sorted dataset. However, you may only use one collation method at a time. USING STANDARD COLLATIONS, TRANSLATION TABLES AND ENCODINGS A long time ago, SAS would allow you to sort data using ASCII rules on an EBCDIC system, and vice versa. -

Brand Book Cover 2021.Pub
RR PP Commissioner QQ BB BB Rਤਦਨਲਲ਼ਤਤਣ Bਠਭਣਲ ਠਲ ਮਥ MARCH 31, 2021 REMEMBER TO REGISTER YOUR BRAND 2021 BRAND RENEWAL YEAR Alabama Law requires any livestock owner who uses a brand to identify their livestock must register their brand with the Alabama Department of Agriculture and Industries. Brands are renewed every three years. Renewals Start September 2021. Pursuant to §2-15-21 & §2-15-23 Code of Alabama 1975 S B S 1445 Federal Drive · Montgomery, Alabama 36107-1123 Rick Pate 334-240-7304 · 800-642-7761 Ext. 7304 Commissioner APPLICATION FOR LIVESTOCK BRAND REGISTRATION FOR REGISTRATION PERIOD OCTOBER 1, 2028—SEPTEMBER 30, 2021 (Please Print or Type) Date: __________________ Name: _________________________________________________________________ Business Name: _________________________________________________________________ Address: _________________________________________________________________ (Street) (City) (State) (Zip) Phone: ___________________________ E-Mail: _____________________________ County: _______________________ Livestock Type: ___________________________ Signature: _____________________________________________________________________ I hereby make application for a recorded brand to be used on livestock. IMPORTANT NOTICE Do not have irons made or brand any stock until you have received your brand certificate. BRAND EXAMPLES WITH VERBAL DESCRIPTIONS RJ LJ LJ - Left Jaw RJ - Right Jaw THERE IS A RECORDING FEE OF $ 20.00 FOR THE FIRST LOCATION AND A $ 4.00 FEE FOR EACH ADDITIONAL LOCATION. CIRCLE LOCATION YOU WISH TO RESERVE RH LH RR LR RS LS RJ LJ 1st Choice 2nd Choice 3rd Choice Verbal Description: 1st Choice _______________________________________________ 2nd Choice _______________________________________________ 3rd Choice _______________________________________________ Duplicate brands cannot be registered. Give your second and third choices to save any delays in the event your first choice has been already registered. Draw your brand exactly as it will appear on the animal. -

A Universal Amazigh Keyboard for Latin Script and Tifinagh
LES RESSOURCES LANGAGIERES : CONSTRUCTION ET EXPLOITATION A universal Amazigh keyboard for Latin script and Tifinagh Paul Anderson [email protected] 1. Introduction Systems of Amazigh text encoding and corresponding keyboard layouts have tended to be narrowly aimed at specific user communities, because of differences in phonology and orthography across Amazigh language variants1. Keyboard layouts for language variants have therefore lacked orthographic features found in other regions. This restricted focus impedes users' experimentation with the writing of other Amazigh regional variants and converged literary forms where they differ in orthographic features or in script. So far there has been no way to type more than a handful of Amazigh variants intuitively on any one layout even within one script. This fragmented development has meant that keyboard driver implementations have often lagged behind advances in technology, and have usually failed to take into account general keyboard layout design, ergonomy and typing speed, and solutions from other Amazigh regions or non-Amazigh languages. Some users even preferred to improvise key definitions based on their own understanding, which often resulted in mistaken use of lookalike letters and diacritics. Keyboard layouts have also failed to provide for Amazigh minority populations around the world, and have considered the multilingual context of Amazigh language use only locally. Several scripts are commonly used to write Amazigh variants, and even within a script there are different orthographies in use. Some orthographies are formal 1 I use the term 'language variant' since distinguishing 'dialect' and 'language' is not necessary here. ~ 165 ~ LES RESSOURCES LANGAGIERES : CONSTRUCTION ET EXPLOITATION standards. In others, some features are obsolete but still in use, some features are still disputed, and some features are regional usages or personal initiatives, or are required only for writing more phonetically. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

The Unicode Standard, Version 6.1 This File Contains an Excerpt from the Character Code Tables and List of Character Names for the Unicode Standard, Version 6.1
Latin Extended-D Range: A720–A7FF The Unicode Standard, Version 6.1 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 6.1. Characters in this chart that are new for The Unicode Standard, Version 6.1 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-6.1/ for charts showing only the characters added in Unicode 6.1. See http://www.unicode.org/Public/6.1.0/charts/ for a complete archived file of character code charts for Unicode 6.1. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 6.1 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 6.1, online at http://www.unicode.org/versions/Unicode6.1.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -

Computer Science II
Computer Science II Dr. Chris Bourke Department of Computer Science & Engineering University of Nebraska|Lincoln Lincoln, NE 68588, USA http://chrisbourke.unl.edu [email protected] 2019/08/15 13:02:17 Version 0.2.0 This book is a draft covering Computer Science II topics as presented in CSCE 156 (Computer Science II) at the University of Nebraska|Lincoln. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License i Contents 1 Introduction1 2 Object Oriented Programming3 2.1 Introduction.................................... 3 2.2 Objects....................................... 4 2.3 The Four Pillars.................................. 4 2.3.1 Abstraction................................. 4 2.3.2 Encapsulation................................ 4 2.3.3 Inheritance ................................. 4 2.3.4 Polymorphism................................ 4 2.4 SOLID Principles................................. 4 2.4.1 Inversion of Control............................. 4 3 Relational Databases5 3.1 Introduction.................................... 5 3.2 Tables ....................................... 9 3.2.1 Creating Tables...............................10 3.2.2 Primary Keys................................16 3.2.3 Foreign Keys & Relating Tables......................18 3.2.4 Many-To-Many Relations .........................22 3.2.5 Other Keys .................................24 3.3 Structured Query Language ...........................26 3.3.1 Creating Data................................28 3.3.2 Retrieving Data...............................30 -

