MUFI Character Recommendation V. 3.0: Alphabetical Order
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

8 December 2004 (Revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California
To: LSA and UC Berkeley Communities From: Deborah Anderson, UCB representative and LSA liaison Date: 8 December 2004 (revised 10 January 2005) Topic: Unicode Technical Meeting #101, 15 -18 November 2004, Cupertino, California As the UC Berkeley representative and LSA liaison, I am most interested in the proposals for new characters and scripts that were discussed at the UTC, so these topics are the focus of this report. For the full minutes, readers should consult the "Unicode Technical Committee Minutes" web page (http://www.unicode.org/consortum/utc-minutes.html), where the minutes from this meeting will be posted several weeks hence. I. Proposals for New Scripts and Additional Characters A summary of the proposals and the UTC's decisions are listed below. As the proposals discussed below are made public, I will post the URLs on the SEI web page (www.linguistics.berkeley.edu/sei). A. Linguistics Characters Lorna Priest of SIL International submitted three proposals for additional linguistics characters. Most of the characters proposed are used in the orthographies of languages from Africa, Asia, Mexico, Central and South America. (For details on the proposed characters, with a description of their use and an image, see the appendix to this document.) Two characters from these proposals were not approved by the UTC because there are already characters encoded that are very similar. The evidence did not adequately demonstrate that the proposed characters are used distinctively. The two problematical proposed characters were: the modifier straight letter apostrophe (used for a glottal stop, similar to ' APOSTROPHE U+0027) and the Latin small "at" sign (used for Arabic loanwords in an orthography for the Koalib language from the Sudan, similar to @ COMMERCIAL AT U+0040). -

Music 1000 Songs, 2.8 Days, 5.90 GB
Music 1000 songs, 2.8 days, 5.90 GB Name Time Album Artist Drift And Die 4:25 Alternative Times Vol 25 Puddle Of Mudd Weapon Of Choice 2:49 Alternative Times Vol 82 Black Rebel Motorcycle Club You'll Be Under My Wheels 3:52 Always Outnumbered, Never Outg… The Prodigy 08. Green Day - Boulevard Of Bro… 4:20 American Idiot Green Day Courage 3:30 ANThology Alien Ant Farm Movies 3:15 ANThology Alien Ant Farm Flesh And Bone 4:28 ANThology Alien Ant Farm Whisper 3:25 ANThology Alien Ant Farm Summer 4:15 ANThology Alien Ant Farm Sticks And Stones 3:16 ANThology Alien Ant Farm Attitude 4:54 ANThology Alien Ant Farm Stranded 3:57 ANThology Alien Ant Farm Wish 3:21 ANThology Alien Ant Farm Calico 4:10 ANThology Alien Ant Farm Death Day 4:33 ANThology Alien Ant Farm Smooth Criminal 3:29 ANThology Alien Ant Farm Universe 9:07 ANThology Alien Ant Farm The Weapon They Fear 4:38 Antigone Heaven Shall Burn To Harvest The Storm 4:45 Antigone Heaven Shall Burn Tree Of Freedom 4:49 Antigone Heaven Shall Burn Voice Of The Voiceless 4:53 Antigone (Slipcase - Edition) Heaven Shall Burn Rain 4:11 Ascendancy Trivium laid to rest 3:49 ashes of the wake lamb of god Now You've Got Something to Die … 3:39 Ashes Of The Wake Lamb Of God Relax Your Mind 4:07 Bad Boys 2 Soundtrack Loon Intro 0:12 Bad Boys 2 Soundtrack Bad Boys 2 Soundtrack Show Me Your Soul 5:20 Bad Boys 2 Soundtrack Loon Feat. -

