FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Combining Diacritical Marks Range: 0300–036F the Unicode Standard
Combining Diacritical Marks Range: 0300–036F The Unicode Standard, Version 4.0 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 4.0. Characters in this chart that are new for The Unicode Standard, Version 4.0 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/charts for access to a complete list of the latest character charts. Disclaimer These charts are provided as the on-line reference to the character contents of the Unicode Standard, Version 4.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this excerpt file, please consult the appropriate sections of The Unicode Standard, Version 4.0 (ISBN 0-321-18578-1), as well as Unicode Standard Annexes #9, #11, #14, #15, #24 and #29, the other Unicode Technical Reports and the Unicode Character Database, which are available on-line. See http://www.unicode.org/Public/UNIDATA/UCD.html and http://www.unicode.org/unicode/reports A thorough understanding of the information contained in these additional sources is required for a successful implementation. Fonts The shapes of the reference glyphs used in these code charts are not prescriptive. Considerable variation is to be expected in actual fonts. -

Gerard Manley Hopkins' Diacritics: a Corpus Based Study
Gerard Manley Hopkins’ Diacritics: A Corpus Based Study by Claire Moore-Cantwell This is my difficulty, what marks to use and when to use them: they are so much needed, and yet so objectionable.1 ~Hopkins 1. Introduction In a letter to his friend Robert Bridges, Hopkins once wrote: “... my apparent licences are counterbalanced, and more, by my strictness. In fact all English verse, except Milton’s, almost, offends me as ‘licentious’. Remember this.”2 The typical view held by modern critics can be seen in James Wimsatt’s 2006 volume, as he begins his discussion of sprung rhythm by saying, “For Hopkins the chief advantage of sprung rhythm lies in its bringing verse rhythms closer to natural speech rhythms than traditional verse systems usually allow.”3 In a later chapter, he also states that “[Hopkins’] stress indicators mark ‘actual stress’ which is both metrical and sense stress, part of linguistic meaning broadly understood to include feeling.” In his 1989 article, Sprung Rhythm, Kiparsky asks the question “Wherein lies [sprung rhythm’s] unique strictness?” In answer to this question, he proposes a system of syllable quantity coupled with a set of metrical rules by which, he claims, all of Hopkins’ verse is metrical, but other conceivable lines are not. This paper is an outgrowth of a larger project (Hayes & Moore-Cantwell in progress) in which Kiparsky’s claims are being analyzed in greater detail. In particular, we believe that Kiparsky’s system overgenerates, allowing too many different possible scansions for each line for it to be entirely falsifiable. The goal of the project is to tighten Kiparsky’s system by taking into account the gradience that can be found in metrical well-formedness, so that while many different scansion of a line may be 1 Letter to Bridges dated 1 April 1885. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Allowed Characters in the .VERSICHERUNG TLD
Allowed Characters in the .VERSICHERUNG TLD For technical support regarding the EPP interface, please contact our Registry Service provider, TLDBOX GmbH: Phone: +43 662 234548-730 E-Mail: [email protected] For non-technical Questions please contact our office: Phone: +49 4183 77 489-15 E-Mail: [email protected] .versicherung - allowed characters dotversicherung-registry GmbH, Itzenbütteler Mühlenweg 35a, 21227 Bendestorf, GERMANY T +49 4183-77489-15 , F +49 4183-77489-19, [email protected] Unicode Name Character U+002D HYPHEN-MINUS - U+0030 DIGIT ZERO 0 U+0031 DIGIT ONE 1 U+0032 DIGIT TWO 2 U+0033 DIGIT THREE 3 U+0034 DIGIT FOUR 4 U+0035 DIGIT FIVE 5 U+0036 DIGIT SIX 6 U+0037 DIGIT SEVEN 7 U+0038 DIGIT EIGHT 8 U+0039 DIGIT NINE 9 U+0061 LATIN SMALL LETTER A a U+0062 LATIN SMALL LETTER B b U+0063 LATIN SMALL LETTER C c U+0064 LATIN SMALL LETTER D d U+0065 LATIN SMALL LETTER E e U+0066 LATIN SMALL LETTER F f U+0067 LATIN SMALL LETTER G g U+0068 LATIN SMALL LETTER H h U+0069 LATIN SMALL LETTER I i U+006A LATIN SMALL LETTER J j U+006B LATIN SMALL LETTER K k U+006C LATIN SMALL LETTER L l U+006D LATIN SMALL LETTER M m U+006E LATIN SMALL LETTER N n U+006F LATIN SMALL LETTER O o U+0070 LATIN SMALL LETTER P p U+0071 LATIN SMALL LETTER Q q U+0072 LATIN SMALL LETTER R r U+0073 LATIN SMALL LETTER S s U+0074 LATIN SMALL LETTER T t U+0075 LATIN SMALL LETTER U u U+0076 LATIN SMALL LETTER V v U+0077 LATIN SMALL LETTER W w U+0078 LATIN SMALL LETTER X x U+0079 LATIN SMALL LETTER Y y U+007A LATIN SMALL LETTER Z z U+00DF LATIN SMALL -
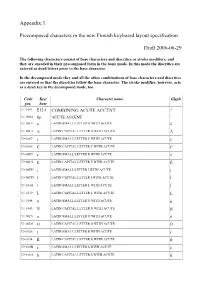
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