Plaquette De Présentation De Bépo Est Sous Double Licence CC-BY-SA Et GFDL ©2014 Association Ergodis, Avec L’Aimable Collaboration De Ploum
Installation moins Bépo s’installe sur la plupart des systèmes , de (Windows, OSX, BSD, Android) et est déjà inclus s dans GNU/Linux, Haiku et FirefoxOS. t m Vous pouvez également télécharger l’archive o « nomade » qui vous permet d’utiliser bépo a partout où vous allez sans avoir besoin d’installer m u préalablement un logiciel. x Rien n’est définitif ! il vous est toujours possible de e basculer en un clic sur votre ancienne disposition. d Apprentissage s u Bépo est conçu pour une utilisation en l aveugle à dix doigts, c’est plus facile P qu’on peut le penser et plus confortable. Choisissez un logiciel de dactylographie et pratiquez les exercices pendant 10 à 15 minutes par jour. la disposition de clavier L’apprentissage de bépo est simplifié par ergonomique, francophone et le fait que dès les premières leçons, vous libre écrivez de vrais mots et non des suites de lettres dénuées de sens. De plus, les caractères de la couche AltGr par l’association sont installés de manière mnémotechnique. Même sans pratique, vous n’oublierez pas les acquis de votre ancienne disposition : C’est comme le vélo, un petit temps d’adaptation et c’est reparti ! Claviers Un clavier avec un marquage particulier Tapez facilement à dix doigts n’est pas nécessaire et est même dans votre langue. contre-indiqué lors de l’apprentissage. http://bepo.fr/ Cependant, il existe des autocollants à coller sur vos touches permettant Notre communauté est prête à d’adapter un clavier existant et même répondre à toutes vos questions. -

Ffontiau Cymraeg
This publication is available in other languages and formats on request. Mae'r cyhoeddiad hwn ar gael mewn ieithoedd a fformatau eraill ar gais. [email protected] www.caerphilly.gov.uk/equalities How to type Accented Characters This guidance document has been produced to provide practical help when typing letters or circulars, or when designing posters or flyers so that getting accents on various letters when typing is made easier. The guide should be used alongside the Council’s Guidance on Equalities in Designing and Printing. Please note this is for PCs only and will not work on Macs. Firstly, on your keyboard make sure the Num Lock is switched on, or the codes shown in this document won’t work (this button is found above the numeric keypad on the right of your keyboard). By pressing the ALT key (to the left of the space bar), holding it down and then entering a certain sequence of numbers on the numeric keypad, it's very easy to get almost any accented character you want. For example, to get the letter “ô”, press and hold the ALT key, type in the code 0 2 4 4, then release the ALT key. The number sequences shown from page 3 onwards work in most fonts in order to get an accent over “a, e, i, o, u”, the vowels in the English alphabet. In other languages, for example in French, the letter "c" can be accented and in Spanish, "n" can be accented too. Many other languages have accents on consonants as well as vowels. -

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

Jtc1/Sc2/Wg2 N2945
JTC1/SC2/WG2 N2945 ISO/IEC JTC 1/SC 2/WG 2 PROPOSAL SUMMARY FORM TO ACCOMPANY SUBMISSIONS FOR ADDITIONS TO THE REPERTOIRE OF ISO/IEC 106461 Please fill all the sections A, B and C below. Please read Principles and Procedures Document (P & P) from http://www.dkuug.dk/JTC1/SC2/WG2/docs/principles.html for guidelines and details before filling this form. Please ensure you are using the latest Form from http://www.dkuug.dk/JTC1/SC2/WG2/docs/summaryform.html. See also http://www.dkuug.dk/JTC1/SC2/WG2/docs/roadmaps.html for latest Roadmaps. A. Administrative 1. Title: Proposal to Encode Additional Latin Phonetic and Orthographic Characters 2. Requester's name: Lorna A. Priest, Peter G. Constable 3. Requester type (Member body/Liaison/Individual contribution): Individual contribution 4. Submission date: 31 March 2005 (revised 9 August 2005) 5. Requester's reference (if applicable): L2/05-097R 6. Choose one of the following: This is a complete proposal: Yes or, More information will be provided later: No B. Technical – General 1. Choose one of the following: a. This proposal is for a new script (set of characters): No Proposed name of script: b. The proposal is for addition of character(s) to an existing block: Yes Name of the existing block: Modifier letters, Latin Extended 2. Number of characters in proposal: 12 3. Proposed category (select one from below - see section 2.2 of P&P document): A-Contemporary x B.1-Specialized (small collection) B.2-Specialized (large collection) C-Major extinct D-Attested extinct E-Minor extinct F-Archaic Hieroglyphic or Ideographic G-Obscure or questionable usage symbols 4. -
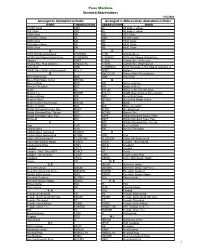
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10.