Discourse Transcription
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Marshall Mcluhan
Marshall McLuhan: Educational Implications* W.J. Gushue He received the Governor General's award for his work in literature, the Albert Schweitzer Chair at Fordham for his work in communications, and the Moison Award from the Canada Council as "explorer and interpreter of our age." He appeared on the covers of N eW8week, Saturday Review and Canada's largest weekend supplement. NBC made a one-hour docu mentary of his message and later repeated it, and the CBC gave him prime Sunday night viewing time on two occasions. He is one of the most publicized intellectuals of recent times. Ralph Thomas wrote in the Torfmto Star: "He has been explained, knocked and praised in just about every magazine in the EngIish, French, German and Italian languages." 1 As to newspaper coverage, which newspapers have not written about him? He has lectured city planners, advertising men, TV executives, university professors, students, and scientists; business men have sought his message from a yacht in the Aegean Sea, a hotel in the Laurentians, a former firehouse in San Francisco, and in the board rooms of IBM, General Electric, and Bell Telephone. Although "a torrent of criticism" has been heaped upon him by ':' Research for this paper was undertaken while Prof. Gushue was at the .ontario Institute for Studies in Education during the 1967-68 acad emic year. A slightly modified version was delivered at the C.A.P.E. conference in Calgary, June, 1968. - Ed. 3 4 Marshall McLuhan the old dogies of academe and the literary establishment, he has been eulogized in dozens of scholarly magazines and studied serious ly by thousands of intellectuals.2 The best indication of his worth is the fact that among his followers are to be found people (artists, really) who are part of what Susan Sontag calls "the new sensibility." 3 They are, to use Louis Kronenberger's phrase, "the symbol manipulators," the peo ple who are calling the shots - painters, sculptors, publishers, pub lic relations men, architects, film-makers, musicians, designers, consultants, editors, T.V. -

Roth Book Notes--Mcluhan.Pdf
Book Notes: Reading in the Time of Coronavirus By Jefferson Scholar-in-Residence Dr. Andrew Roth Mediated America Part Two: Who Was Marshall McLuhan & What Did He Say? McLuhan, Marshall. The Mechanical Bride: Folklore of Industrial Man. (New York: Vanguard Press, 1951). McLuhan, Marshall and Bruce R. Powers. The Global Village: Transformations in World Life and Media in the 21st Century. (New York: Oxford University Press, 1989). McLuhan, Marshall. The Gutenberg Galaxy: The Making of Typographic Man. (Toronto: University of Toronto Press, 1962). McLuhan, Marshall. Understanding Media: The Extensions of Man. (Cambridge, MA: MIT Press, 1994. Originally Published 1964). The Mechanical Bride: The Gutenberg Galaxy Understanding Media: The Folklore of Industrial Man by Marshall McLuhan Extensions of Man by Marshall by Marshall McLuhan McLuhan and Lewis H. Lapham Last week in Book Notes, we discussed Norman Mailer’s discovery in Superman Comes to the Supermarket of mediated America, that trifurcated world in which Americans live simultaneously in three realms, in three realities. One is based, more or less, in the physical world of nouns and verbs, which is to say people, other creatures, and things (objects) that either act or are acted upon. The second is a world of mental images lodged between people’s ears; and, third, and most importantly, the mediasphere. The mediascape is where the two worlds meet, filtering back and forth between each other sometimes in harmony but frequently in a dissonant clanging and clashing of competing images, of competing cultures, of competing realities. Two quick asides: First, it needs to be immediately said that Americans are not the first ever and certainly not the only 21st century denizens of multiple realities, as any glimpse of Japanese anime, Chinese Donghua, or British Cosplay Girls Facebook page will attest, but Americans first gave it full bloom with the “Hollywoodization,” the “Disneyfication” of just about anything, for when Mae West murmured, “Come up and see me some time,” she said more than she could have ever imagined. -