Financial Fragility and Neoliberalism in Developing Countries
Financial Fragility and Neoliberalism in Developing Countries Andrés Blancas• Abstract The aim of this paper is to show the financial fragility dynamics in developing countries following the last theoretical advances. As an empirical application we prove that the Mexican economy has been characterized by financial fragility, mainly during the crisis terms. Financial fragility has created difficult problems for policy makers; in trying to fix it by restricted monetary and fiscal policies, they have triggered the generalized financial crises. Whereby, financial fragility can be diagnosed as an structural problem of developing countries like Mexico and a real potential risk of generalized economic crisis in the process of economic liberalization nowadays. Key Words: Economic dynamics, financial fragility, developing countries, financial crisis, monetary policy and Mexican economy JEL Classification: C61, E44, E58, F34, O5 1 Introduction The 1990s financial crises in developing and newly industrializing countries exemplify the risk of financial volatility and economic instability that has accompanied the economic liberalization and the deregulation of financial markets. For these countries, particularly in Asia and Latin America, the first part of the 1990s was distinguished by hopeful and cheerful • Institute of Economic Research, UNAM. 2007 E-mail address: [email protected]. Telephone number: (525)55623-0125, FAX number: (525)55623-0199. Helpful comments and suggestions from Duncan Foley and Lance Taylor, as well as research assistance from Jaime Blancas are gratefully acknowledged. 2 economic growth. However, the crises made irruption in Mexico (1994-1995), Asia (1997- 1998), Russia, Brazil, and several other Latin American countries (1998-1999), and Argentina (2001-2002). These kinds of crises showed that there was something wrong in the so-called “emergent economies” under the new “market friendliness” environment. -
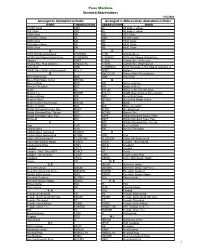
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Supplemental Information 1: System Assumptions
Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 1: System Assumptions Starting from the mass transfer equation: ∂C 2 + υ ⋅ ∇C = D∇ C + R ∂t (a) Distance between the droplet and air channels, O(10‐4) m is much smaller than the distance between the droplet channel PDMS device boundary O(10‐2) m, so little € mass transfer is out of the device and most mass transfer is into the air channel. (b) Assume the oil provides no resistance as compared to the PDMS. (c) Assume psuedo‐steady state since the PDMS boundaries and concentration boundary conditions are fixed: ∂C = 0 ∂t (d) No convection € υ = 0 (e) No reaction € R = 0 (f) Since the oil provides little resistance to mass transfer, the end of the droplets can be assumes as a constant value with surface area equal to the height of the droplet, h, multiplied by the width of the droplet (g) The concentration out the top is a function of the distance between droplet and air channels and will related to mass transfer out the sides for fixed droplet/air separations. This mass transfer can be represented by multiplying by an effective area. Therefore the system is simplified to one dimension. ∂ 2C = 0 ∂x 2 BC1 C(x = 0) = Csat,PDMS € Csat,PDMS BC2 C(x = d) = Cair = HCair Csat,air € (Csat,PDMS − HCair ) C = Csat,PDMS − x d € dC C − HC J = −D = D ( sat,PDMS air ) dx d € € Electronic Supplementary Material (ESI) for Lab on a Chip This journal is © The Royal Society of Chemistry 2011 Supplemental Information 2: Droplet Change This derivation and model is derived assuming an approximate rectangular block shaped droplet with constant fluxes (Jtop, Jend, Jside) out of each the top, the ends and the side of the drop (Atop, Aend, Aside) in Equation S1. -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10. -