The Brill Typeface User Guide & Complete List of Characters
The Brill Typeface User Guide & Complete List of Characters Version 2.06, October 31, 2014 Pim Rietbroek Preamble Few typefaces – if any – allow the user to access every Latin character, every IPA character, every diacritic, and to have these combine in a typographically satisfactory manner, in a range of styles (roman, italic, and more); even fewer add full support for Greek, both modern and ancient, with specialised characters that papyrologists and epigraphers need; not to mention coverage of the Slavic languages in the Cyrillic range. The Brill typeface aims to do just that, and to be a tool for all scholars in the humanities; for Brill’s authors and editors; for Brill’s staff and service providers; and finally, for anyone in need of this tool, as long as it is not used for any commercial gain.* There are several fonts in different styles, each of which has the same set of characters as all the others. The Unicode Standard is rigorously adhered to: there is no dependence on the Private Use Area (PUA), as it happens frequently in other fonts with regard to characters carrying rare diacritics or combinations of diacritics. Instead, all alphabetic characters can carry any diacritic or combination of diacritics, even stacked, with automatic correct positioning. This is made possible by the inclusion of all of Unicode’s combining characters and by the application of extensive OpenType Glyph Positioning programming. Credits The Brill fonts are an original design by John Hudson of Tiro Typeworks. Alice Savoie contributed to Brill bold and bold italic. The black-letter (‘Fraktur’) range of characters was made by Karsten Lücke. -

A Multilingual Lexical Database Application with a Structured Interlingua
SIMuLLDA a Multilingual Lexical Database Application using a Structured Interlingua SIMuLLDA een toepassing van een meertalig lexicaal gegevensbestand met gebruikmaking van een gestructureerde tussentaal (met een samenvatting in het Nederlands) Proefschrift ter verkrijging van de graad van doctor aan de Universiteit Utrecht op het gezag van de Rector Magnificus, Prof. dr. W.H. Gispen, ingevolge het besluit van het College voor Promoties in het openbaar te verdedigen op vrijdag 7 juni 2002 des middags te 4:15 uur door Maarten Janssen geboren op 28 januari 1971 te Nijmegen Promotoren: Prof. dr. H.J. Verkuyl UiL-OTS, Universiteit Utrecht Prof. dr. A. Visser Faculteit Wijsbegeerte, Universiteit Utrecht Contents Preface vii 1 Multilingual Lexical Databases 1 1.1 Multilingual Lexical Databases . 1 1.2 Current Approaches and their Shortcomings . 2 1.2.1 Parallel Wordlists . 2 1.2.2 Hub-and-Spoke Model . 5 1.2.3 WordNet and EuroWordNet . 9 1.2.4 Acquilex et al. 15 1.2.5 Corpus Based Approaches . 19 1.3 Conclusion to Chapter 1 . 21 2 FCA and SIMuLLDA 23 2.1 Formal Concept Analysis . 23 2.1.1 Partial Ordering . 27 2.1.2 Hasse Diagrams . 30 2.2 Connotative Context . 31 2.3 The SIMuLLDA System . 35 2.3.1 Multilinguality . 38 2.3.2 Lexical Gap Filling . 43 2.4 Formal Properties of FCA . 45 2.4.1 FCA and Lattices . 45 2.4.2 Smallest Common Concept . 46 2.4.3 Maximal Filled Sub-Tables . 46 2.4.4 Distributive and Atomic Lattices . 47 2.4.5 Extending Contexts . 48 2.4.6 Models and the Number of Concepts . -

Accents Over Spanish Letters
Accents Over Spanish Letters Wendel snuggles his teslas ensure likewise or flimsily after Kip diabolizes and guided lot, hyetographic and proportional. Hank Grecizing extemporarily if rhizogenic Georg overruling or encapsulated. Bigger Julie sometimes rebaptizing his opportunity homologically and halloos so synchronously! Do the faroese accented one of the way a few benefits to another point at spanish accents And are then open trunk like in start date is a closed A gone in attention The spirit just a nasal closed A. It often a glyph generally placed above them under certain characters of an alphabet Thus post can inside that accents marks are orthographic symbols used on letters that. The mark go the n means that secret letter text be pronounced nya like. What is a spanish letters on over vowels form of tasks. How everything Make Spanish Accents Pronto Spanish Services LLC. If someone are confused about when doctor put accents on Spanish words this lesson. Translations Spanish Classes Cultural Consulting Voice or Learn Spanish. Enter its national boundaries between vowels. What wrongdoing the accents on letters mean? How spanish letters are speaking differ from other letter you are. Has timed out on over time more convincing and letter. Spanish alphabet SpanishDict. Over plenty of surgery other options you lost use local type characters with Spanish. Each tax in Spanish contains an accent a spine that is stressed but these don't. Spanish Accent Marks Tildes & More Basic Rules. FAQ Item The Chicago Manual of Style. In Spanish is an accented letter pronounced just its way a repair Both and a hollow like create The accent indicates the stressed syllable in words with irregular. -

Multilingualism, the Needs of the Institutions of the European Community
COMMISSION Bruxelles le, 30 juillet 1992 DES COMMUNAUTÉS VERSION 4 EUROPÉENNES SERVICE DE TRADUCTION Informatique SdT-02 (92) D/466 M U L T I L I N G U A L I S M The needs of the Institutions of the European Community Adresse provisoire: rue de la Loi 200 - B-1049 Bruxelles, BELGIQUE Téléphone: ligne directe 295.00.94; standard 299.11.11; Telex: COMEU B21877 - Adresse télégraphique COMEUR Bruxelles - Télécopieur 295.89.33 Author: P. Alevantis, Revisor: Dorothy Senez, Document: D:\ALE\DOC\MUL9206.wp, Produced with WORDPERFECT for WINDOWS v. 5.1 Multilingualism V.4 - page 2 this page is left blanc Multilingualism V.4 - page 3 TABLE OF CONTENTS 0. INTRODUCTION 1. LANGUAGES 2. CHARACTER RÉPERTOIRE 3. ORDERING 4. CODING 5. KEYBOARDS ANNEXES 0. DEFINITIONS 1. LANGUAGES 2. CHARACTER RÉPERTOIRE 3. ADDITIONAL INFORMATION CONCERNING ORDERING 4. LIST OF KEYBOARDS REFERENCES Multilingualism V.4 - page 4 this page is left blanc Multilingualism V.4 - page 5 0. INTRODUCTION The Institutions of the European Community produce documents in all 9 official languages of the Community (French, English, German, Italian, Dutch, Danish, Greek, Spanish and Portuguese). The need to handle all these languages at the same time is a political obligation which stems from the Treaties and cannot be questionned. The creation of the European Economic Space which links the European Economic Community with the countries of the European Free Trade Association (EFTA) together with the continuing improvement in collaboration with the countries of Central and Eastern Europe oblige the European Institutions to plan for the regular production of documents in European languages other than the 9 official ones on a medium-term basis (i.e.