Music 1000 Songs, 2.8 Days, 5.90 GB
Music 1000 songs, 2.8 days, 5.90 GB Name Time Album Artist Drift And Die 4:25 Alternative Times Vol 25 Puddle Of Mudd Weapon Of Choice 2:49 Alternative Times Vol 82 Black Rebel Motorcycle Club You'll Be Under My Wheels 3:52 Always Outnumbered, Never Outg… The Prodigy 08. Green Day - Boulevard Of Bro… 4:20 American Idiot Green Day Courage 3:30 ANThology Alien Ant Farm Movies 3:15 ANThology Alien Ant Farm Flesh And Bone 4:28 ANThology Alien Ant Farm Whisper 3:25 ANThology Alien Ant Farm Summer 4:15 ANThology Alien Ant Farm Sticks And Stones 3:16 ANThology Alien Ant Farm Attitude 4:54 ANThology Alien Ant Farm Stranded 3:57 ANThology Alien Ant Farm Wish 3:21 ANThology Alien Ant Farm Calico 4:10 ANThology Alien Ant Farm Death Day 4:33 ANThology Alien Ant Farm Smooth Criminal 3:29 ANThology Alien Ant Farm Universe 9:07 ANThology Alien Ant Farm The Weapon They Fear 4:38 Antigone Heaven Shall Burn To Harvest The Storm 4:45 Antigone Heaven Shall Burn Tree Of Freedom 4:49 Antigone Heaven Shall Burn Voice Of The Voiceless 4:53 Antigone (Slipcase - Edition) Heaven Shall Burn Rain 4:11 Ascendancy Trivium laid to rest 3:49 ashes of the wake lamb of god Now You've Got Something to Die … 3:39 Ashes Of The Wake Lamb Of God Relax Your Mind 4:07 Bad Boys 2 Soundtrack Loon Intro 0:12 Bad Boys 2 Soundtrack Bad Boys 2 Soundtrack Show Me Your Soul 5:20 Bad Boys 2 Soundtrack Loon Feat. -

The Complexity of Richness: Media, Message, and Communication Outcomes
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by The University of North Carolina at Greensboro The complexity of richness: Media, message, and communication outcomes By: Robert F. Otondo, James R. Van Scotter, David G. Allen, Prashant Palvia Otondo, R.F., Van Scotter, J.R., Allen, D.G., and Palvia, P. ―The Complexity of Richness: Media, Message, and Communication Outcomes.‖ Information & Management. Vol. 40, 2008, pp. 21-30. Made available courtesy of Elsevier: http://www.elsevier.com ***Reprinted with permission. No further reproduction is authorized without written permission from Elsevier. This version of the document is not the version of record. Figures and/or pictures may be missing from this format of the document.*** Abstract: Dynamic web-based multimedia communication has been increasingly used in organizations, necessitating a better understanding of how it affects their outcomes. We investigated factor structures and relationships involving media and information richness and communication outcomes using an experimental design. We found that these multimedia contexts were best explained by models with multiple fine-grained constructs rather than those based on one- or two-dimensions. Also, media richness theory poorly predicted relationships involving these constructs. Keywords: Media richness theory; Information richness; Communication theory Article: 1. Introduction Investigation of relationships between the media and communication effectiveness has not provided consistent results. However, lack of understanding has not deterred organizations from investing heavily in new and dynamic forms of web-based multimedia for their marketing, public relations, training, and recruiting activities. Few studies have examined the effects of media channels and informational content on decision-making and other organizational outcomes. -

Financial Fragility and Neoliberalism in Developing Countries
Financial Fragility and Neoliberalism in Developing Countries Andrés Blancas• Abstract The aim of this paper is to show the financial fragility dynamics in developing countries following the last theoretical advances. As an empirical application we prove that the Mexican economy has been characterized by financial fragility, mainly during the crisis terms. Financial fragility has created difficult problems for policy makers; in trying to fix it by restricted monetary and fiscal policies, they have triggered the generalized financial crises. Whereby, financial fragility can be diagnosed as an structural problem of developing countries like Mexico and a real potential risk of generalized economic crisis in the process of economic liberalization nowadays. Key Words: Economic dynamics, financial fragility, developing countries, financial crisis, monetary policy and Mexican economy JEL Classification: C61, E44, E58, F34, O5 1 Introduction The 1990s financial crises in developing and newly industrializing countries exemplify the risk of financial volatility and economic instability that has accompanied the economic liberalization and the deregulation of financial markets. For these countries, particularly in Asia and Latin America, the first part of the 1990s was distinguished by hopeful and cheerful • Institute of Economic Research, UNAM. 2007 E-mail address: [email protected]. Telephone number: (525)55623-0125, FAX number: (525)55623-0199. Helpful comments and suggestions from Duncan Foley and Lance Taylor, as well as research assistance from Jaime Blancas are gratefully acknowledged. 2 economic growth. However, the crises made irruption in Mexico (1994-1995), Asia (1997- 1998), Russia, Brazil, and several other Latin American countries (1998-1999), and Argentina (2001-2002). These kinds of crises showed that there was something wrong in the so-called “emergent economies” under the new “market friendliness” environment. -
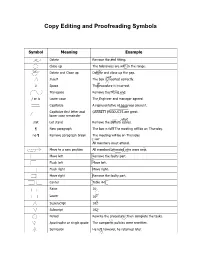
Copy Editing and Proofreading Symbols
Copy Editing and Proofreading Symbols Symbol Meaning Example Delete Remove the end fitting. Close up The tolerances are with in the range. Delete and Close up Deltete and close up the gap. not Insert The box is inserted correctly. # # Space Theprocedure is incorrect. Transpose Remove the fitting end. / or lc Lower case The Engineer and manager agreed. Capitalize A representative of nasa was present. Capitalize first letter and GARRETT PRODUCTS are great. lower case remainder stet stet Let stand Remove the battery cables. ¶ New paragraph The box is full. The meeting will be on Thursday. no ¶ Remove paragraph break The meeting will be on Thursday. no All members must attend. Move to a new position All members attended who were new. Move left Remove the faulty part. Flush left Move left. Flush right Move right. Move right Remove the faulty part. Center Table 4-1 Raise 162 Lower 162 Superscript 162 Subscript 162 . Period Rewrite the procedure. Then complete the tasks. ‘ ‘ Apostrophe or single quote The companys policies were rewritten. ; Semicolon He left however, he returned later. ; Symbol Meaning Example Colon There were three items nuts, bolts, and screws. : : , Comma Apply pressure to the first second and third bolts. , , -| Hyphen A valuable byproduct was created. sp Spell out The info was incorrect. sp Abbreviate The part was twelve feet long. || or = Align Personnel Facilities Equipment __________ Underscore The part was listed under Electrical. Run in with previous line He rewrote the pages and went home. Em dash It was the beginning so I thought. En dash The value is 120 408. -

(1) Communication Process
Communication Process (1) The Communication Process Scholars have developed theories to Theories of how we explain how we communicate with each communicate: The other. Linear and Most of these theories are variations on Transactional two generally recognized models — the models Linear model and the Transactional model. Communication Process (2) Communication Process (3) This ancient cave First, let’s define what communication is. painting speaks to us across time through its Communication is symbolic human ability to symbolize. behavior systematized into written, In its representations of verbal, and nonverbal codes. the male figure, the bison, and the rhino, we Click here to learn more about this recognize a 40,000 ancient painting. year-old story of human experience — the hunt. 1 Communication Process (4) Communication Process (5) Symbols can tell us . When we systematize symbols, we create codes for communication. Here are different ways for symbolizing the letter “A.” . what to do. what not to do. where to get help. how to stay safe. Any person, place, thing, feeling, or idea can be symbolized. Communication Process (6) Communication Process (7) Now that you understand the symbolic nature Those who want to communicate must share the same symbol system. of communication, let’s return to the two models of communication mentioned earlier. A model is a representation used to show how individual parts work together to accomplish a specific purpose — in this case communication. 2 Linear Model of Linear Model of Communication (1) Communication (2) Linear model includes A source A message A channel Message Channel A receiver Views communication as a straight line, one The linear model is now way event, in which the process reverses Encodes regarded as being incomplete. -

Rethinking Media Richness: Towards a Theory of Media Synchronicity
Proceedings of the 32nd Hawaii International Conference on System Sciences - 1999 Proceedings of the 32nd Hawaii International Conference on System Sciences - 1999 Rethinking Media Richness: Towards a Theory of Media Synchronicity Alan R. Dennis Joseph S. Valacich Terry College of Business College of Business and Economics University of Georgia, Athens, GA 30602 Washington State University, Pullman WA 99164 [email protected] [email protected] Abstract compensate for the weak findings and draw new This paper describes a new theory called a theory of conclusions based on the enhancements, or should we media synchronicity which proposes that a set of five attempt formulate a new theory [e.g., 34, 35, 41]? media capabilities are important to group work, and that In this paper, we take the second approach. We all tasks are composed of two fundamental communi- propose a new theory, which we call a theory of media cation processes (conveyance and convergence). synchronicity. The theory proposes that group Communication effectiveness is influenced by matching communication processes, regardless of task outcome the media capabilities to the needs of the fundamental objectives, are composed of two primary processes, communication processes, not aggregate collections of conveyance and convergence. The theory also proposes these processes (i.e., tasks) as proposed by media that media have a set of capabilities that play a dominant richness theory. The theory also proposes that the role when addressing each type of communication relationships between communication processes and process. Performance will be enhanced when media media capabilities will vary between established and capabilities are aligned with these processes. -

8123 Songs, 21 Days, 63.83 GB
Page 1 of 247 Music 8123 songs, 21 days, 63.83 GB Name Artist The A Team Ed Sheeran A-List (Radio Edit) XMIXR Sisqo feat. Waka Flocka Flame A.D.I.D.A.S. (Clean Edit) Killer Mike ft Big Boi Aaroma (Bonus Version) Pru About A Girl The Academy Is... About The Money (Radio Edit) XMIXR T.I. feat. Young Thug About The Money (Remix) (Radio Edit) XMIXR T.I. feat. Young Thug, Lil Wayne & Jeezy About Us [Pop Edit] Brooke Hogan ft. Paul Wall Absolute Zero (Radio Edit) XMIXR Stone Sour Absolutely (Story Of A Girl) Ninedays Absolution Calling (Radio Edit) XMIXR Incubus Acapella Karmin Acapella Kelis Acapella (Radio Edit) XMIXR Karmin Accidentally in Love Counting Crows According To You (Top 40 Edit) Orianthi Act Right (Promo Only Clean Edit) Yo Gotti Feat. Young Jeezy & YG Act Right (Radio Edit) XMIXR Yo Gotti ft Jeezy & YG Actin Crazy (Radio Edit) XMIXR Action Bronson Actin' Up (Clean) Wale & Meek Mill f./French Montana Actin' Up (Radio Edit) XMIXR Wale & Meek Mill ft French Montana Action Man Hafdís Huld Addicted Ace Young Addicted Enrique Iglsias Addicted Saving abel Addicted Simple Plan Addicted To Bass Puretone Addicted To Pain (Radio Edit) XMIXR Alter Bridge Addicted To You (Radio Edit) XMIXR Avicii Addiction Ryan Leslie Feat. Cassie & Fabolous Music Page 2 of 247 Name Artist Addresses (Radio Edit) XMIXR T.I. Adore You (Radio Edit) XMIXR Miley Cyrus Adorn Miguel Adorn Miguel Adorn (Radio Edit) XMIXR Miguel Adorn (Remix) Miguel f./Wiz Khalifa Adorn (Remix) (Radio Edit) XMIXR Miguel ft Wiz Khalifa Adrenaline (Radio Edit) XMIXR Shinedown Adrienne Calling, The Adult Swim (Radio Edit) XMIXR DJ Spinking feat. -

Singing Songs in Sign of Basketball Students Studying American Sign Language Perform Popular Songs in the EMU Arena Faces New Hurdle
Track Student Film River Float Ducks headed to NCAA Theater student Dusty Your guide to the best TODAY Championships in Iowa Bodeen premieres his first way to float the river Showers next week. PAGE 9 film “Phoned.” PAGE 5 this summer. PAGE 5 59°/48° The independent student newspaper at the University of Oregon dailyemerald.com SINCE 1900 | Volume 109, Issue 176 | Thursday, June 5, 2008 Construction Singing songs in sign of basketball Students studying American Sign Language perform popular songs in the EMU arena faces new hurdle A city official ruled in favor of neighbors, requiring the University to have a conditional use permit RYAN KNUTSON News Reporter The University’s arena project hit a big hurdle on Wednesday when a hearings official ruled the development must have a conditional use permit before construction can begin — a decision that complicates the project and could delay it months. The decision overturned a ruling by City Planning Director Lisa Gardner, and it serves as vindication for the neighbors who have bat- tled to have more say in the arena project since the site was first targeted in 2003. “This should have been a conditional use permit process from day one,” said Jeff Nelson, former co-chair of the Fairmount Neighborhood Association. Nelson currently serves on the neighborhood association’s are- na subcommittee. If it had been, “we would have had all these issues resolved by now.” It’s unclear whether the ruling will turn to ARENA, page 8 JAROD OPPERMAN | Photo Editor Rob Mason and Jordan Shively finish signing Johnny Cash’s “Cocaine Blues” in the Ben Linder Room Wednesday morning. -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Daryl Lowery Sample Songlist Bridal Songs
DARYL LOWERY SAMPLE SONGLIST BRIDAL SONGS Song Title Artist/Group Always And Forever Heatwave All My Life K-Ci & Jo JO Amazed Lonestar At Last Etta James Because You Loved Me Celine Dion Breathe Faith Hill Can't Help Falling In Love Elvis Presley Come Away With Me Nora Jones Could I Have This Dance Anne Murray Endless Love Lionel Ritchie & Diana Ross (Everything I Do) I Do It For You Bryan Adams From This Moment On Shania Twain & Brian White Have I Told You Lately Rod Stewart Here And Now Luther Van Dross Here, There And Everywhere Beatles I Could Not Ask For More Edwin McCain I Cross My Heart George Strait I Do (Cherish You) 98 Degrees I Don't Want To Miss A Thing Aerosmith I Knew I Loved You Savage Garden I'll Always Love You Taylor Dane In Your Eyes Peter Gabriel Just The Way You Are Billy Joel Keeper Of The Stars Tracy Byrd Making Memories Of Us Keith Urban More Than Words Extreme One Wish Ray J Open Arms Journey Ribbon In The Sky Stevie Wonder Someone Like You Van Morrison Thank You Dido That's Amore Dean Martin The Way You Look Tonight Frank Sinatra The Wind Beneath My Wings Bette Midler Unchained Melody Righteous Brothers What A Wonderful World Louis Armstrong When A Man Loves A Woman Percy Sledge Wonderful Tonight Eric Clapton You And Me Lifehouse You're The Inspiration Chicago Your Song Elton John MOTHER/SON DANCE Song Title Artist/Group A Song For Mama Boyz II Men A Song For My Son Mikki Viereck You Raise Me Up Josh Groban Wind Beneath My Wings Bette Midler FATHER/DAUGHTER DANCE Song Title Artist/Group Because You Loved Me Celine Dion Butterfly Kisses Bob Carlisle Daddy's Little Girl Mills Brothers Unforgettable Nat & Natalie King Cole What A Wonderful World Louis Armstrong Popular Selections: "Big Band” To "Hip Hop" Song Title Artist/Group (Oh What A Night) December 1963 Four Seasons 100% Pure Love Crystal Waters 1985 Bowling For Soup 1999 Prince 21 Questions 50 Cent 867-5309 Tommy Tutone A New Day Has Come Celine Dion A Song For My Son Mikki Viereck A Thousand Years Christine Perri A Wink And A Smile Harry Connick, Jr.