Discourse Transcription
MNTA lBYABJMJB.A MPJEJB.S IN )LINGUISTICS VOLUrtlE 4: DISCOURSE TRANSCRIPTION JOHN W. DU BOIS, SUSANNA CUMMING STEPHAN SCHUETZE-COBURN, DANAE PAOLINO EDITORS DEPARTMENT OF LINGUISTICS UNIVERSITY OF CALIFORNIA, SANTA BARBARA 199:2 Papers in Linguistics Linguistics Department University of California, Santa Barbara Santa Barbara, California 93106-3100 U.S.A. Checks in U.S. dollars should be made out to UC Regents with $5.00 added for overseas postage. If your institution is interested in an exchange agreement, please write the above address for information. Volume 1: Korean: Papers and Discourse Date $13.00 Volume 2: Discourse and Grammar $10.00 Volume 3: Asian Discourse and Grammar $10.00 Volume 4: Discourse Transcription $15.00 Volume 5: East Asian Linguistics $15.00 Volume 6: Aspects of Nepali Grammar $15.00 Volume 7: Prosody, Grammar, and Discourse in Central Alaskan Yup'ik $15.00 Proceedings from the fIrst $20.00 Workshop on American Indigenous Languages Proceedings from the second $15.00 Workshop on American Indigenous Languages Proceedings from the third $15.00 Workshop on American Indigenous Languages Proceedings from the fourth $15.00 Workshop on American Indigenous Languages PART ONE: INTRODUCTION CHAPTER 1. INTRODUCTION 1 1.1 What is discourse transcription? . 1.2 The goal of discourse transcription . 1.3 Options . 1.4 How to use this book . CHAPTER 2. A GOOD RECORDING 9 2.1 Naturalness . 2.2 Sound . 2.3 Videotape . CHAPTER 3. GETTING STARTED 12 3.1 How to start transcribing . 3.2 Delicacy: Broad or narrow? . 3.3 Delicacy conventions in this book . PART TWO: TRANSCRIPTION CONVENTIONS CHAPTER 4. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Conversion Table a = 1 B = 2 C = 3 D = 4 E = 5 F = 6 G = 7 H = 8 I = 9 J = 10 K =11 L = 12 M = 13 N =14 O =15 P = 16 Q =17 R
Classroom Activity 2 Math 113 The Dating Game Introduction: Disclaimer: Although this is called the “Dating Game”, it is merely intended to help the student gain understanding of the concept of Standard Deviation. It is not intended to help students find dates. The day after Thanksgiving, 1996, I was driving my sister, Conversion Table brother-in-law, and sister-in-law over to meet my brother in A=1 K=11 U=21 Springfield at the Mission where he and his wife helped out. B=2 L=12 V=22 During this drive, I ask my sister, “How do you know which C=3 M=13 W=23 woman is the right one for you?”. Now, my sister was born D=4 N=14 X=24 a Jones, and like the rest of the family, she can make E=5 O=15 Y=25 anything sound believable. Without missing a beat, she F=6 P=16 Z=26 said, “You take the letters in her name, convert them to G=7 Q=17 numbers, find the standard deviation, and whoever’s H=8 R=18 standard deviation is closest to yours is the woman for you.” I=9S=19 I was so proud of my sister, that was a really good answer. J=10 T=20 Then, she followed it up with “Actually, if you can find a woman who knows what a standard deviation is, that’s the woman for you.” The first part was easy, take each letter in your name and convert it to a number. Use the system where an A=1, B=2, .. -

11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. Review Words Challenge Words
Spelling: Digraphs Name Fold back the paper 1. 1. thirty along the dotted line. 2. 2. width Use the blanks to write each word as it is read 3. 3. northern aloud. When you fi nish 4. 4. fi fth the test, unfold the paper. Use the list at 5. 5. choose the right to correct any 6. 6. touch spelling mistakes. 7. 7. chef 8. 8. chance 9. 9. pitcher 10. 10. kitchen 11. 11. sketched 12. 12. ketchup 13. 13. snatch 14. 14. stretching 15. 15. rush 16. 16. whine 17. 17. whirl 18. 18. bring 19. 19. graph 20. 20. photo Review Words 21. 21. unload Copyright © The McGraw-Hill Companies, Inc. 22. 22. relearn 23. 23. subway Challenge Words 24. 24. expression 25. 25. theater Phonics/Spelling • Grade 4 • Unit 2 • Week 2 37 Spelling: Digraphs Name thirty choose pitcher snatch whirl width touch kitchen stretching bring northern chef sketched rush graph fi fth chance ketchup whine photo A. Underline the spelling word in each row that rhymes with the word in bold type. Write the spelling word on the line. 1. much match touch luck 2. sting bring brag stint 3. fetching resting guessing stretching 4. pants stand lamp chance 5. dirty thirty forty wiry 6. shine mind whine lane 7. news loose stew choose 8. catch clutch snatch snake 9. laugh graph rough roof 10. fl ush crash rush puts Copyright © The McGraw-Hill Companies, Inc. 11. clef chef step leaf 12. etched skipped punched sketched 13. hurl hurt whirl while 14. richer pitcher sister listener B. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS